AgentChat) 、マルチエージェントのコア機能 (Core) 、外部サービスとのインテグレーション (Extensions) を提供します。さらに、AutoGen にはノーコードでエージェントをプロトタイピングできる Studio も用意されています。詳しくは、AutoGen 公式ドキュメントをご覧ください。
このガイドは、AutoGen の基本的な理解があることを前提としています。
autogen_agentchat、autogen_core、autogen_ext 内のやり取りが自動的にトラッキングされます。このガイドでは、AutoGen で Weave を設定する方法を説明し、モデルクライアント、ツールを備えたエージェント、グループチャット、メモリ、RAG ワークフロー、エージェントランタイム、逐次ワークフロー、コードエグゼキューターを扱う具体例を紹介します。最後には、AutoGen アプリケーションの詳細なトレースを Weave で取得し、エージェントの動作をデバッグしたり、LLM の使用状況を監視したり、複雑なワークフロー全体でエージェントがどのように相互作用するかを把握したりできるようになります。
前提条件
pip install autogen_agentchat "autogen_ext[openai,anthropic]" weave
import os
os.environ["OPENAI_API_KEY"] = "[YOUR-OPENAI-API-KEY]"
os.environ["ANTHROPIC_API_KEY"] = "[YOUR-ANTHROPIC-API-KEY]"
基本設定
import weave
weave.init("autogen-demo")
