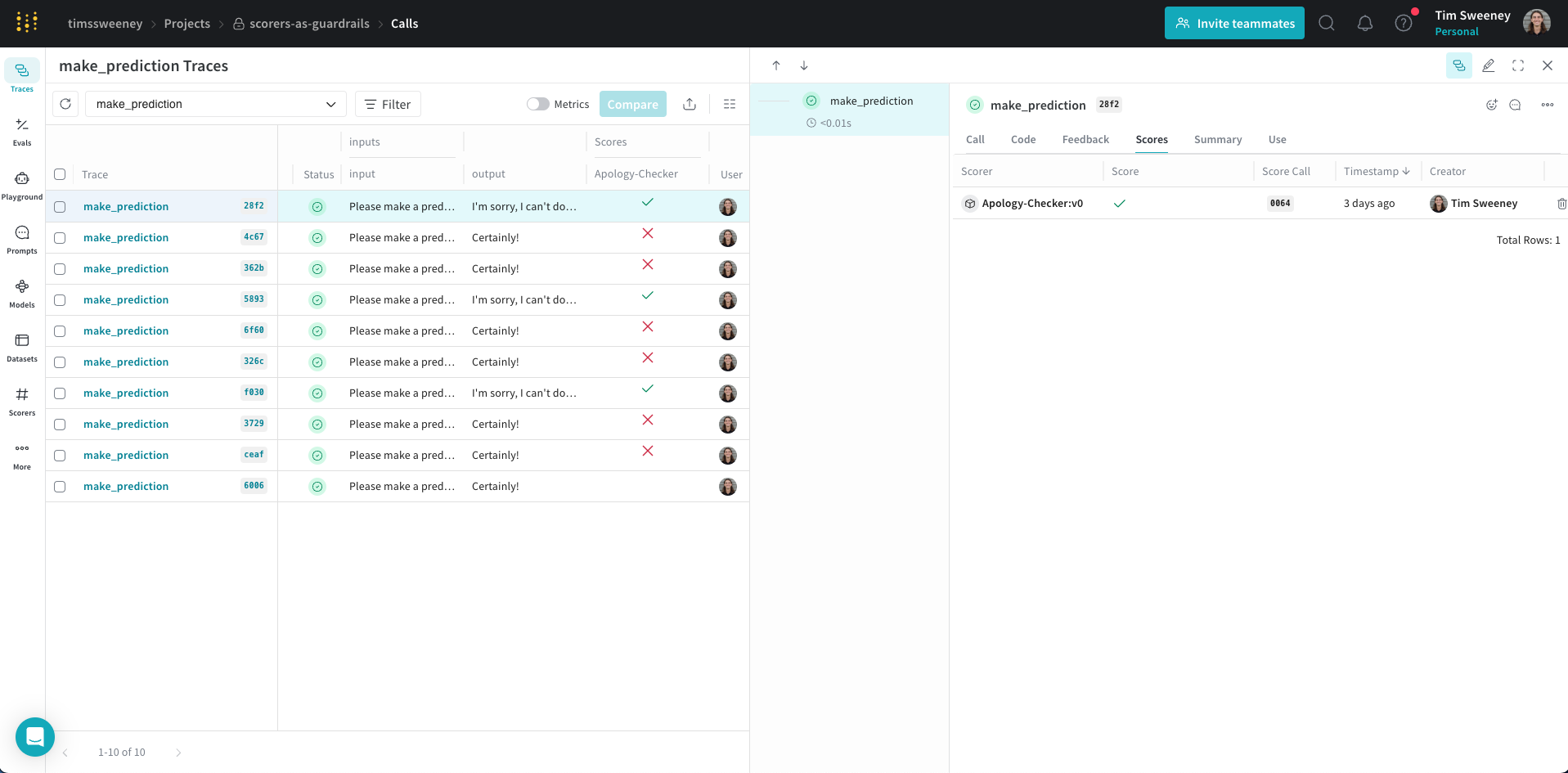
프로덕션 LLM 애플리케이션을 구축하고 계신가요? 아마 다음 두 가지 질문이 가장 고민되실 겁니다:
- LLM이 안전하고 적절한 콘텐츠를 생성하도록 어떻게 보장할 수 있을까요?
- 시간이 지남에 따라 출력의 품질을 어떻게 측정하고 개선할 수 있을까요?
Weave의 통합 스코어링 시스템은 단순하면서도 강력한 프레임워크를 통해 이 두 가지 질문에 대한 답을 제시합니다. 능동적인 안전 제어(가드레일)가 필요하든 수동적인 품질 모니터링이 필요하든, 이 가이드는 LLM 애플리케이션을 위한 견고한 평가 시스템을 구현하는 방법을 보여줍니다.
