W&B Report and Workspace API는 공개 프리뷰 상태입니다.
사용자 지정된 저장 워크스페이스 뷰를 만드는 엔드 투 엔드 튜토리얼을 보려면 Programmatic workspaces notebook을 실행하세요.
리포트를 프로그래밍 방식으로 편집하려면 W&B Python SDK와 함께 W&B Report and Workspace API (
wandb-workspaces)를 설치해야 합니다:플롯 추가
- App UI
- Report and Workspace API
리포트에서 슬래시(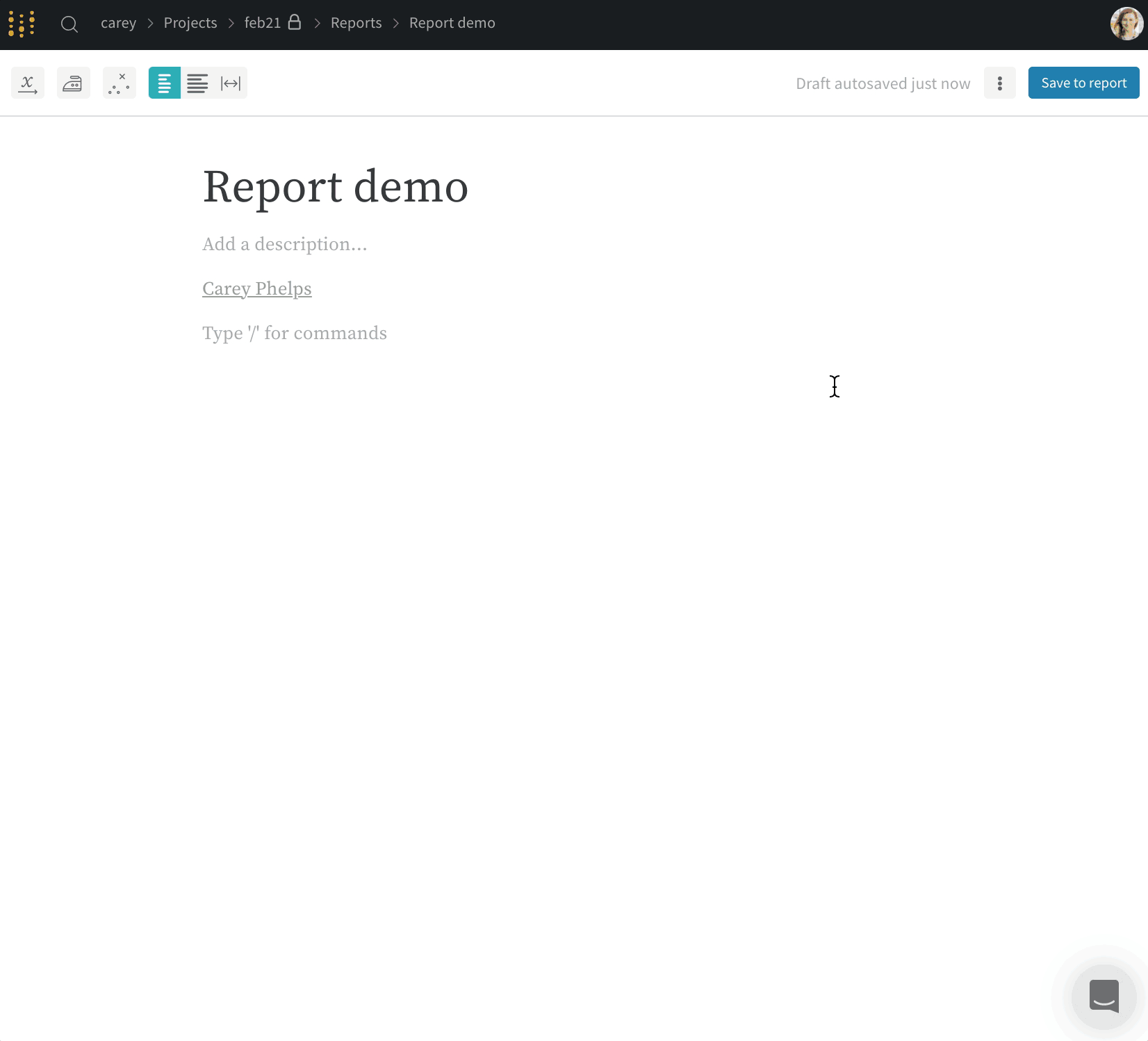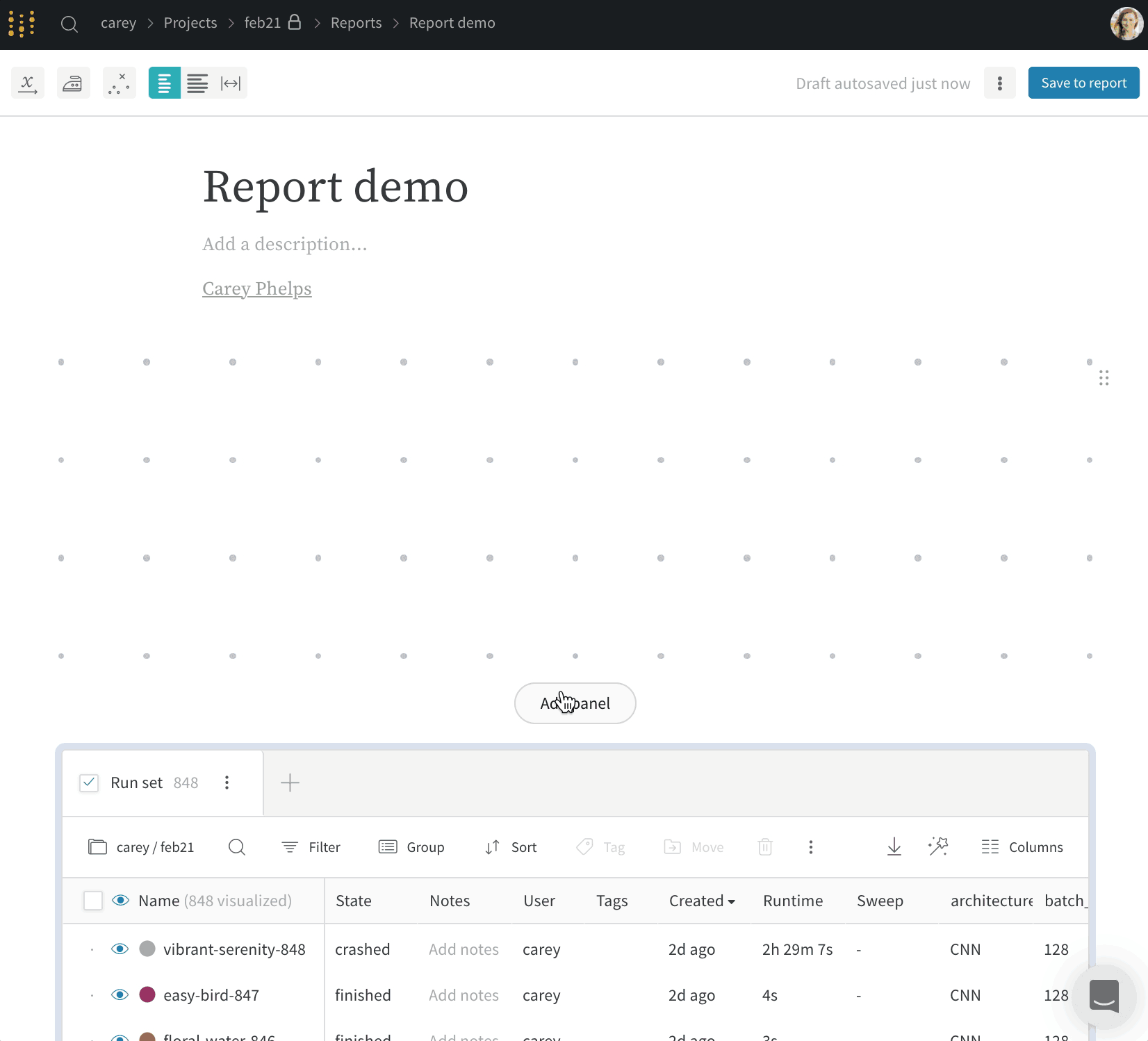