autogen-demo project に送信するように設定され、以降、スクリプト内の AutoGen のアクティビティは Weave によって自動的に取得されます。
モデルクライアントのトレース
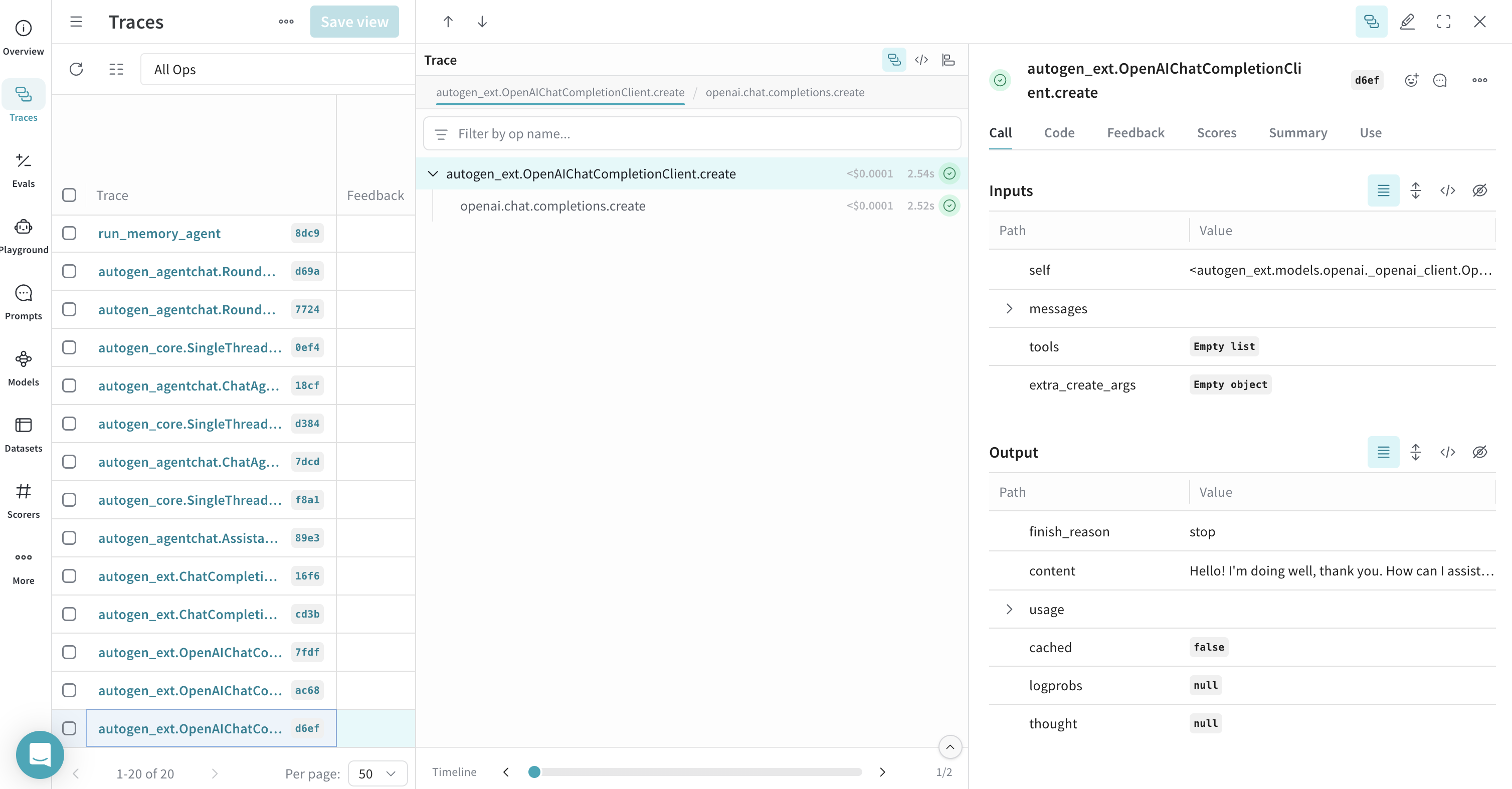
クライアントの create Call のトレース
OpenAIChatCompletionClient に対する Call をトレースする方法を示します。
import asyncio
from autogen_core.models import UserMessage
from autogen_ext.models.openai import OpenAIChatCompletionClient
# from autogen_ext.models.anthropic import AnthropicChatCompletionClient(Anthropicを使用する場合)
async def simple_client_call(model_name = "gpt-4o"):
model_client = OpenAIChatCompletionClient(
model=model_name,
)
# Alternatively, you can use Anthropic or other model clients
# model_client = AnthropicChatCompletionClient(
# model="claude-3-haiku-20240307"
# )
response = await model_client.create(
[UserMessage(content="Hello, how are you?", source="user")]