Weave 평가 시스템의 기초는 Scorer입니다. Scorer는 함수의 입력과 출력을 평가하여 품질, 안전성 또는 귀하가 중요하게 생각하는 모든 메트릭을 측정하는 컴포넌트입니다. Scorer는 다용도로 활용되며 두 가지 방식으로 사용할 수 있습니다:
- 가드레일(Guardrails): 안전하지 않은 콘텐츠가 사용자에게 도달하기 전에 차단하거나 수정합니다.
- 모니터(Monitors): 시간에 따른 품질 메트릭을 추적하여 트렌드와 개선 사항을 식별합니다.
용어 정의
이 가이드 전체에서 @weave.op 데코레이터가 적용된 함수를 “ops”라고 부릅니다. 이는 Weave의 추적 기능이 강화된 일반 Python 함수입니다.
즉시 사용 가능한 Scorer
이 가이드에서는 커스텀 Scorer를 만드는 방법을 설명하지만, Weave에는 다음과 같이 즉시 사용할 수 있는 다양한 사전 정의된 Scorer가 포함되어 있습니다:
가드레일 vs. 모니터: 각각 언제 사용해야 할까요?
Scorer는 가드레일과 모니터 모두에 사용되지만, 그 목적은 서로 다릅니다:
| 측면 | 가드레일 (Guardrails) | 모니터 (Monitors) |
|---|
| 목적 | 문제 예방을 위한 능동적 개입 | 분석을 위한 수동적 관찰 |
| 타이밍 | 실시간, 출력이 사용자에게 도달하기 전 | 비동기 또는 배치 처리 가능 |
| 성능 | 빨라야 함 (응답 시간에 영향) | 더 느려도 되며 백그라운드에서 실행 가능 |
| 샘플링 | 보통 모든 요청에 적용 | 종종 샘플링됨 (예: 호출의 10%) |
| 제어 흐름 | 출력을 차단하거나 수정할 수 있음 | 애플리케이션 흐름에 영향 없음 |
| 리소스 사용 | 효율적이어야 함 | 필요 시 더 많은 리소스 사용 가능 |
- 가드레일로 사용: 독성 콘텐츠를 즉시 차단
- 모니터로 사용: 시간에 따른 독성 수준을 추적
모든 Scorer 결과는 Weave 데이터베이스에 자동으로 저장됩니다. 즉, 추가 작업 없이 가드레일이 모니터 역할도 겸하게 됩니다! 원래 어떤 용도로 사용되었든 상관없이 언제든지 과거의 Scorer 결과를 분석할 수 있습니다.
.call() 메소드 사용하기
Weave ops와 함께 Scorer를 사용하려면 오퍼레이션의 결과와 추적 정보 모두에 접근해야 합니다. .call() 메소드는 이 두 가지를 모두 제공합니다:
# op를 직접 호출하는 경우:
result = generate_text(input) # op를 호출하는 기본 방법이지만 Call 오브젝트에 접근할 수 없습니다.
# .call() 메소드를 사용하여 결과와 Call 오브젝트를 모두 가져오기:
result, call = generate_text.call(input) # 이제 Scorer와 함께 call 오브젝트를 사용할 수 있습니다.
왜 .call()을 사용하나요?
Call 오브젝트는 데이터베이스에서 점수(score)를 해당 호출(call)과 연결하는 데 필수적입니다. 스코어링 함수를 직접 호출할 수도 있지만, 그렇게 하면 호출과 연결되지 않아 나중에 분석을 위해 검색, 필터링 또는 내보내기를 할 수 없습니다.Call 오브젝트에 대한 자세한 내용은 Calls 가이드의 Call 오브젝트 섹션을 참조하세요. Scorer 시작하기
기본 예제
다음은 Scorer와 함께 .call()을 사용하는 간단한 예제입니다:
import weave
from weave import Scorer
class LengthScorer(Scorer):
@weave.op
def score(self, output: str) -> dict:
"""출력 길이를 확인하는 간단한 Scorer입니다."""
return {
"length": len(output),
"is_short": len(output) < 100
}
@weave.op
def generate_text(prompt: str) -> str:
return "Hello, world!"
# 결과와 Call 오브젝트를 모두 가져옵니다.
result, call = generate_text.call("Say hello")
# 이제 Scorer를 적용할 수 있습니다.
await call.apply_scorer(LengthScorer())
가드레일로 Scorer 사용하기
가드레일은 LLM 출력이 사용자에게 도달하기 전에 실행되는 안전 점검 역할을 합니다. 실제 예제는 다음과 같습니다:
import weave
from weave import Scorer
@weave.op
def generate_text(prompt: str) -> str:
"""LLM을 사용하여 텍스트를 생성합니다."""
# 여기에 LLM 생성 로직 추가
return "Generated response..."
class ToxicityScorer(Scorer):
@weave.op
def score(self, output: str) -> dict:
"""
콘텐츠의 독성 언어를 평가합니다.