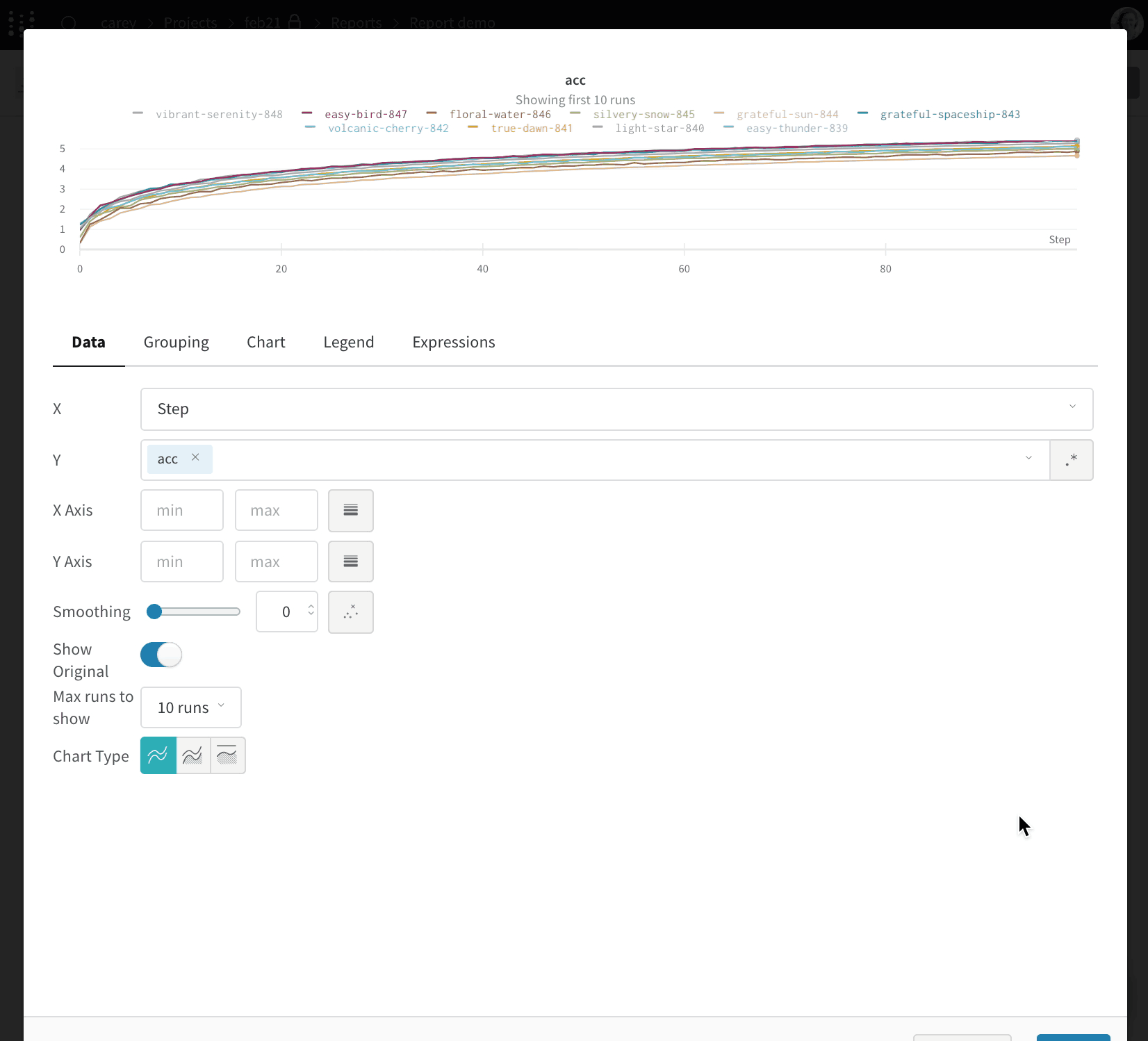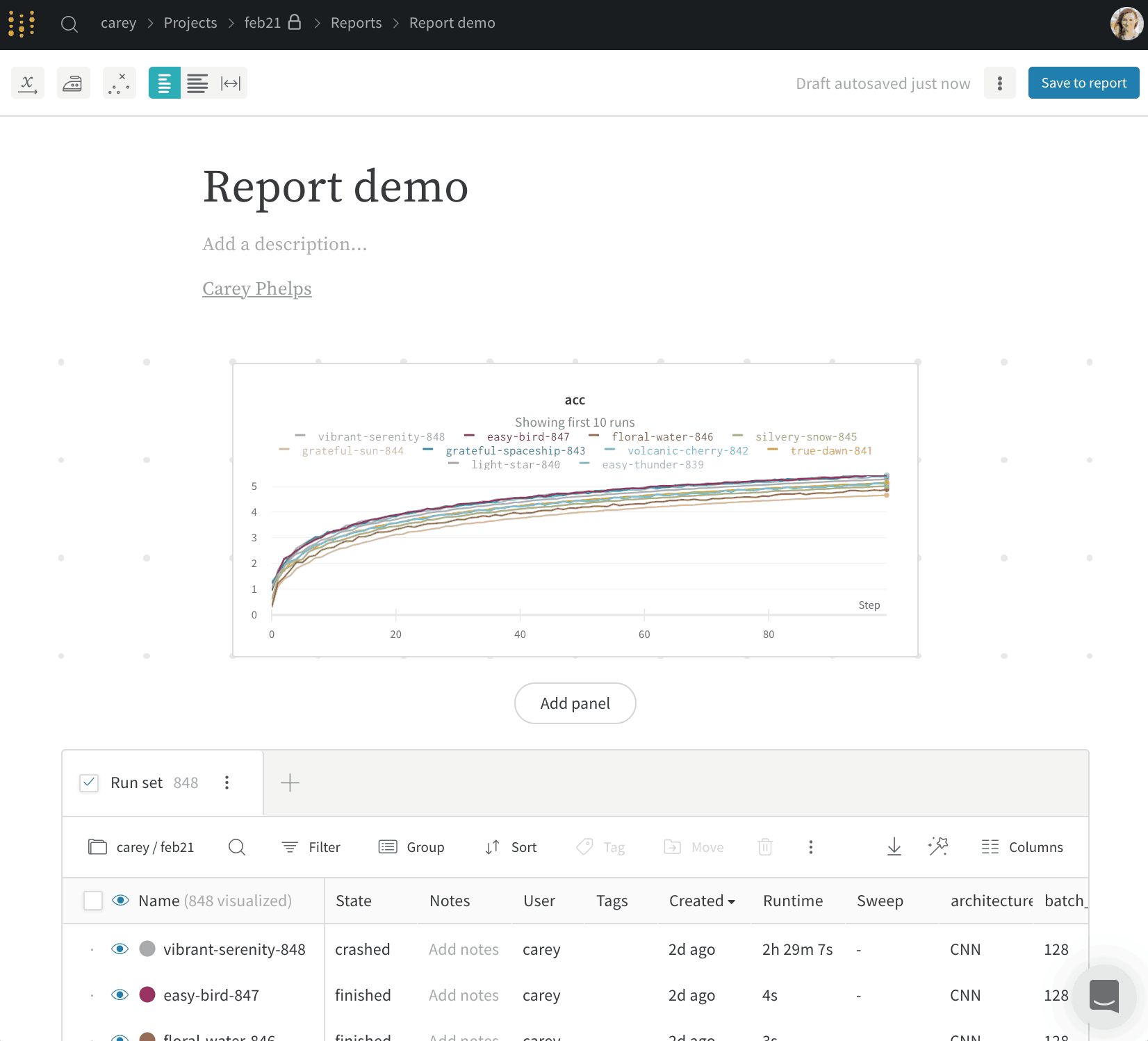
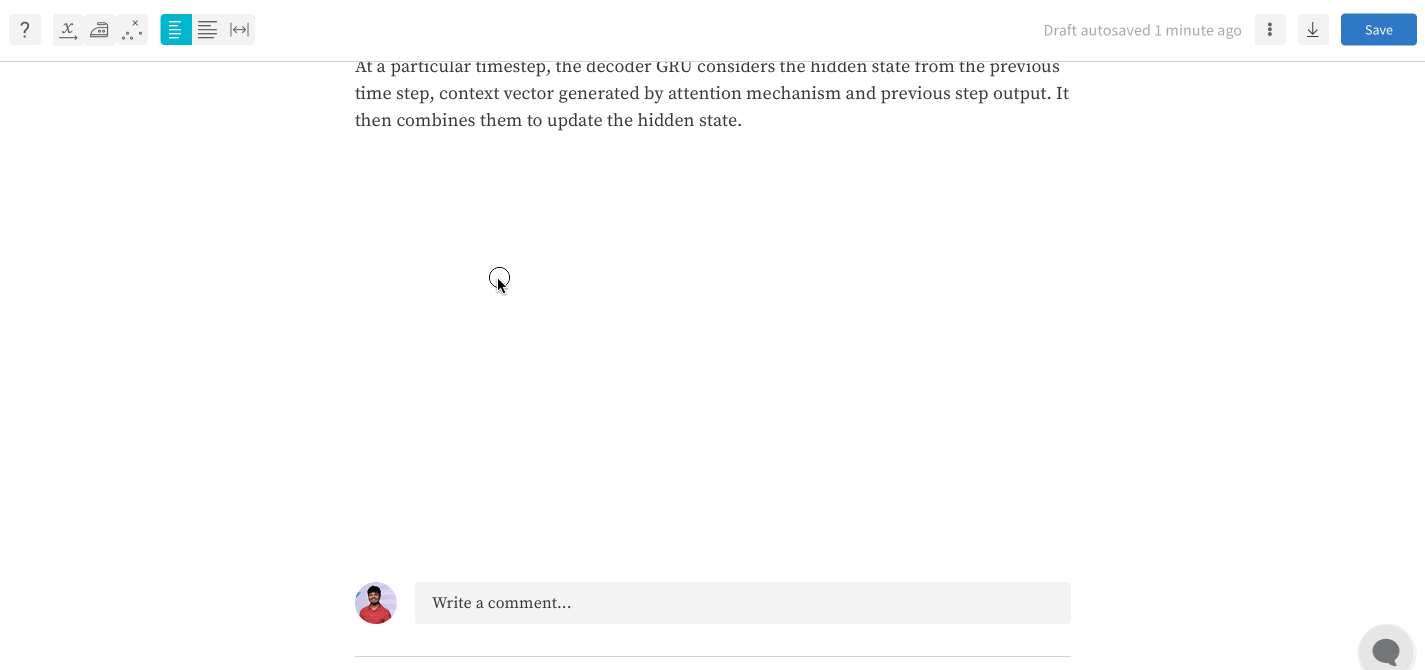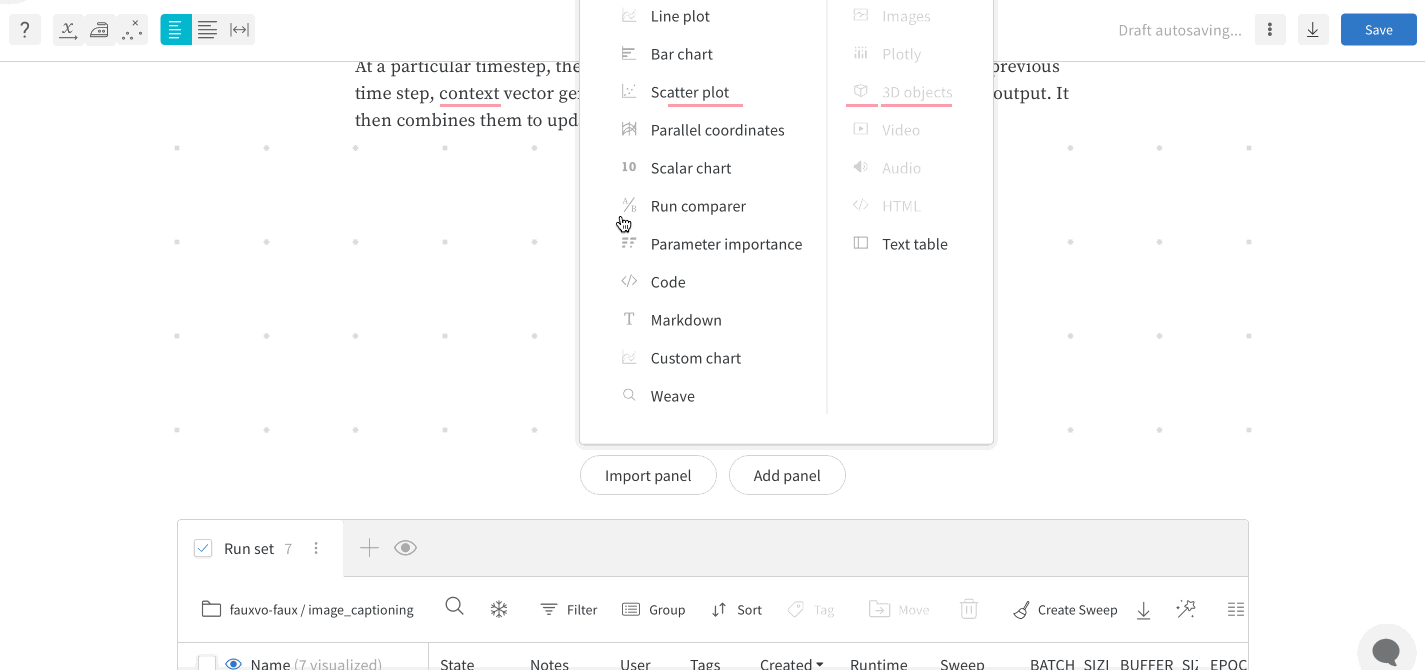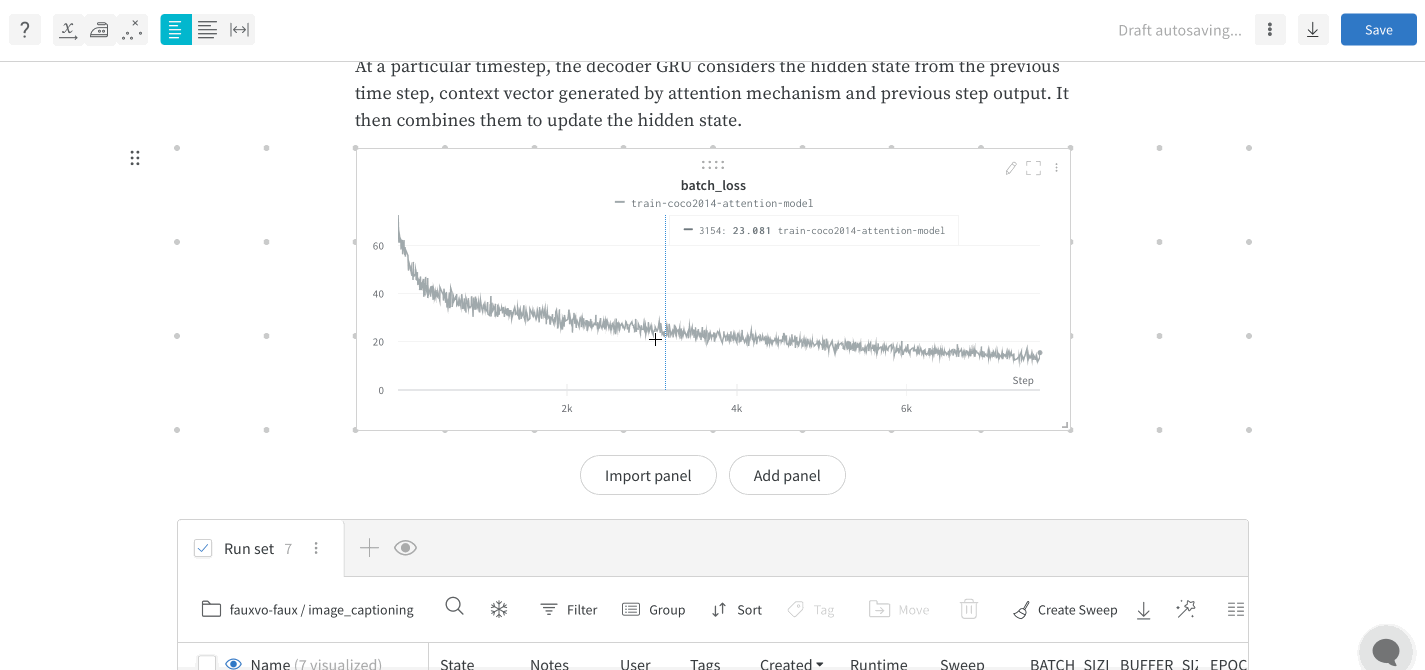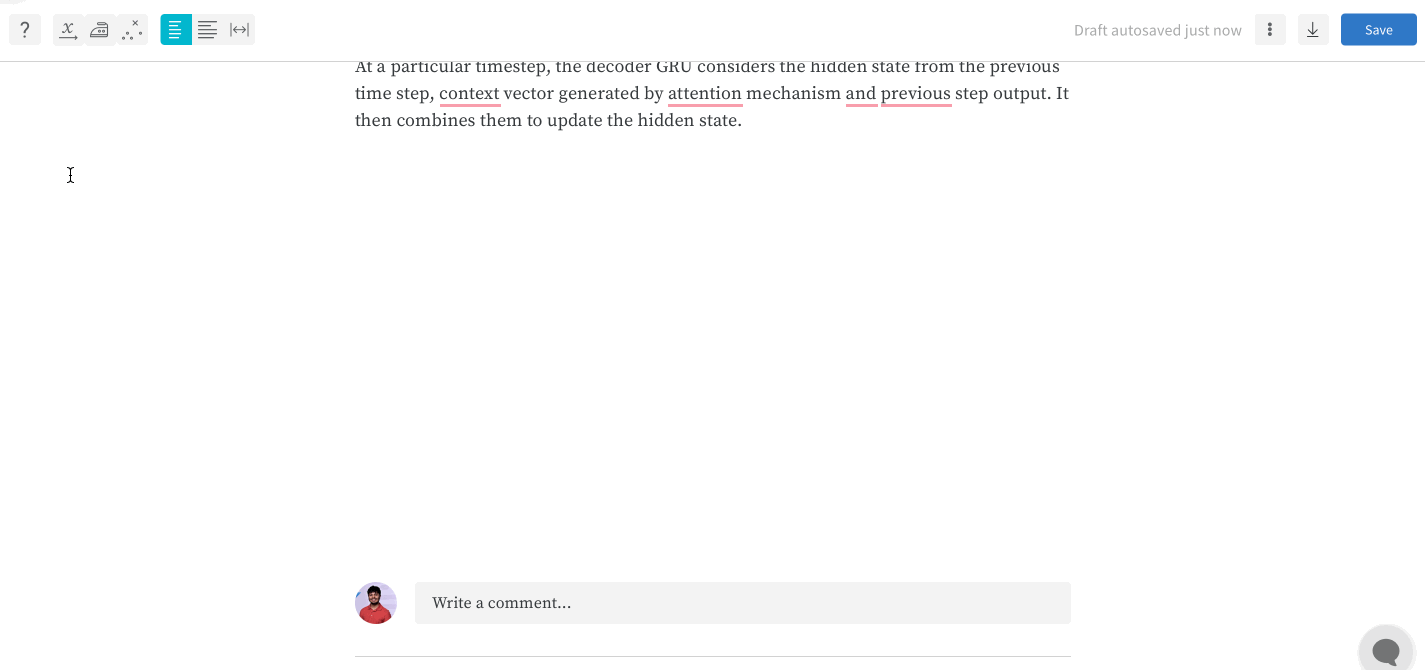
/)를 입력하면 드롭다운 메뉴가 표시됩니다. 패널을 추가하려면 Add panel을 선택합니다. 라인 플롯(line plot), 산점도(scatter plot), 평행 좌표(parallel coordinates) 차트 등 W&B에서 지원하는 모든 패널을 추가할 수 있습니다.run 세트 추가
- App UI
- Report and Workspace API
리포트에서 슬래시(
/)를 입력하면 드롭다운 메뉴가 표시됩니다. 드롭다운에서 Panel Grid를 선택합니다. W&B가 리포트가 생성된 프로젝트의 run 세트를 자동으로 가져옵니다.패널을 리포트에 가져오면 리포트는 프로젝트의 run 이름을 상속합니다. 리포트에서 독자가 더 잘 이해할 수 있도록 필요하다면 run 이름 바꾸기를 할 수 있습니다. 이 이름 변경은 해당 개별 패널에만 적용됩니다. 동일한 리포트에서 패널을 복제하면, 복제된 패널에도 새 이름이 반영됩니다.- 리포트에서 연필 아이콘을 클릭해 리포트 편집기를 엽니다.