)
print(response)
asyncio.run(simple_client_call())
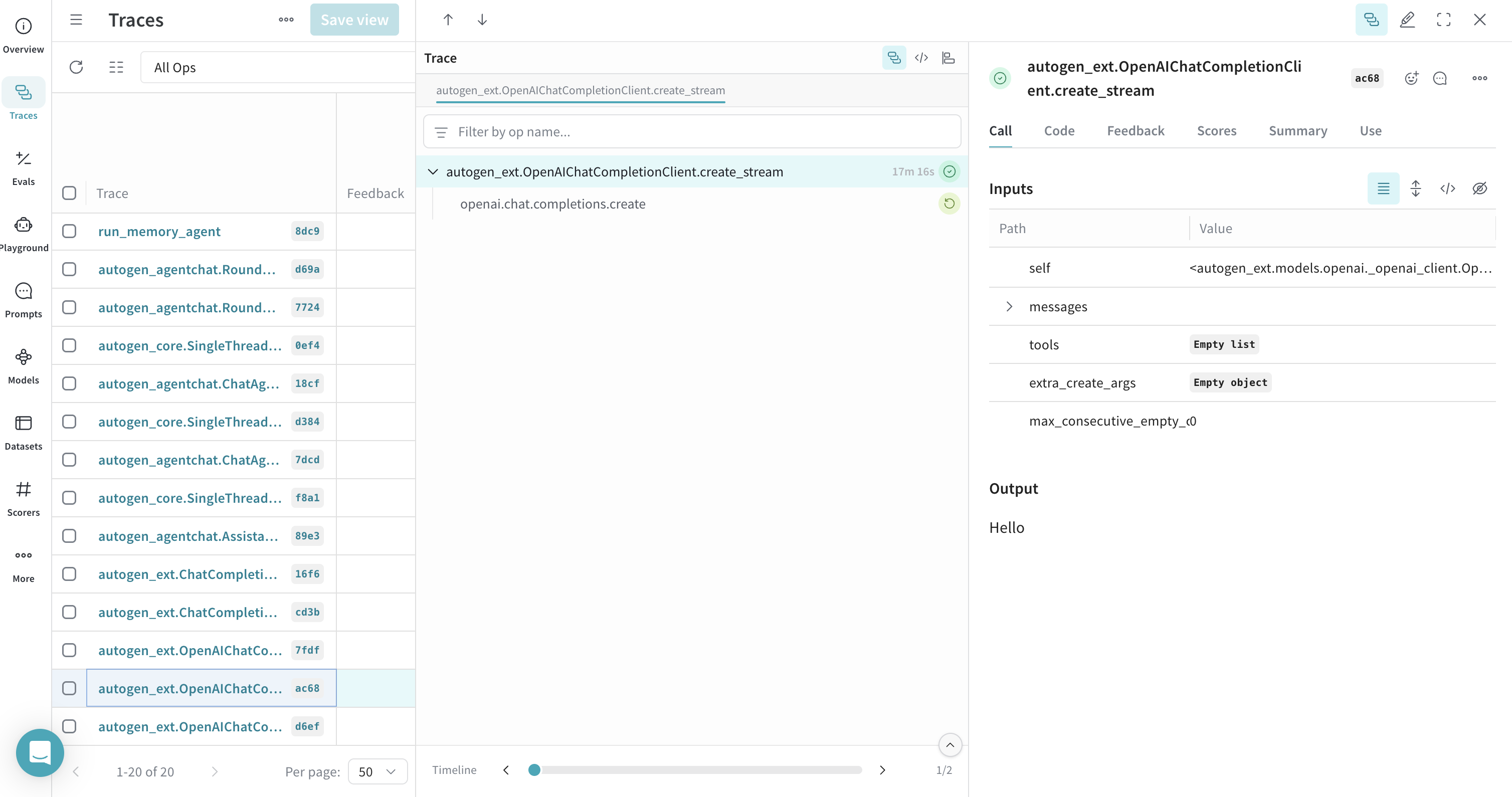
ストリーミングを使用したクライアントの create call のトレース
async def simple_client_call_stream(model_name = "gpt-4o"):
openai_model_client = OpenAIChatCompletionClient(model=model_name)
async for item in openai_model_client.create_stream(
[UserMessage(content="Hello, how are you?", source="user")]
):
print(item, flush=True, end="")
asyncio.run(simple_client_call_stream())
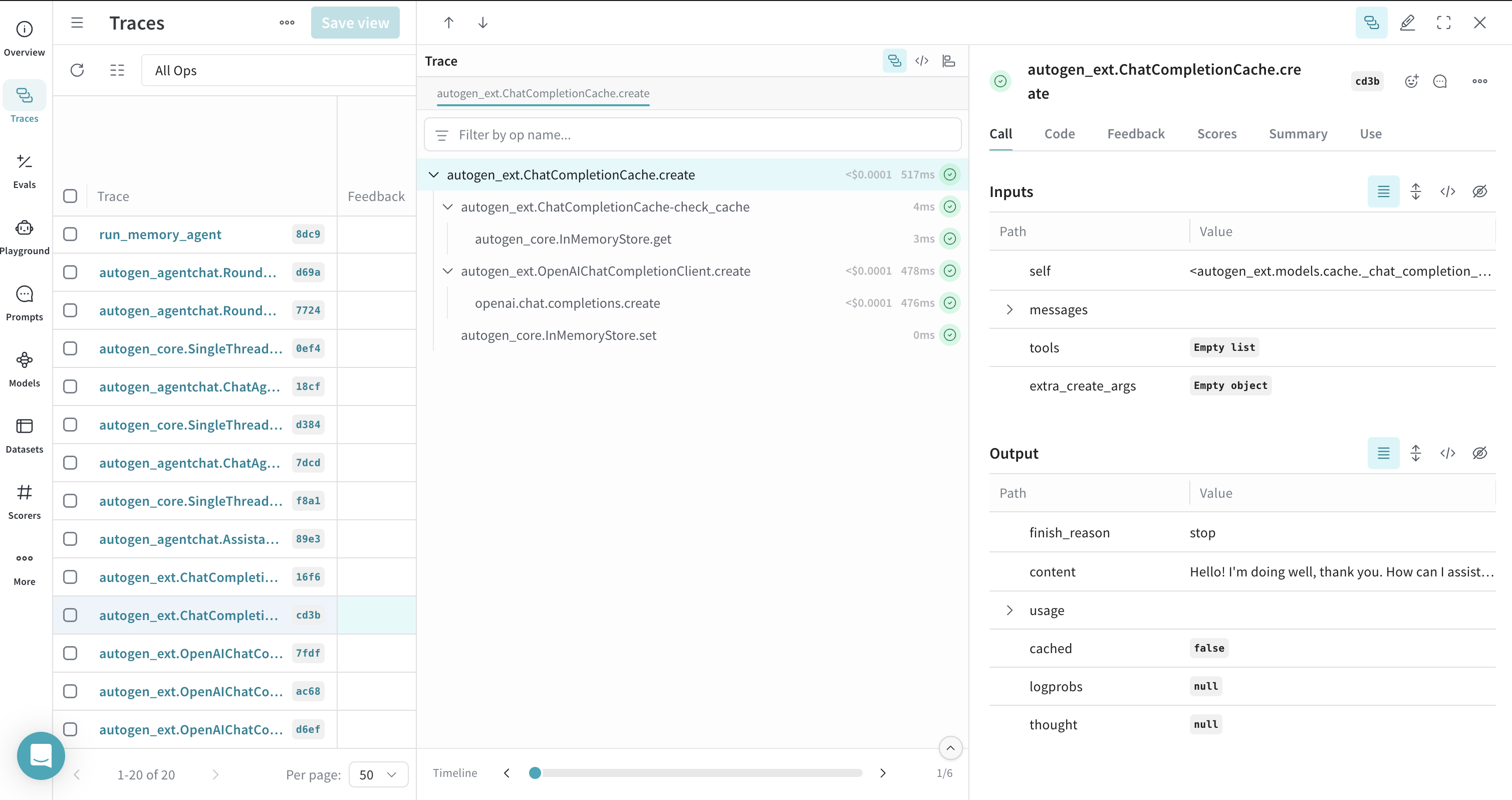
キャッシュされたクライアント Call のトレース
ChatCompletionCache を使用でき、Weave はこれらのやり取りをトレースして、応答がキャッシュから返されたものか、新しい Call によるものかを表示します。
from autogen_ext.models.cache import ChatCompletionCache
async def run_cache_client(model_name = "gpt-4o"):
openai_model_client = OpenAIChatCompletionClient(model=model_name)