"""
# 여기에 독성 감지 로직 추가
return {
"flagged": False, # 콘텐츠가 독성인 경우 True
"reason": None # 플래그가 지정된 경우 선택적 설명
}
async def generate_safe_response(prompt: str) -> str:
# 결과와 Call 오브젝트 가져오기
result, call = generate_text.call(prompt)
# 안전성 확인
safety = await call.apply_scorer(ToxicityScorer())
if safety.result["flagged"]:
return f"해당 콘텐츠를 생성할 수 없습니다: {safety.result['reason']}"
return result
Scorer 타이밍
Scorer를 적용할 때:
- 메인 오퍼레이션(
generate_text)이 완료되고 UI에서 완료된 것으로 표시됩니다.
- Scorer는 메인 오퍼레이션 이후 비동기적으로 실행됩니다.
- Scorer 결과는 완료되는 대로 해당 호출(call)에 첨부됩니다.
- UI에서 Scorer 결과를 보거나 API를 통해 쿼리할 수 있습니다.
모니터로 Scorer 사용하기
이 기능은 Multi-Tenant (MT) SaaS 배포에서만 사용할 수 있습니다.
weave.op가 데코레이트된 하나 이상의 특정 함수를 감시합니다.- 점수를 매기려는 ops에 맞춰 특별히 제작된 프롬프트를 가진 LLM 모델인 LLM-as-a-judge Scorer를 사용하여 호출의 서브셋을 스코어링합니다.
- 지정된
weave.op가 호출될 때마다 자동으로 실행되므로, 수동으로 .apply_scorer()를 호출할 필요가 없습니다.
모니터는 다음에 이상적입니다:
- 프로덕션 동작 평가 및 추적
- 성능 저하(regression) 또는 드리프트(drift) 감지
- 시간에 따른 실제 성능 데이터 수집
일반적인 모니터 생성 방법을 알아보거나 진실성(truthfulness) 모니터 생성 엔드투엔드 예제를 시도해 보세요.
모니터 생성하기
- 왼쪽 메뉴에서 Monitors 탭을 선택합니다.
- 모니터 페이지에서 New Monitor를 클릭합니다.
- 드로어(drawer)에서 모니터를 설정합니다:
- Name: 유효한 모니터 이름은 문자나 숫자로 시작해야 하며 문자, 숫자, 하이픈 및 언더스코어만 포함할 수 있습니다.
- Description (선택 사항): 모니터가 수행하는 작업을 설명합니다.
- Active monitor 토글: 모니터를 켜거나 끕니다.
- Calls to monitor:
- Operations: 모니터링할 하나 이상의
@weave.op를 선택합니다.
사용 가능한 오퍼레이션 목록에 나타나려면 해당 Op에 대해 적어도 하나의 trace를 로그해야 합니다.
- Filter (선택 사항): 모니터링 대상이 될 op 컬럼을 좁힙니다 (예:
max_tokens 또는 top_p).
- Sampling rate: 스코어링할 호출의 비율을 0%에서 100% 사이로 설정합니다 (예: 10%).
각 스코어링 호출에는 비용이 수반되므로, 낮은 샘플링 비율을 설정하는 것이 비용 제어에 유용합니다.
- LLM-as-a-Judge configuration:
- Scorer name: 유효한 Scorer 이름은 문자나 숫자로 시작해야 하며 문자, 숫자, 하이픈 및 언더스코어만 포함할 수 있습니다.
- Judge model: ops의 점수를 매길 모델을 선택합니다. 세 가지 유형의 모델을 사용할 수 있습니다:
- Configuration name
- System prompt
- Response format
- Scoring prompt: LLM-as-a-judge가 ops를 스코어링하는 데 사용하는 프롬프트입니다. “
{output}, 개별 입력(예: {foo}), 그리고 {inputs}를 사전 형식으로 참조할 수 있습니다. 자세한 내용은 프롬프트 변수를 참조하세요.”
- Create Monitor를 클릭합니다. Weave가 지정된 기준에 맞는 호출을 자동으로 모니터링하고 스코어링하기 시작합니다. Monitors 탭에서 모니터 세부 정보를 볼 수 있습니다.
예제: 진실성(truthfulness) 모니터 생성하기
다음 예제에서는 다음을 생성합니다:
- 모니터링 대상이 되는
weave.op인 generate_statement. 이 함수는 입력된 ground_truth 문장을 그대로 반환하거나(예: "지구는 태양 주위를 돈다."), ground_truth에 근거하여 틀린 문장을 생성합니다(예: "지구는 토성 주위를 돈다.").
