이 페이지에서는 프로덕션 트래픽을 모니터링하는 이전 접근 방식을 다룹니다. 새로 구현하는 경우 Weave for Agents 아래의 Signals를 사용하세요. 에이전트 시그널 보기를 참조하세요.
- 자동화된 점수화: 유입되는 모든 프로덕션 트레이스는 일반적인 품질 문제와 오류를 기준으로 자동 처리되고 점수화됩니다.
- 인프라: 처리는 수백만 건의 트레이스를 확장 가능하게 다룰 수 있도록 CoreWeave 컴퓨트와 CoreWeave GPU로 구동됩니다.
- 동작 인사이트 확보. 시스템 메트릭을 넘어, 에이전트가 환각을 일으키는지, 대화 패턴을 제대로 따르지 못하는지, 또는 근거로 삼는 증거와의 연결을 잃고 있는지를 파악할 수 있습니다.
- 연구 루프 가속화. 시그널가 생성한 점수와 실패 분석을 사용해 약점을 파악하고, 이를 모델 개선, 데이터 annotation, 또는 강화 학습 연구에 활용할 수 있습니다.
사용 가능한 시그널
품질 신호
오류 시그널
시그널 작동 방식
- 트레이스 선택: 품질 시그널은 성공한 루트 레벨 트레이스를 평가합니다. 오류 시그널은 실패한 트레이스를 평가합니다. Weave는 하위 span과 중간 Call을 점수화하지 않습니다.
- 프롬프트 구성: Weave는 트레이스 메타데이터, 입력, 출력, 예외 세부 정보(있는 경우), 오퍼레이션의 소스 코드를 포함하는 프롬프트를 구성합니다. Weave는 시그널의 분류기 프롬프트에 감지할 특정 문제에 대한 지침을 추가합니다.
- LLM 점수화: 각 시그널에 대해 Serverless Inference 모델이 이진 분류(해당 문제가 트레이스에 존재하는지 여부)를 수행합니다. 감지된 문제는 쉼표로 구분된 string 태그로 반환됩니다(예:
"Low-quality, User-frustration, Forgetful").
Monitors 페이지에서 시그널 추가
- wandb.ai로 이동한 다음 Weave 프로젝트를 여세요.
- Weave 프로젝트 사이드바에서 Monitors를 선택하세요.
- Monitors가 활성화되지 않은 프로젝트에 시그널을 추가하려면 해당 Card를 클릭해 체크박스를 활성화한 다음 Setup monitors를 클릭하세요.
- 기존 Monitor에 시그널을 추가하려면 Monitors 페이지 오른쪽 상단에서 Browse signals를 선택하세요. 그러면 Add signals 드로어가 열리며, 여기에는 사용 가능한 시그널이 범주(예: Quality classifiers 및 Error classifiers)별로 그룹화되어 각각 체크박스와 함께 나열됩니다. 개별 시그널을 선택하거나, 그룹에 대해 Enable all을 사용하거나, Create custom signal을 선택할 수 있습니다. 그런 다음 드로어 하단에서 Add signals를 선택하세요.
활성 시그널 관리
- Monitors 페이지에서 Manage signals () 버튼을 선택하세요. 그러면 현재 활성 상태인 모든 시그널이 범주별로 그룹화되어 표시되는 드로어가 열립니다.
- 시그널 위에 마우스를 올린 다음 Remove signal () 버튼을 선택해 해당 시그널을 비활성화하세요.
기본 제공 시그널 사용
Traces 페이지에서 태그가 지정된 Call 트레이스 보기
@weave.op decorator를 사용하는 Ops로 트레이싱하는 경우, Weave는 signal 결과를 Call object의 feedback으로 저장합니다. 이러한 결과는 Traces 페이지에서 쿼리할 수 있습니다.