cache_client = ChatCompletionCache(openai_model_client,)
response = await cache_client.create(
[UserMessage(content="Hello, how are you?", source="user")]
)
print(response) # OpenAIからの応答を出力するはずです
response = await cache_client.create(
[UserMessage(content="Hello, how are you?", source="user")]
)
print(response) # キャッシュされた応答を出力するはずです
asyncio.run(run_cache_client())
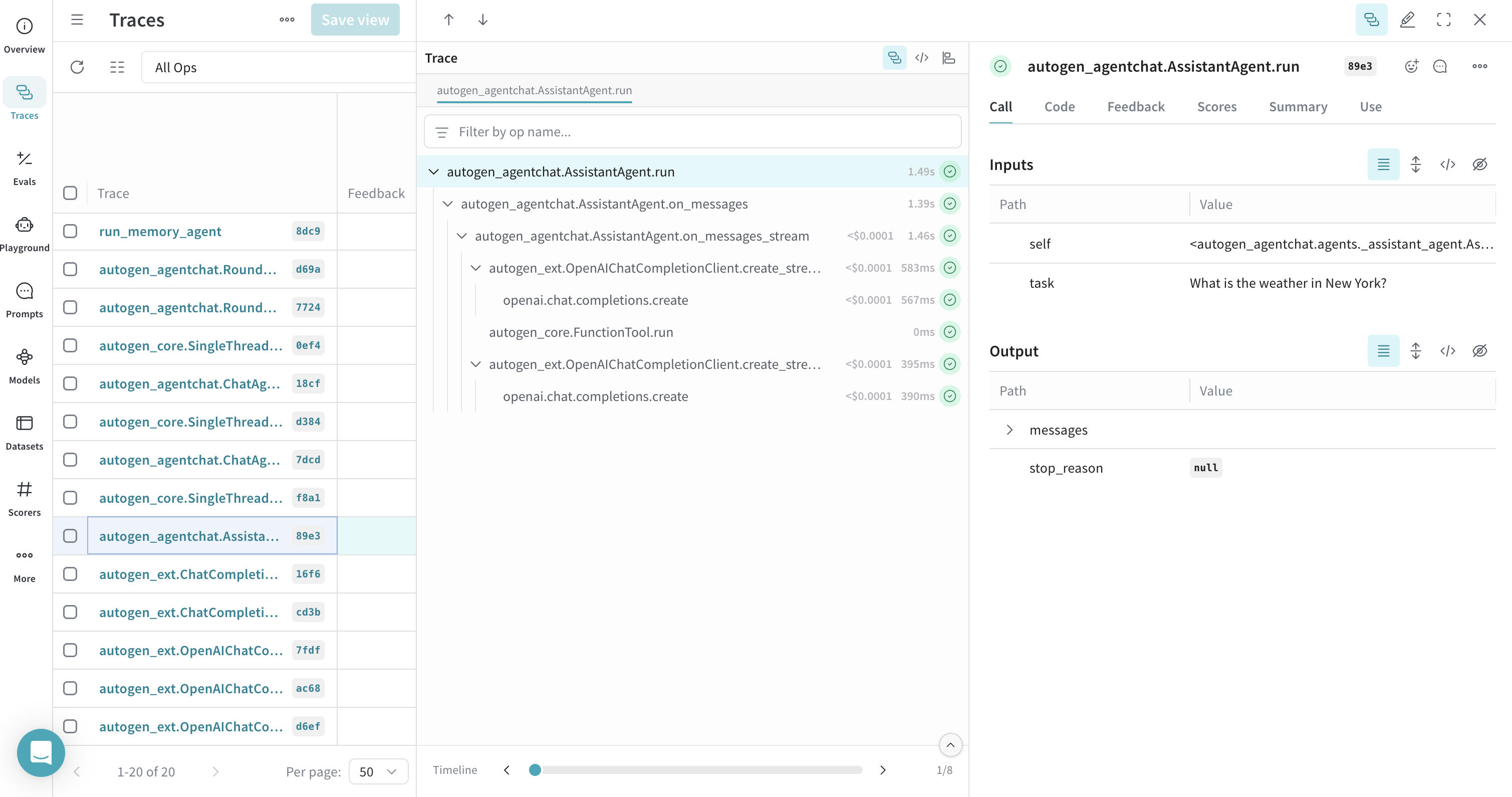
ツールCallを行うエージェントのトレース
AssistantAgent に関連付けます。
from autogen_agentchat.agents import AssistantAgent
async def get_weather(city: str) -> str:
return f"The weather in {city} is 73 degrees and Sunny."
async def run_agent_with_tools(model_name = "gpt-4o"):
model_client = OpenAIChatCompletionClient(model=model_name)
agent = AssistantAgent(
name="weather_agent",