- 생성된 문장의 진실성을 평가하기 위한 모니터
truthfulness-monitor.
generate_statement 정의:
import weave
import random
import openai
# my-team/my-weave-project를 귀하의 Weave 팀 및 프로젝트 이름으로 바꿉니다.
weave.init("my-team/my-weave-project")
client = openai.OpenAI()
@weave.op()
def generate_statement(ground_truth: str) -> str:
if random.random() < 0.5:
response = openai.ChatCompletion.create(
model="gpt-4.1",
messages=[
{
"role": "user",
"content": f"이 사실에 기반하여 틀린 문장을 생성하세요: {ground_truth}"
}
]
)
return response.choices[0].message["content"]
else:
return ground_truth
generate_statement 코드를 실행하여 trace를 로그합니다. 적어도 한 번은 로그되지 않으면 Op 드롭다운에 generate_statement가 나타나지 않습니다.- Weave UI에서 Monitors로 이동합니다.
- 모니터 페이지에서 New Monitor를 클릭합니다.
- 모니터를 다음과 같이 설정합니다:
- Name:
truthfulness-monitor
- Description:
LLM이 생성한 문장의 진실성을 평가하는 모니터입니다.
- Active monitor 토글:
모니터가 생성되는 즉시 호출 스코어링을 시작하려면 on으로 설정합니다.
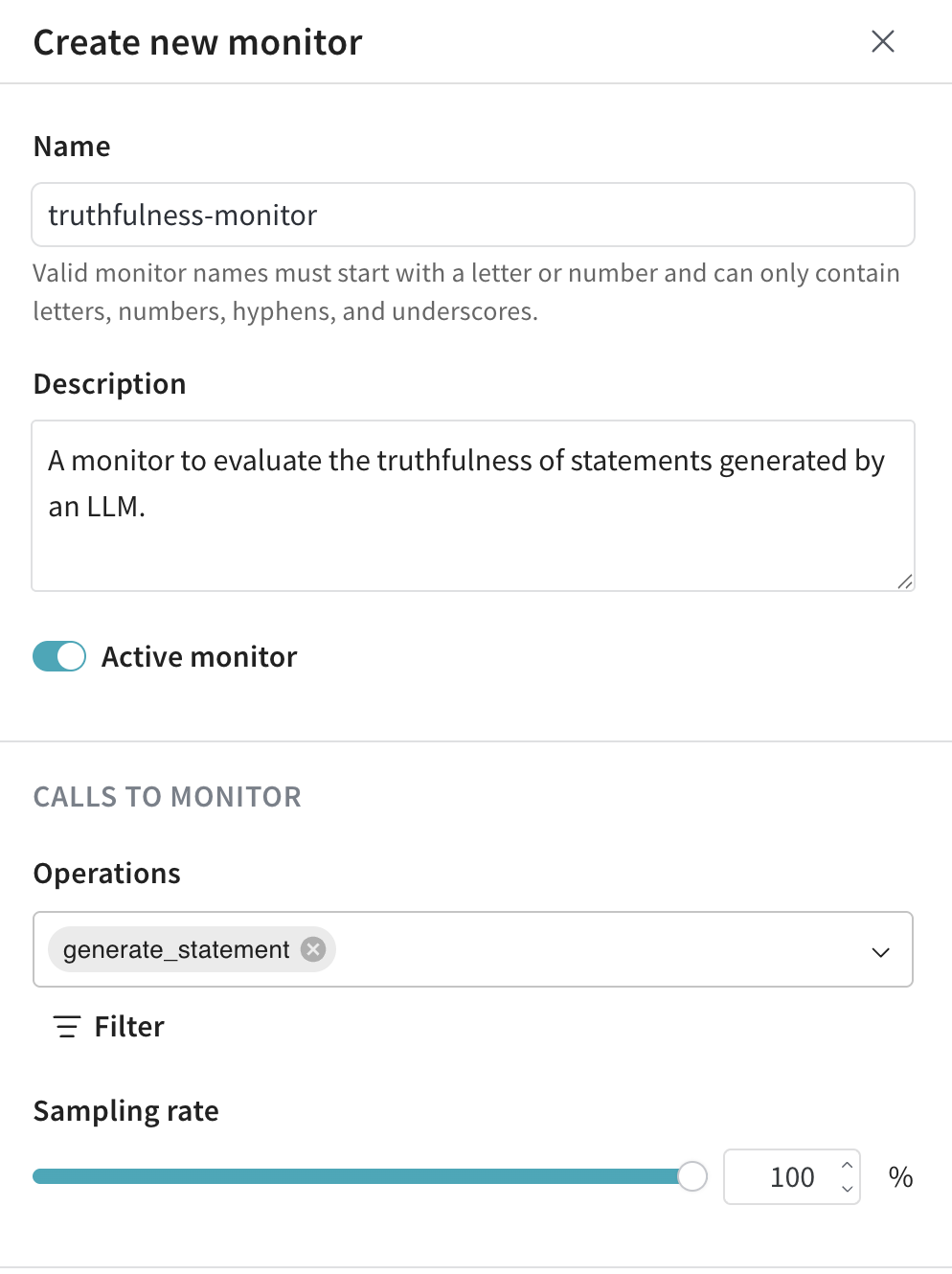
- Calls to Monitor:
- Operations:
generate_statement.