-
run 세트에서 이름을 변경할 run을 찾습니다. run 이름 위에 마우스를 올린 다음 액션 () 메뉴를 클릭합니다. 다음 선택지 중 하나를 선택한 뒤, 폼을 제출합니다.
- Rename run for project: 전체 프로젝트에 걸쳐 run 이름을 변경합니다. 새 임의 이름을 생성하려면 필드를 비워 둡니다.
- Rename run for panel grid: 다른 컨텍스트에서 기존 이름은 유지한 채, 이 리포트에서만 run 이름을 변경합니다. 이 옵션으로는 새 임의 이름을 생성할 수 없습니다.
- Publish report를 클릭합니다.
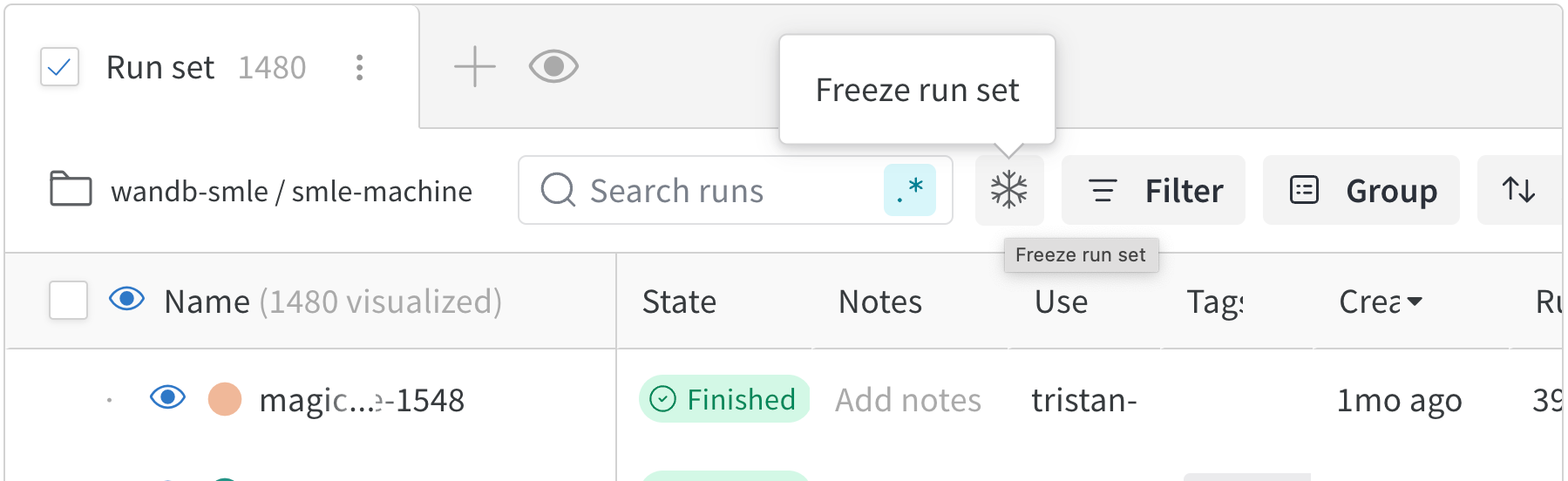
run 세트 고정하기
run 세트를 프로그래밍 방식으로 그룹화하기
| Grouping method | Description | Available keys |
|---|---|---|
| Config values | 설정 값으로 run을 그룹화 | wandb.init(config=)의 config 파라미터에 지정한 값 |
| Run metadata | run 메타데이터로 run을 그룹화 | State, Name, JobType |
| Summary metrics | summary 메트릭으로 run을 그룹화 | wandb.Run.log()으로 run에 기록하는 값 |
설정 값으로 run 그룹화하기
(wandb.init(config=)) 에서 지정하는 파라미터이다. run을 설정 값으로 그룹화하려면 config.[KEY] 문법을 사용한다. 여기서 [KEY] 는 그룹화에 사용할 설정 값의 이름이다.
예를 들어, 다음 코드 스니펫은 먼저 group 에 대한 설정 값을 사용해 run을 초기화한 다음, 리포트에서 group 설정 값을 기준으로 run을 그룹화한다. [ENTITY] 와 [PROJECT] 값은 자신의 W&B entity 및 프로젝트 이름으로 교체한다.
config.group 값을 기준으로 run을 그룹화할 수 있습니다:
run 메타데이터별로 Runs 그룹화하기