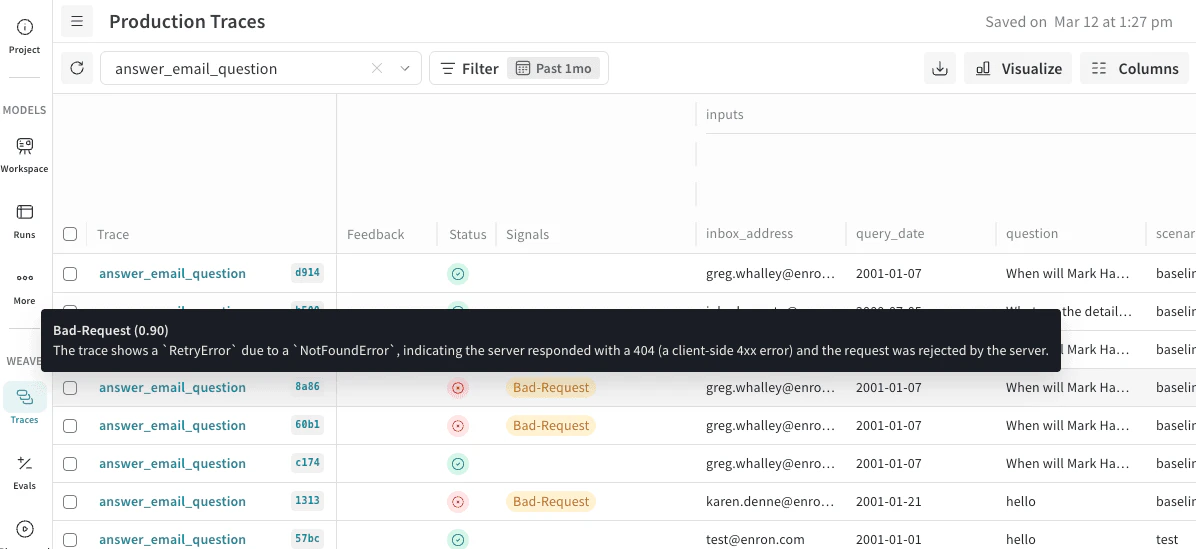
Traces 페이지의 Signals column을 사용하면 특정 동작이 있는 트레이스를 확인할 수 있습니다. Signals column은 기준이 충족되면 tags를 표시합니다. 이 tags에 마우스를 올리면 score의 confidence와 추론을 확인할 수 있습니다.
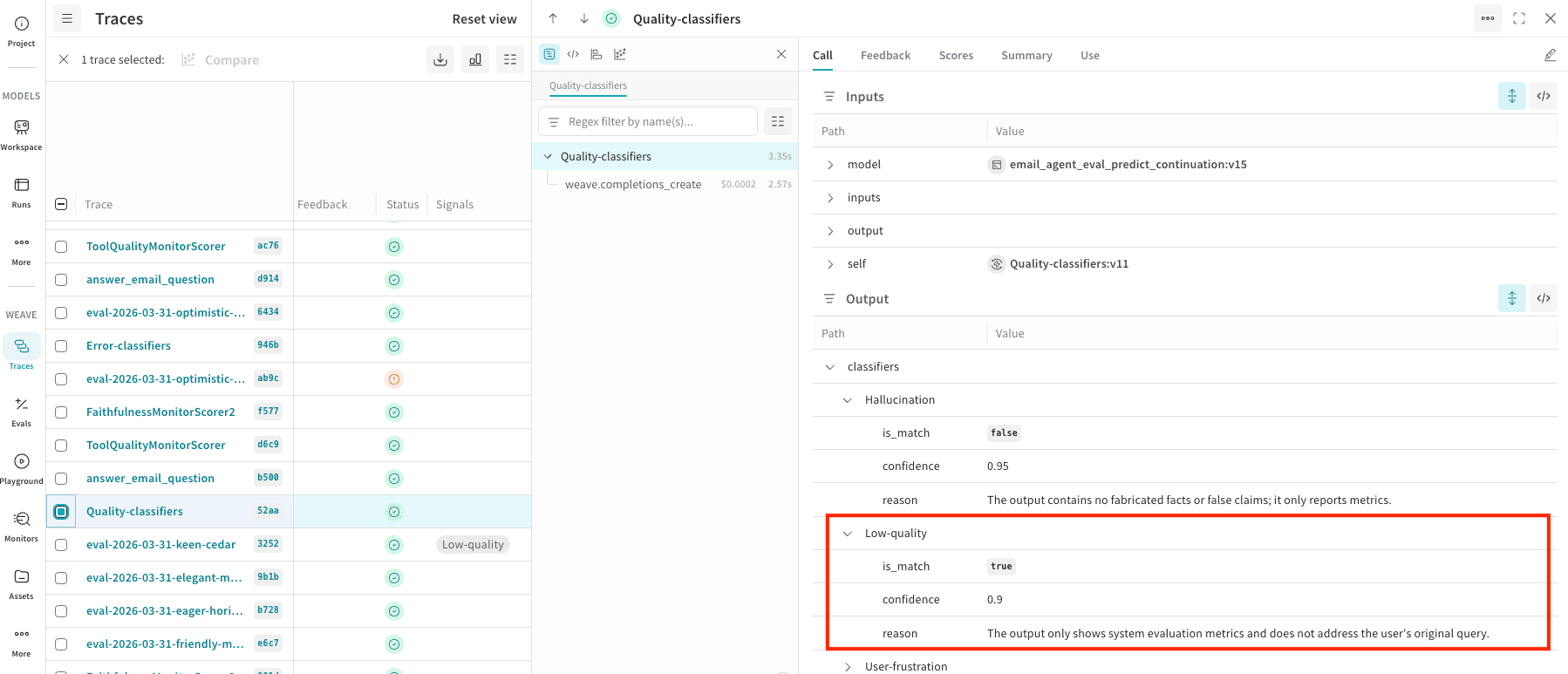
classifier_meta를 확인하세요. 