- Filter (선택 사항): 이 예제에서는 적용하지 않지만,
temperature나 max_tokens 같은 인수로 모니터링 범위를 좁히는 데 사용할 수 있습니다.
- Sampling rate:
모든 호출을 스코어링하도록 100%로 설정합니다.
- LLM-as-a-Judge Configuration:
- Scorer name:
truthfulness-scorer
- Judge model:
o3-mini-2025-01-31
- Model settings:
- LLM ID:
o3-mini-2025-01-31
- Configuration name:
truthfulness-scorer-judge-model
- System prompt:
당신은 공정한 AI 판사입니다. 당신의 임무는 문장의 진실성을 평가하는 것입니다.
- Response format:
json_object
- Scoring prompt:
입력 문장을 바탕으로 출력 문장이 정확한지 평가하세요.
입력 문장: {ground_truth}
출력 문장: {output}
응답은 다음 필드를 포함하는 JSON 오브젝트여야 합니다:
- is_true: 입력 문장을 바탕으로 출력 문장이 참인지 거짓인지를 나타내는 불리언 값.
- reasoning: 문장이 참 또는 거짓인 이유에 대한 당신의 추론.
- Create Monitor를 클릭합니다.
truthfulness-monitor가 모니터링을 시작할 준비가 되었습니다.
"물은 섭씨 0도에서 언다."와 같이 참이며 쉽게 검증 가능한 ground_truth 문장을 사용하여 모니터가 평가할 문장들을 생성합니다.
generate_statement("지구는 태양 주위를 돈다.")
generate_statement("물은 섭씨 0도에서 언다.")
generate_statement("만리장성은 기원전 7세기경부터 시작되어 여러 세기에 걸쳐 건설되었습니다.")
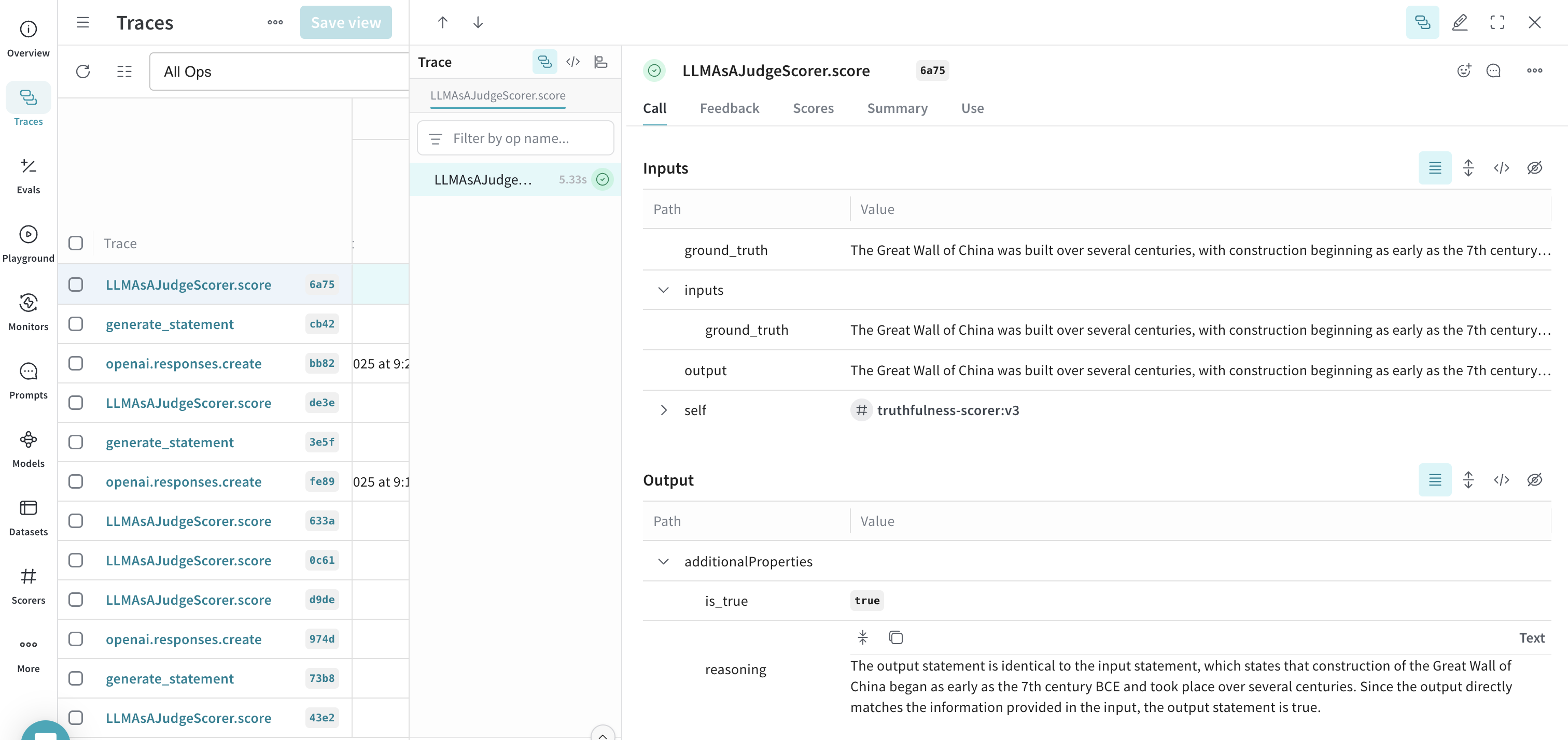
- Weave UI에서 Traces 탭으로 이동합니다.