Name), 상태(State), 또는 job 유형(JobType)별로 Runs를 그룹화할 수 있습니다.
이전 예시에서 이어서, 다음 코드 스니펫을 사용해 Runs를 이름 기준으로 그룹화할 수 있습니다:
run의 이름은
wandb.init(name=) 파라미터에 지정한 이름입니다. 이름을 지정하지 않으면, W&B가 해당 run에 대해 임의의 이름을 생성합니다.run의 이름은 W&B App에서 해당 run의 Overview 페이지에서 확인하거나, Api.runs().run.name을 사용해 프로그램 코드에서 확인할 수 있습니다.summary 메트릭으로 runs 그룹화하기
wandb.Run.log()를 사용해 run에 로그로 기록하는 값입니다. run을 기록한 후에는 W&B App에서 해당 run의 Overview 페이지에 있는 Summary 섹션에서 summary 메트릭의 이름을 확인할 수 있습니다.
summary 메트릭으로 runs를 그룹화하는 구문은 summary.[KEY]이며, 여기서 [KEY]는 그룹화에 사용할 summary 메트릭의 이름입니다.
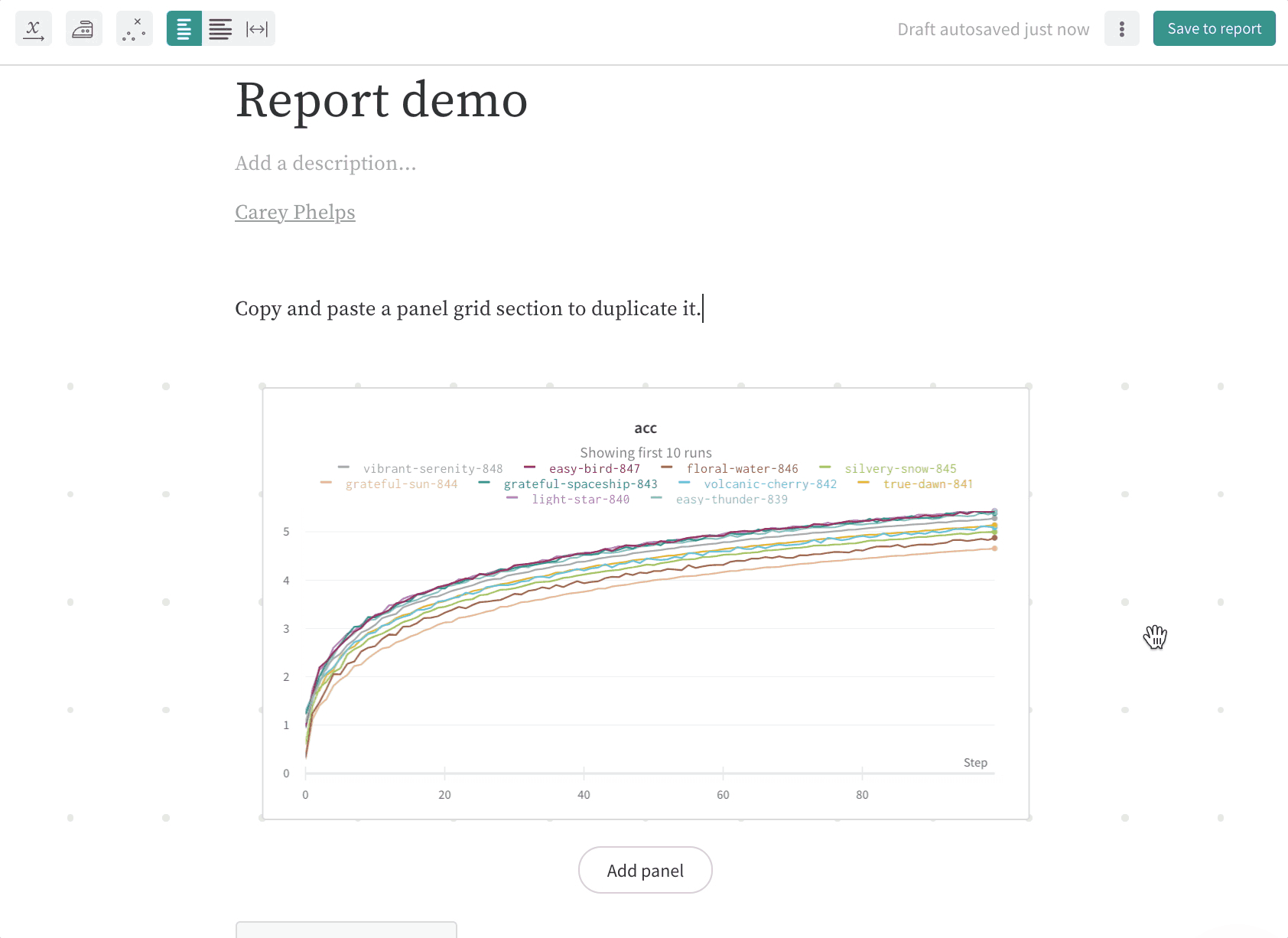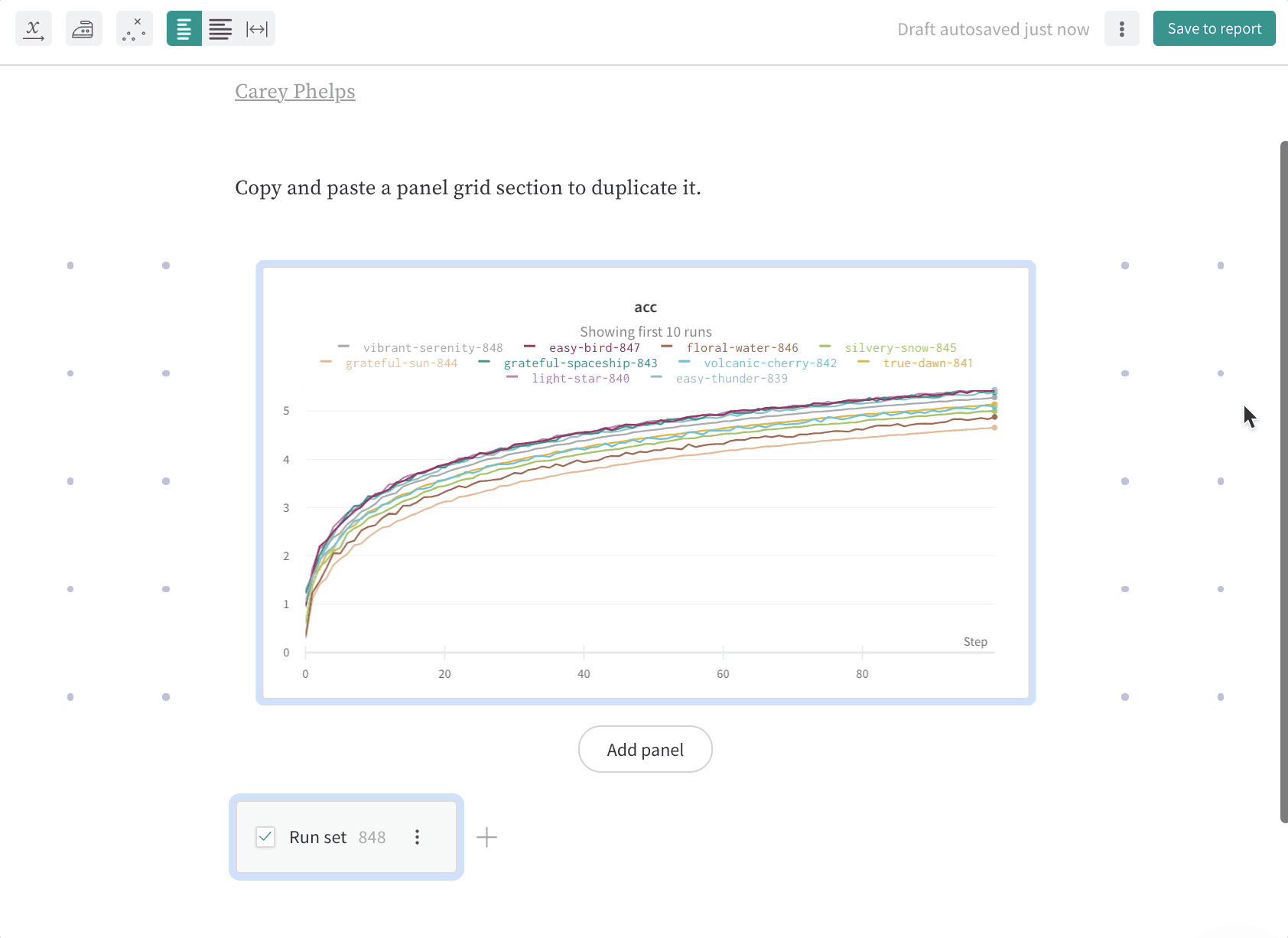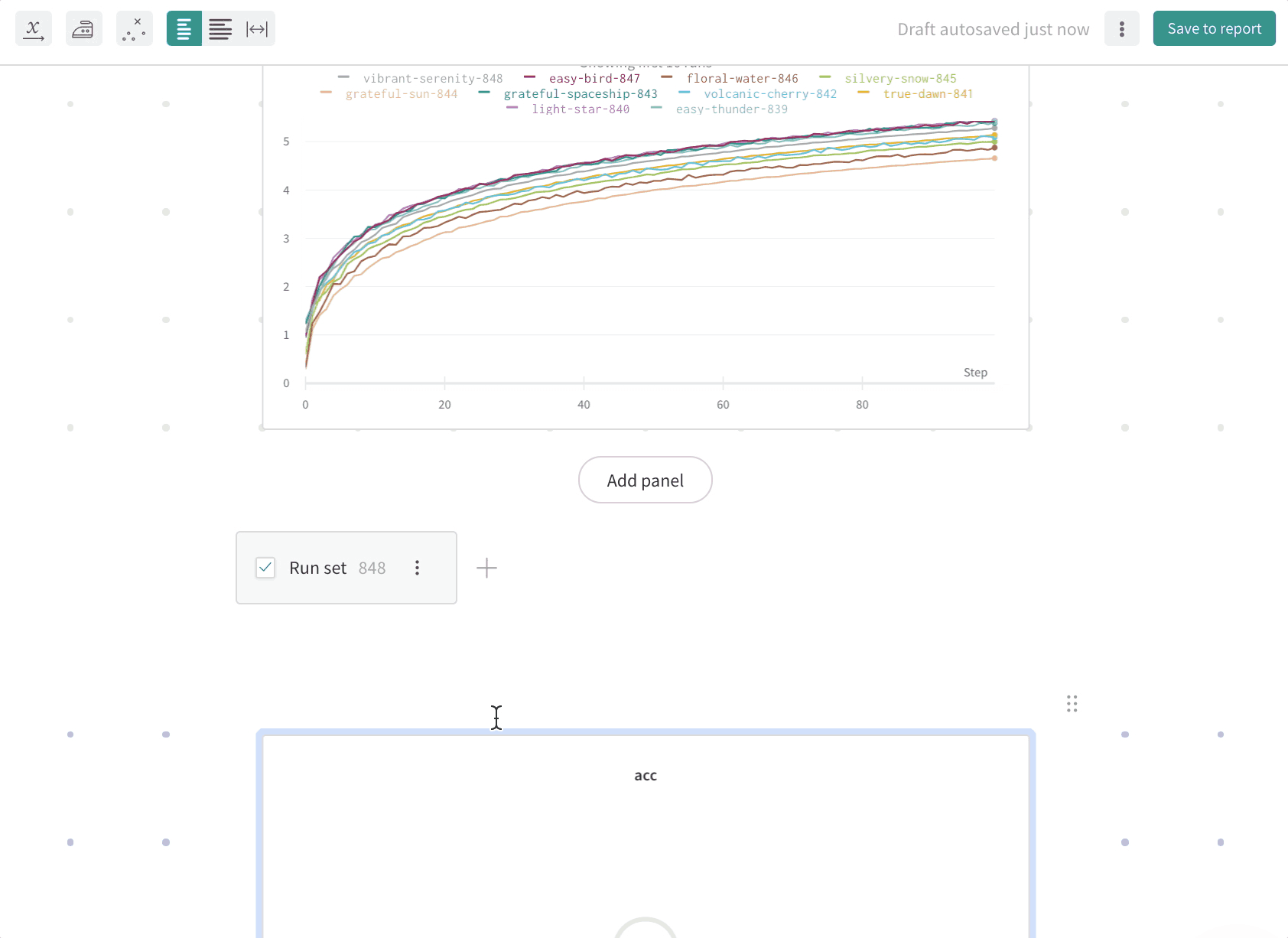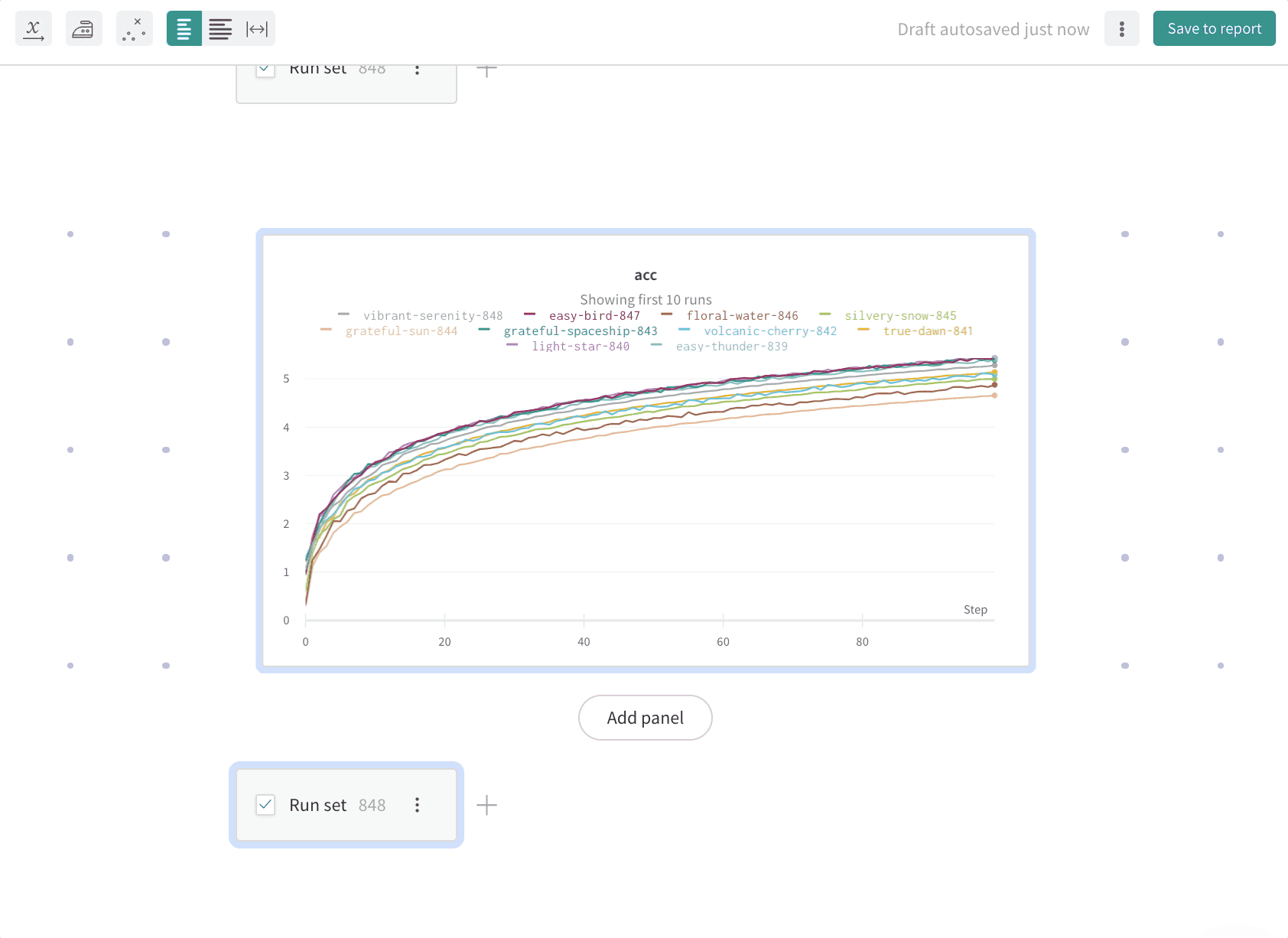
예를 들어, acc라는 이름의 summary 메트릭을 기록한다고 가정해 보겠습니다. [ENTITY] 및 [PROJECT]를 사용 중인 W&B entity 및 프로젝트 이름으로 바꾸세요:
summary.acc summary 메트릭을 기준으로 run을 그룹화할 수 있습니다:
프로그래밍 방식으로 run 세트 필터링하기
[KEY]는 필터 이름이고, operation은 비교 연산자(예: >, <, ==, in, not in, or, and)이며, [VALUE]는 비교 대상 값입니다. Filter는 적용하려는 필터 유형을 나타내는 자리 표시자입니다. 다음 표에는 사용 가능한 필터와 해당 설명이 나와 있습니다.