예를 들어, 다음 스크린샷은 Low-quality 일치와 confidence(0.9), 그리고 이 평가에 대한 이유가 포함된 Quality-classifiers signal을 보여줍니다.
프로젝트 대시보드에서 신호 보기
- 프로젝트 사이드바에서 Project를 선택하세요.
- Project 대시보드 상단에서 Weave 탭을 선택하세요.
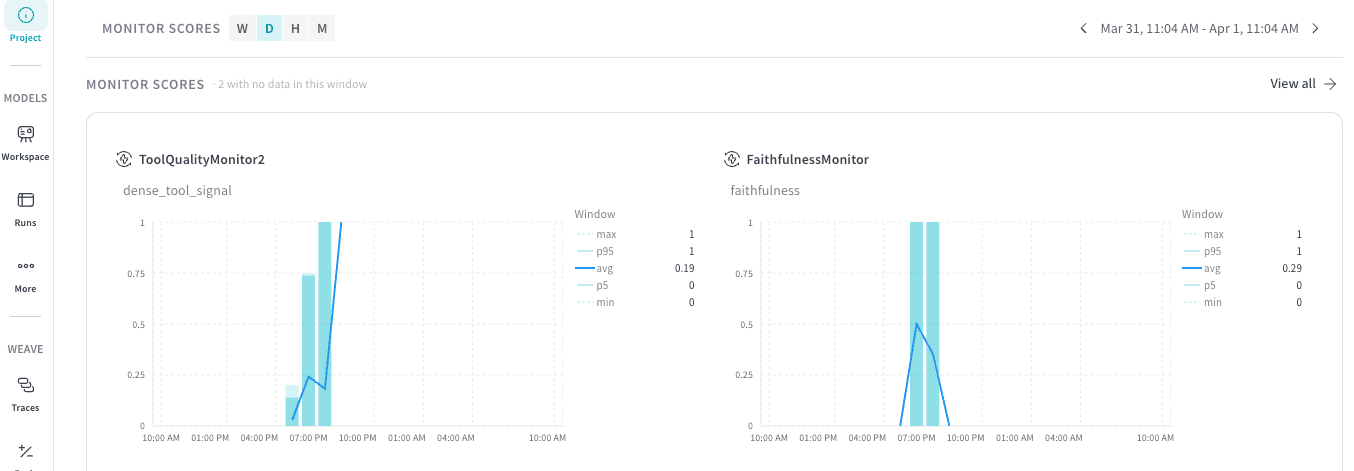
- Weave 대시보드 패널에서 Monitor Scores를 찾으세요.
시그널 알림
기본 제공 시그널만으로는 부족한 특정 모니터링이 필요하면 맞춤형 모니터 설정을 참조하세요.