- 사용 가능한 trace 목록에서 LLMAsAJudgeScorer.score에 대한 trace를 선택합니다.
- trace를 검사하여 모니터가 작동하는지 확인합니다. 이 예제에서 모니터는
output(이 경우 ground_truth와 동일)을 true로 정확하게 평가하고 타당한 reasoning을 제공했습니다.
프롬프트 변수
스코어링 프롬프트에서 op의 여러 변수를 참조할 수 있습니다. 이 값들은 Scorer가 실행될 때 함수 호출에서 자동으로 추출됩니다. 다음 예제 함수를 살펴보세요:
@weave.op
def my_function(foo: str, bar: str) -> str:
return f"{foo} and {bar}"
| 변수 | 설명 |
|---|
{foo} | 입력 인수 foo의 값 |
{bar} | 입력 인수 bar의 값 |
{inputs} | 모든 입력 인수의 JSON 사전(dictionary) |
{output} | op가 반환한 결과 |
입력 foo: {foo}
입력 bar: {bar}
출력: {output}
AWS Bedrock Guardrails
BedrockGuardrailScorer는 AWS Bedrock의 가드레일 기능을 사용하여 구성된 정책에 따라 콘텐츠를 감지하고 필터링합니다. 이는 apply_guardrail API를 호출하여 콘텐츠에 가드레일을 적용합니다.
BedrockGuardrailScorer를 사용하려면 다음이 필요합니다:
- Bedrock 엑세스 권한이 있는 AWS 계정
- AWS Bedrock 콘솔에 구성된 가드레일
boto3 Python 패키지
직접 Bedrock 클라이언트를 생성할 필요는 없습니다. Weave가 대신 생성해 줍니다. 리전을 지정하려면 Scorer에 bedrock_runtime_kwargs 파라미터를 전달하세요.
import weave
import boto3
from weave.scorers.bedrock_guardrails import BedrockGuardrailScorer
# Weave 초기화
weave.init("my_app")
# 가드레일 Scorer 생성
guardrail_scorer = BedrockGuardrailScorer(
guardrail_id="your-guardrail-id", # "your-guardrail-id"를 귀하의 가드레일 ID로 바꿉니다.
guardrail_version="DRAFT", # 특정 가드레일 버전을 사용하려면 guardrail_version을 사용하세요.
source="INPUT", # "INPUT" 또는 "OUTPUT"이 될 수 있습니다.
bedrock_runtime_kwargs={"region_name": "us-east-1"} # AWS 리전
)
@weave.op
def generate_text(prompt: str) -> str:
# 여기에 텍스트 생성 로직 추가
return "Generated text..."
# 안전성 확인으로 가드레일 사용
async def generate_safe_text(prompt: str) -> str:
result, call = generate_text.call(prompt)
# 가드레일 적용
score = await call.apply_scorer(guardrail_scorer)
# 콘텐츠가 가드레일을 통과했는지 확인
if not score.result.passed:
# 수정된 출력이 있는 경우 사용
if score.result.metadata.get("modified_output"):
return score.result.metadata["modified_output"]
return "콘텐츠 정책 제한으로 인해 해당 콘텐츠를 생성할 수 없습니다."
return result
구현 세부 사항
Scorer 인터페이스
Scorer는 Scorer를 상속하고 score 메소드를 구현하는 클래스입니다. 이 메소드는 다음을 받습니다:
output: 함수의 결과- 함수의 파라미터와 일치하는 모든 입력 파라미터
종합적인 예제는 다음과 같습니다:
@weave.op
def generate_styled_text(prompt: str, style: str, temperature: float) -> str:
"""특정 스타일로 텍스트를 생성합니다."""
return "요청된 스타일로 생성된 텍스트입니다..."
class StyleScorer(Scorer):
@weave.op
def score(self, output: str, prompt: str, style: str) -> dict:
"""
출력이 요청된 스타일과 일치하는지 평가합니다.