| Filter | 설명 | 사용 가능한 키 |
|---|---|---|
Config('[KEY]') | 설정 값으로 필터링 | wandb.init(config=)의 config 매개변수에 지정한 값입니다. |
SummaryMetric('[KEY]') | summary 메트릭으로 필터링 | wandb.Run.log()를 사용해 run에 기록한 값입니다. |
Tags('[KEY]') | tags로 필터링 | run에 추가한 태그 값입니다(프로그래밍 방식 또는 W&B App 사용). |
Metric('[KEY]') | run 속성으로 필터링 | tags, state, displayName, jobType |
wr.PanelGrid(runsets=)에 전달할 수 있습니다. report에 여러 요소를 프로그래밍 방식으로 추가하는 방법에 대한 자세한 내용은 이 페이지 전반의 Report and Workspace API 탭을 참조하세요.
다음 예시는 report에서 run 세트를 필터링하는 방법을 보여줍니다. 대괄호로 묶인 값(예: [ENTITY] 및 [PROJECT])은 실제 값으로 바꾸세요.
설정 필터
wandb.init(config=))에서 지정하는 파라미터입니다.
예를 들어, 다음 코드 스니펫에서는 먼저 learning_rate와 batch_size 설정 값으로 run을 초기화한 다음, 리포트에서 learning_rate 설정 값을 기준으로 Runs를 필터링합니다.
0.01보다 큰 run만 코드로 필터링할 수 있습니다.
and 연산자를 사용하여 여러 config 값을 기준으로 필터링할 수도 있습니다:
메트릭 필터