model_client=model_client,
tools=[get_weather],
system_message="You are a helpful assistant.",
reflect_on_tool_use=True,
)
# コンソールへのストリーミング出力の場合:
# await Console(agent.run_stream(task="What is the weather in New York?"))
res = await agent.run(task="What is the weather in New York?")
print(res)
await model_client.close()
asyncio.run(run_agent_with_tools())
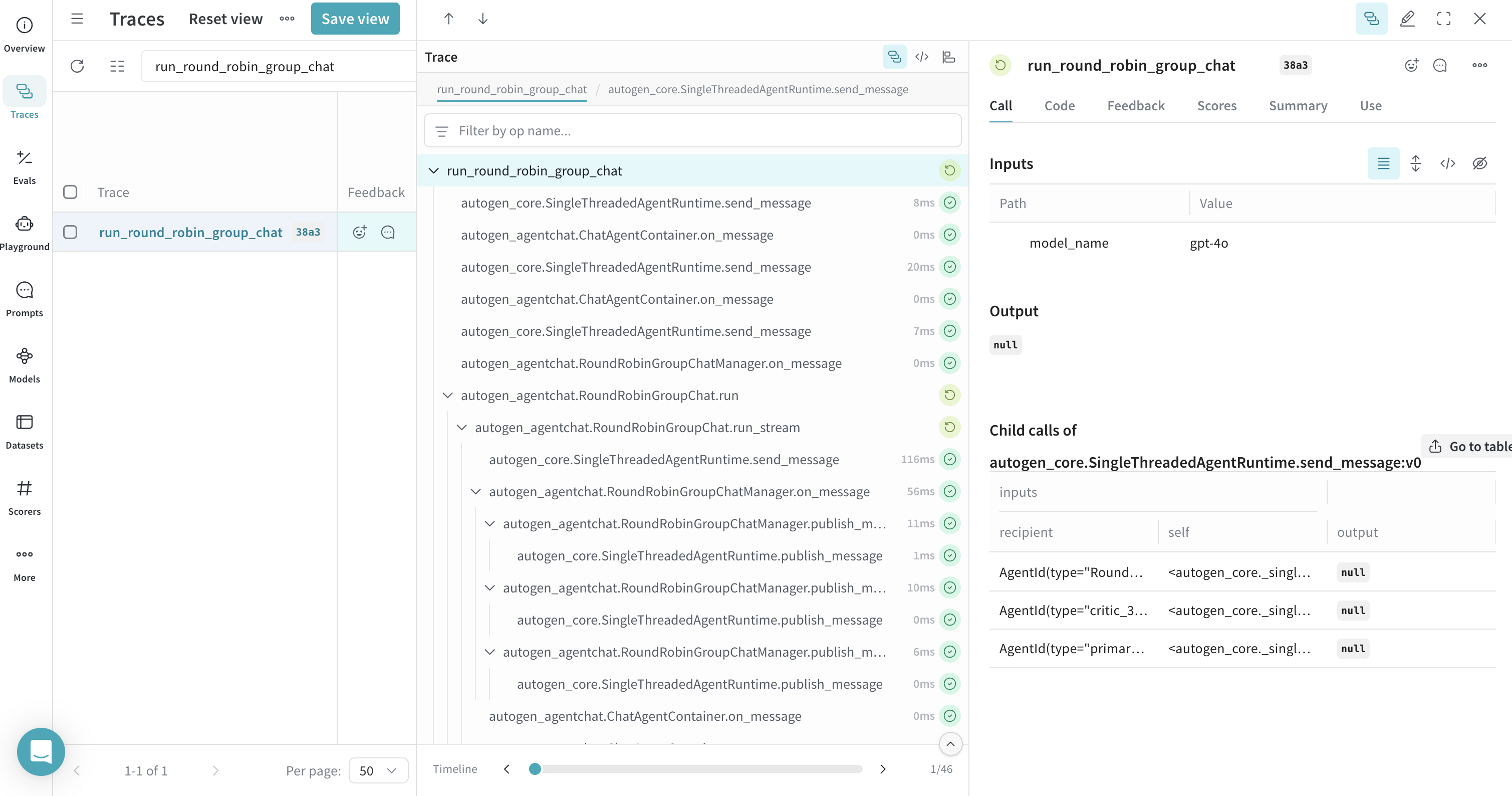
ラウンドロビン GroupChat のトレース
RoundRobinGroupChat などのグループチャット内のやり取りをトレースするため、エージェント間の会話の流れを追跡できます。確認しやすいように、すべてのエージェントのターンを単一の親トレースの下にまとめるには、グループチャット関数を @weave.op でラップします。この手順は任意ですが、推奨されます。
from autogen_agentchat.conditions import TextMentionTermination
from autogen_agentchat.teams import RoundRobinGroupChat
# グループチャット全体をトレースしたいため、ここで weave op を追加します
# これは完全に任意ですが、使用を強くお勧めします
@weave.op
async def run_round_robin_group_chat(model_name="gpt-4o"):
model_client = OpenAIChatCompletionClient(model=model_name)
primary_agent = AssistantAgent(
"primary",
model_client=model_client,
system_message="You are a helpful AI assistant.",
)
critic_agent = AssistantAgent(
"critic",
model_client=model_client,
system_message="Provide constructive feedback. Respond with 'APPROVE' to when your feedbacks are addressed.",
)
text_termination = TextMentionTermination("APPROVE")
team = RoundRobinGroupChat(
[primary_agent, critic_agent], termination_condition=text_termination
)
await team.reset()
# コンソールにストリーミング出力する場合:
# await Console(team.run_stream(task="Write a short poem about the fall season."))
result = await team.run(task="Write a short poem about the fall season.")