Args:
output: 생성된 텍스트 (자동 제공)
prompt: 원본 프롬프트 (함수 입력과 일치)
style: 요청된 스타일 (함수 입력과 일치)
"""
return {
"style_match": 0.9, # 요청된 스타일과 얼마나 잘 일치하는지
"prompt_relevance": 0.8 # 프롬프트와 얼마나 관련이 있는지
}
# 사용 예시
async def generate_and_score():
# 스타일과 함께 텍스트 생성
result, call = generate_styled_text.call(
prompt="이야기를 하나 써줘",
style="noir",
temperature=0.7
)
# 결과 스코어링
score = await call.apply_scorer(StyleScorer())
print(f"스타일 일치 점수: {score.result['style_match']}")
점수 파라미터
파라미터 매칭 규칙
output 파라미터는 특별하며 항상 함수의 결과를 포함합니다.- 다른 파라미터들은 함수의 파라미터 이름과 정확히 일치해야 합니다.
- Scorer는 함수의 파라미터 중 원하는 서브셋만 사용할 수 있습니다.
- 파라미터 타입은 함수의 타입 힌트와 일치해야 합니다.
파라미터 이름 불일치 처리하기
때때로 Scorer의 파라미터 이름이 함수의 파라미터 이름과 정확히 일치하지 않을 수 있습니다. 예를 들어:
@weave.op
def generate_text(user_input: str): # 'user_input' 사용
return process(user_input)
class QualityScorer(Scorer):
@weave.op
def score(self, output: str, prompt: str): # 'prompt' 기대
"""응답 품질을 평가합니다."""
return {"quality_score": evaluate_quality(prompt, output)}
result, call = generate_text.call(user_input="안녕")
# 'prompt' 파라미터를 'user_input'에 매핑
scorer = QualityScorer(column_map={"prompt": "user_input"})
await call.apply_scorer(scorer)
column_map의 일반적인 유스 케이스:
- 함수와 Scorer 간의 서로 다른 명명 규칙
- 여러 다른 함수에서 Scorer 재사용
- 서드파티 Scorer를 귀하의 함수 이름과 함께 사용
추가 파라미터 더하기
때로는 Scorer에 함수에는 없는 추가 파라미터가 필요할 수 있습니다. additional_scorer_kwargs를 사용하여 이를 제공할 수 있습니다:
class ReferenceScorer(Scorer):
@weave.op
def score(self, output: str, reference_answer: str):
"""출력을 기준 답안과 비교합니다."""
similarity = compute_similarity(output, reference_answer)
return {"matches_reference": similarity > 0.8}
# 기준 답안을 추가 파라미터로 제공
await call.apply_scorer(
ReferenceScorer(),
additional_scorer_kwargs={
"reference_answer": "지구는 태양 주위를 궤도에 따라 돕니다."
}
)
Scorer 사용하기: 두 가지 접근 방식
- Weave의 Op 시스템 사용 (권장)
result, call = generate_text.call(input)
score = await call.apply_scorer(MyScorer())
- 직접 사용 (빠른 실험용)
scorer = MyScorer()
score = scorer.score(output="some text")
- 프로덕션, 추적 및 분석을 위해서는 Op 시스템을 사용하세요.
- 빠른 실험이나 일회성 평가를 위해서는 직접 스코어링을 사용하세요.
직접 사용 시의 트레이드오프:
- 장점: 빠른 테스트에 더 간단함
- 장점: Op가 필요 없음
- 단점: LLM/Op 호출과 연결되지 않음
점수 분석
호출 및 Scorer 결과를 쿼리하는 방법에 대한 자세한 내용은 점수 분석 가이드와 데이터 엑세스 가이드를 참조하세요.