tags), run 상태(state), run 이름(displayName), 또는 job 타입(jobType)을 기준으로 필터링한다.
Metric 필터는 다른 필터와 다른 구문을 사용한다. 값은 반드시 리스트로 전달해야 한다.run1, run2, run3인 run만 필터링하려면 다음 코드를 사용할 수 있습니다:
run의 이름은 W&B App에서 해당 run의 Overview 페이지에서 확인하거나, 프로그래밍 방식으로
Api.runs().run.name을 사용해 가져올 수 있습니다.finished, crashed, 또는 running)에 따라 run 세트를 필터링하는 방법을 보여줍니다:
SummaryMetric 필터
wandb.Run.log()을 사용해 run에 기록한 값이다. run을 로깅한 후에는 W&B App에서 해당 run의 Overview 페이지에 있는 Summary 섹션에서 Summary 메트릭의 이름을 확인할 수 있다.
코드 블록 추가
- App UI
- Report and Workspace API
리포트에서 슬래시(
/)를 입력하면 드롭다운 메뉴가 표시됩니다. 드롭다운에서 Code를 선택합니다.코드 블록에서 프로그래밍 언어 이름을 선택하면 드롭다운이 펼쳐집니다. 이 드롭다운에서 사용할 프로그래밍 언어 구문을 선택합니다. JavaScript, Python, CSS, JSON, HTML, Markdown, YAML 중에서 선택할 수 있습니다.마크다운 추가
- App UI
- Report and Workspace API
리포트에서 슬래시(
/)를 입력하면 드롭다운 메뉴가 표시됩니다. 드롭다운에서 Markdown을 선택합니다.