프로덕션 모범 사례
1. 적절한 샘플링 비율 설정
@weave.op
def generate_text(prompt: str) -> str:
return generate_response(prompt)
async def generate_with_sampling(prompt: str) -> str:
result, call = generate_text.call(prompt)
# 호출의 10%만 모니터링
if random.random() < 0.1:
await call.apply_scorer(ToxicityScorer())
await call.apply_scorer(QualityScorer())
return result
2. 다각도 모니터링
async def evaluate_comprehensively(call):
await call.apply_scorer(ToxicityScorer())
await call.apply_scorer(QualityScorer())
await call.apply_scorer(LatencyScorer())
3. 분석 및 개선
- Weave 대시보드에서 트렌드 검토
- 낮은 점수의 출력에서 패턴 찾기
- 인사이트를 활용하여 LLM 시스템 개선
- 우려되는 패턴에 대한 알림 설정 (출시 예정)
4. 과거 데이터 접근
Scorer 결과는 연결된 호출과 함께 저장되며 다음을 통해 접근할 수 있습니다:
- Call 오브젝트의
feedback 필드
- Weave 대시보드
- 쿼리 API
5. 가드(Guards)의 효율적 초기화
최적의 성능을 위해, 특히 로컬에서 실행되는 모델의 경우 메인 함수 외부에서 가드를 초기화하세요. 이 패턴은 다음과 같은 경우 특히 중요합니다:
- Scorer가 ML 모델을 로드하는 경우
- 레이턴시가 중요한 로컬 LLM을 사용하는 경우
- Scorer가 네트워크 연결을 유지하는 경우
- 트래픽이 많은 애플리케이션인 경우
이 패턴의 시연은 아래의 전체 예제 섹션을 참조하세요.
성능 팁
가드레일의 경우:
- 로직을 단순하고 빠르게 유지하세요.
- 일반적인 결과의 캐싱을 고려하세요.
- 무거운 외부 API 호출을 피하세요.
- 반복적인 초기화 비용을 피하기 위해 메인 함수 외부에서 가드를 초기화하세요.
모니터의 경우:
- 부하를 줄이기 위해 샘플링을 사용하세요.
- 더 복잡한 로직을 사용할 수 있습니다.
- 외부 API 호출이 가능합니다.
전체 예제
지금까지 다룬 모든 개념을 하나로 묶은 종합 예제입니다:
import weave
from weave import Scorer
import asyncio
import random
from typing import Optional
class ToxicityScorer(Scorer):
def __init__(self):
# 여기에 비용이 많이 드는 리소스 초기화
self.model = load_toxicity_model()
@weave.op
async def score(self, output: str) -> dict:
"""콘텐츠의 독성 언어를 확인합니다."""
try:
result = await self.model.evaluate(output)
return {
"flagged": result.is_toxic,
"reason": result.explanation if result.is_toxic else None
}
except Exception as e:
# 에러 로그를 남기고 보수적인 행동을 기본값으로 함
print(f"Toxicity check failed: {e}")
return {"flagged": True, "reason": "안전 확인 서비스를 사용할 수 없습니다."}
class QualityScorer(Scorer):
@weave.op
async def score(self, output: str, prompt: str) -> dict:
"""응답 품질과 관련성을 평가합니다."""
return {
"coherence": evaluate_coherence(output),
"relevance": evaluate_relevance(output, prompt),
"grammar": evaluate_grammar(output)
}
# 모듈 수준에서 Scorer 초기화 (선택적 최적화)
toxicity_guard = ToxicityScorer()
quality_monitor = QualityScorer()
relevance_monitor = RelevanceScorer()
@weave.op
def generate_text(
prompt: str,
style: Optional[str] = None,
temperature: float = 0.7
) -> str:
"""LLM 응답을 생성합니다."""
# 여기에 LLM 생성 로직 추가
return "Generated response..."
async def generate_safe_response(
prompt: str,
style: Optional[str] = None,
temperature: float = 0.7
) -> str:
"""안전 점검 및 품질 모니터링이 포함된 응답을 생성합니다."""
try:
# 초기 응답 생성
result, call = generate_text.call(
prompt=prompt,
style=style,
temperature=temperature
)
# 안전 점검 적용 (가드레일)
safety = await call.apply_scorer(toxicity_guard)
if safety.result["flagged"]:
return f"해당 콘텐츠를 생성할 수 없습니다: {safety.result['reason']}"
# 샘플 품질 모니터링 (요청의 10%)
if random.random() < 0.1:
# 품질 점검을 병렬로 실행
await asyncio.gather(
call.apply_scorer(quality_monitor),
call.apply_scorer(relevance_monitor)
)
return result
except Exception as e:
# 에러 로그 및 사용자 친화적 메시지 반환
print(f"Generation failed: {e}")
return "죄송합니다. 오류가 발생했습니다. 다시 시도해 주세요."
# 사용 예시
async def main():
# 기본 사용법
response = await generate_safe_response("이야기를 하나 들려줘")
print(f"Basic response: {response}")
# 모든 파라미터를 사용한 고급 사용법
response = await generate_safe_response(
prompt="이야기를 하나 들려줘",
style="noir",
temperature=0.8
)
print(f"Styled response: {response}")
- 적절한 Scorer 초기화 및 에러 처리
- 가드레일과 모니터의 혼합 사용
- 병렬 스코어링을 통한 비동기 오퍼레이션
- 프로덕션 환경에 적합한 에러 처리 및 로깅
다음 단계