HTML 요소 추가
- App UI
- Report and Workspace API
리포트에서 슬래시(
/)를 입력하면 드롭다운 메뉴가 표시됩니다. 드롭다운에서 텍스트 블록 유형을 선택합니다. 예를 들어 H2 헤딩 블록을 만들려면 Heading 2 옵션을 선택합니다.
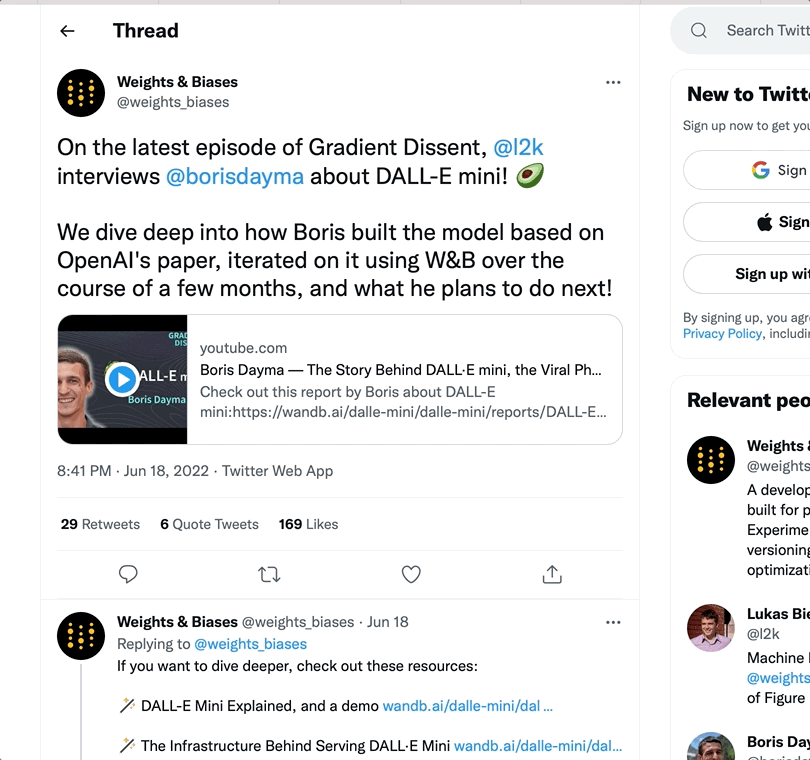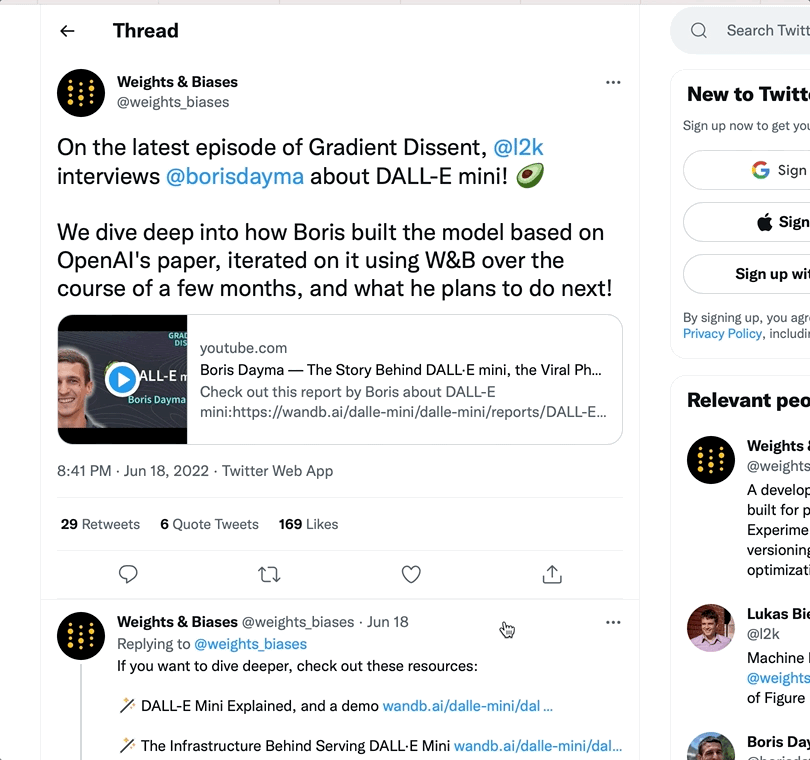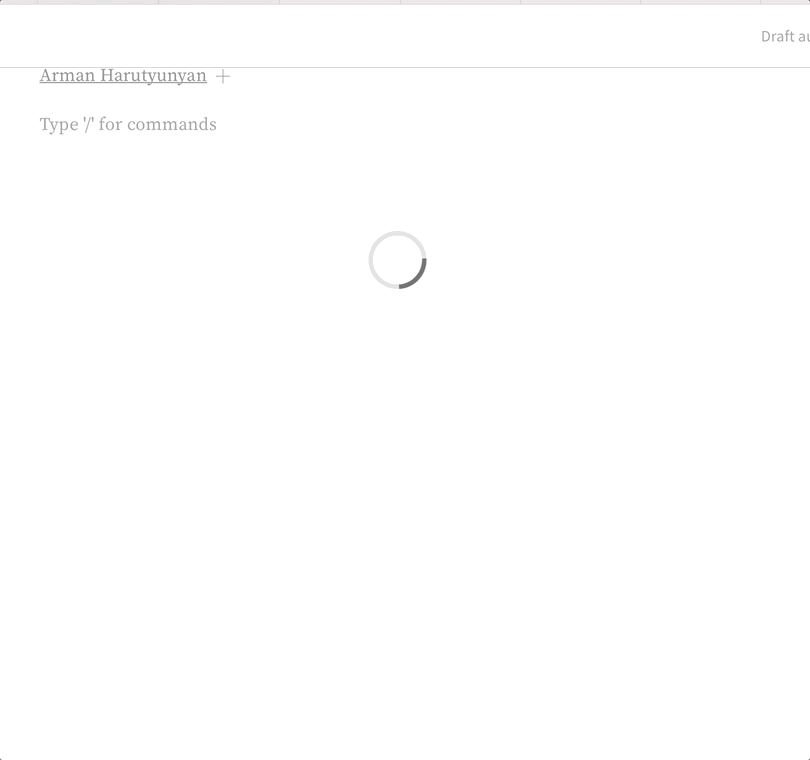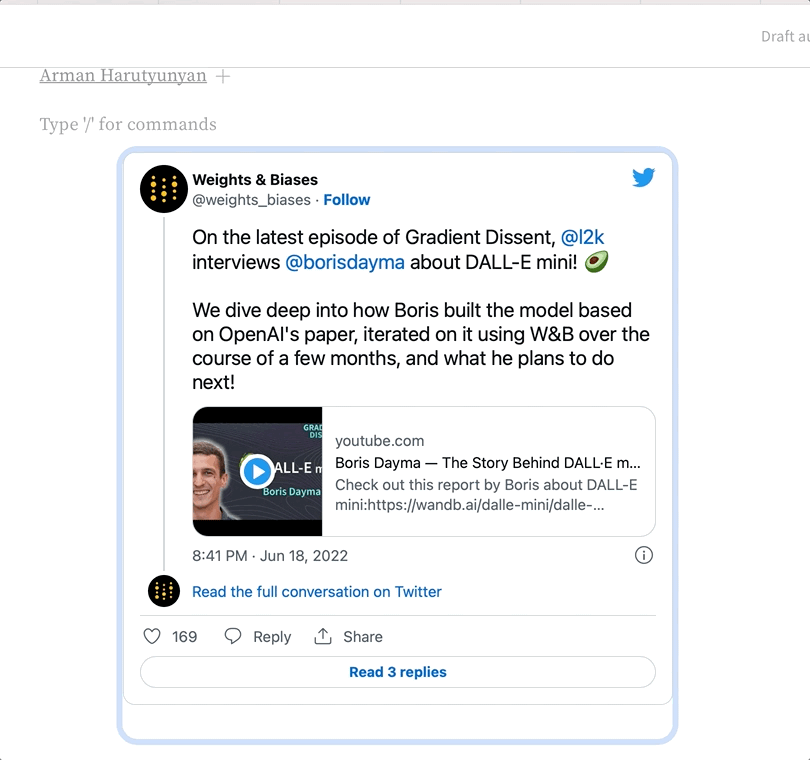
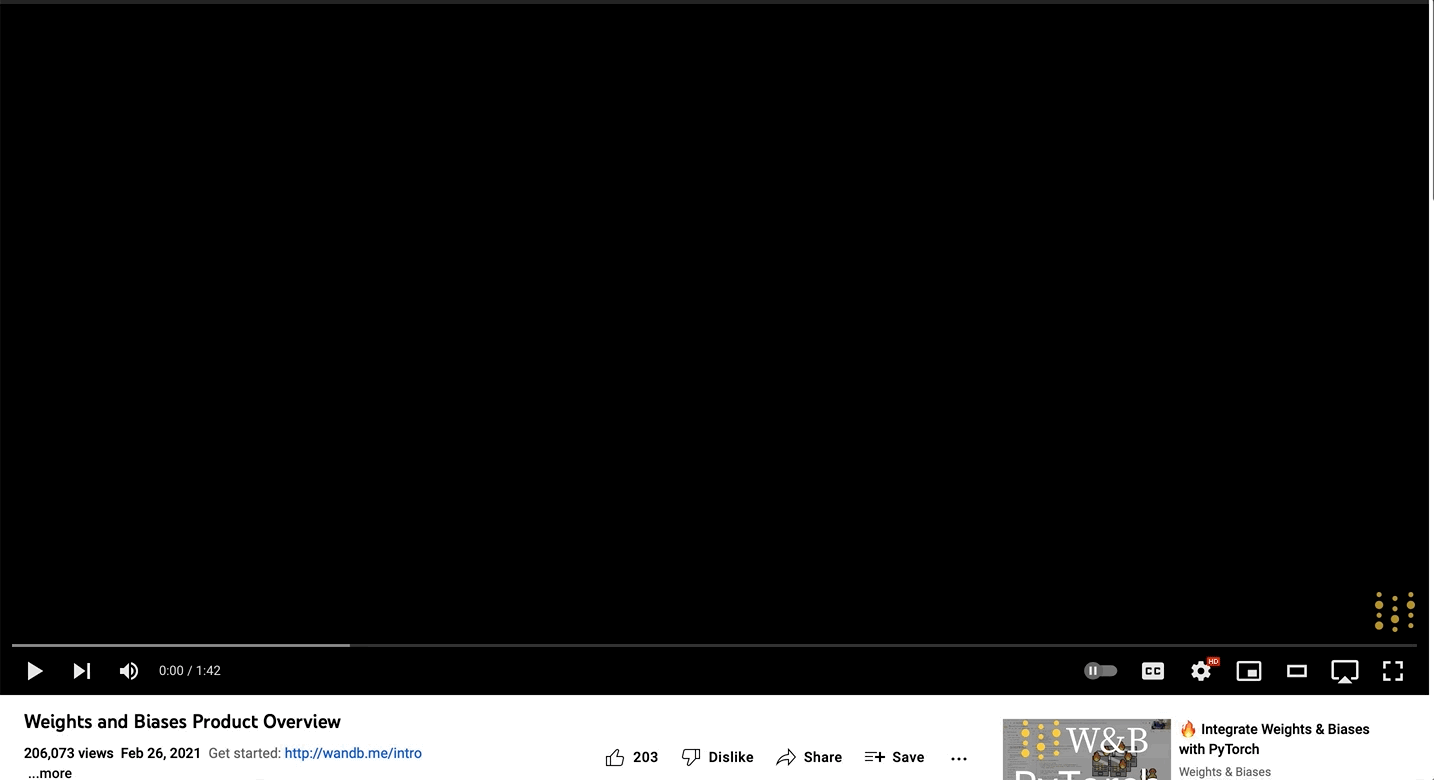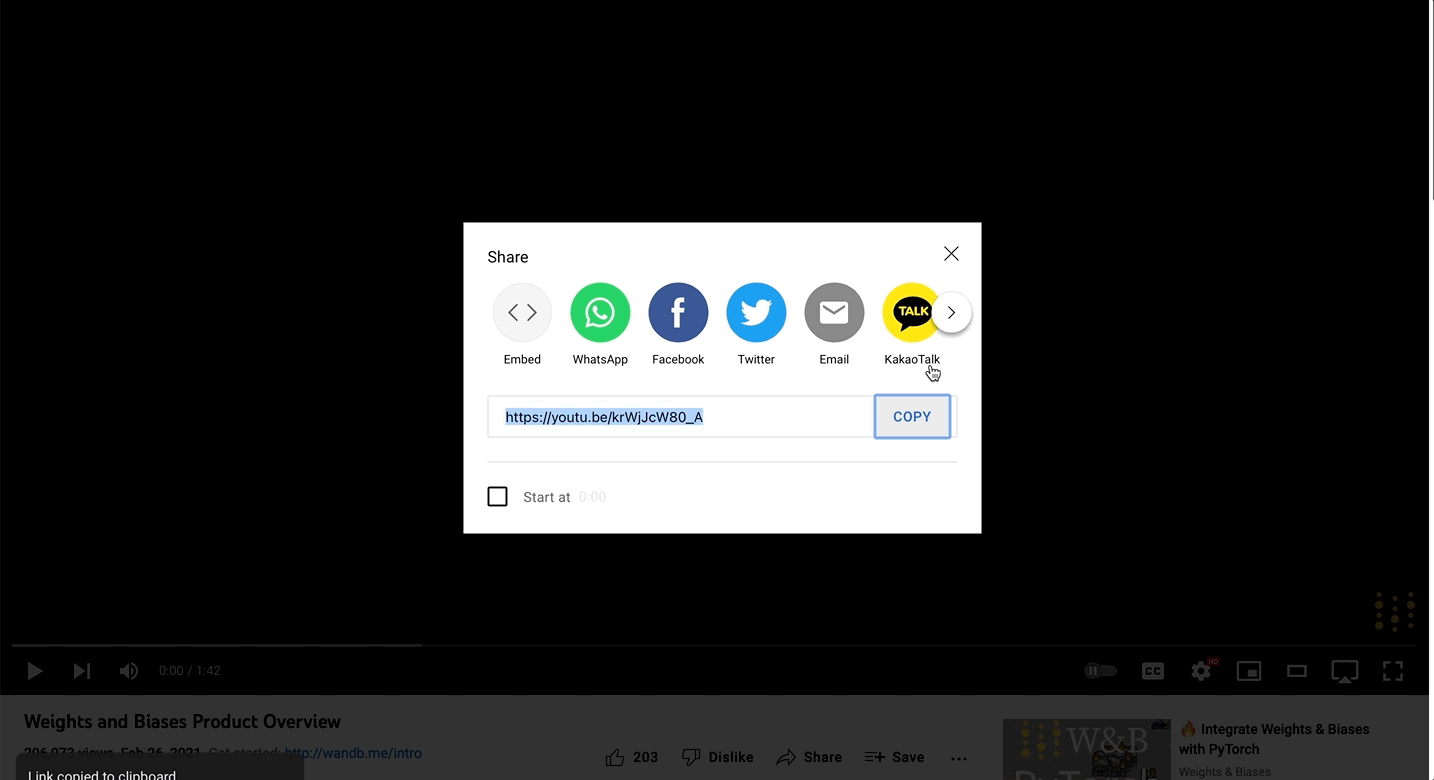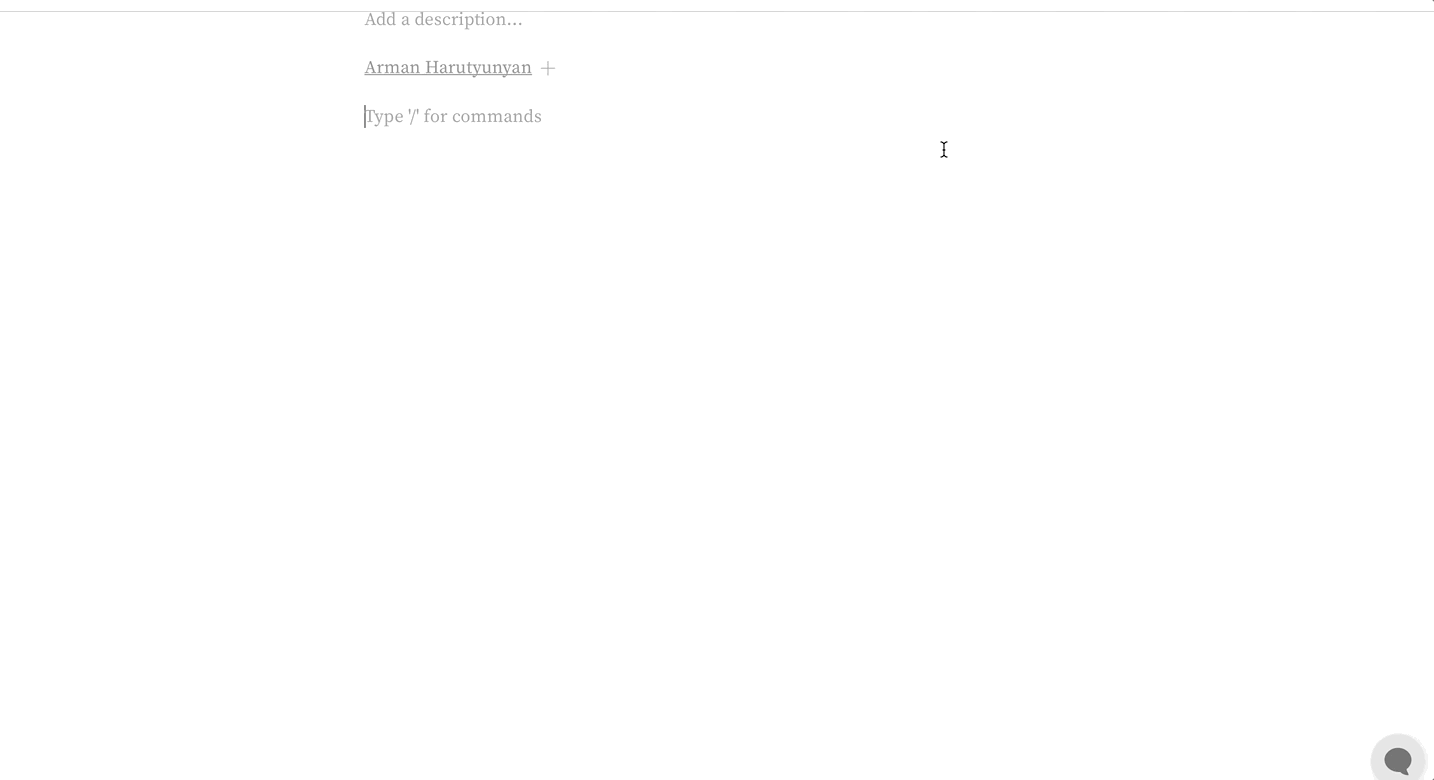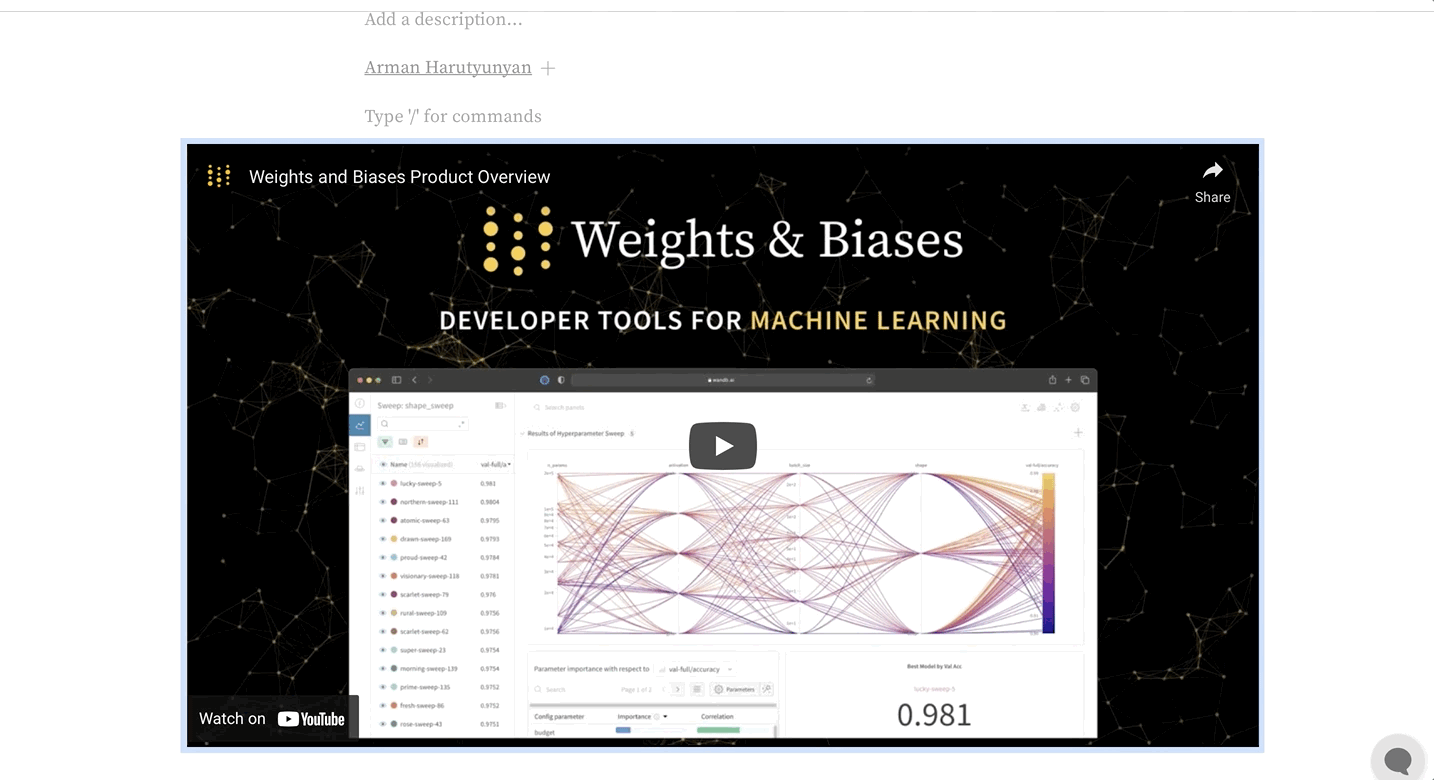
리치 미디어 링크 임베드하기
- App UI
- Report and Workspace API
패널 그리드 복제
패널 그리드 삭제
delete 키를 눌러 패널 그리드를 삭제합니다.
헤더 접기를 통해 리포트 정리하기
여러 차원에 걸친 관계 시각화
- 페널티 점수나 학습률처럼 색상 그라디언트로 나타낼 변수를 선택하세요. 이렇게 하면 트레이닝 시간(x축)에 따라 페널티(색상)가 보상 또는 부작용(y축)과 어떻게 상호작용하는지 더 명확하게 이해할 수 있습니다.
- 주요 추세를 강조하세요. 특정 Runs 그룹 위에 마우스를 올려 시각화에서 해당 그룹을 강조 표시하세요.