print(result)
await model_client.close()
asyncio.run(run_round_robin_group_chat())
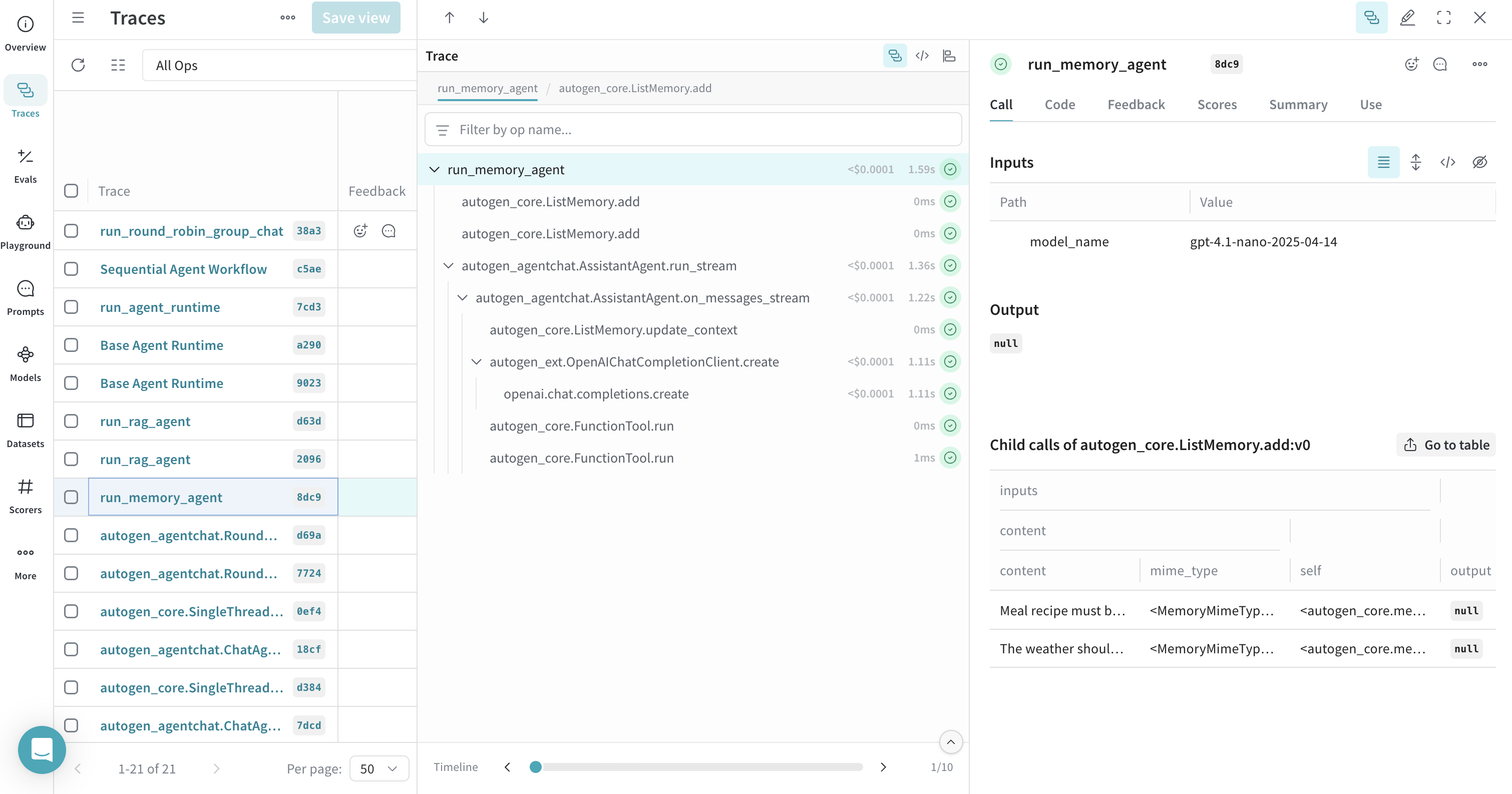
メモリのトレース
@weave.op() を使用すると、メモリ操作を 1 つのトレースにまとめて可読性を高められます。これにより、メモリの追加と取得の呼び出しが、それらを使用するエージェントの run と一緒に表示されます。
from autogen_core.memory import ListMemory, MemoryContent, MemoryMimeType
# ここでweave opを追加するのは、メモリのaddとgetの呼び出しを
# 単一のトレースにまとめて追跡したいためです
# 完全にオプションですが、使用することを強くお勧めします
@weave.op
async def run_memory_agent(model_name="gpt-4o"):
user_memory = ListMemory()
await user_memory.add(
MemoryContent(
content="The weather should be in metric units",
mime_type=MemoryMimeType.TEXT,
)
)
await user_memory.add(
MemoryContent(
content="Meal recipe must be vegan", mime_type=MemoryMimeType.TEXT
)
)
async def get_weather(city: str, units: str = "imperial") -> str:
if units == "imperial":
return f"The weather in {city} is 73 °F and Sunny."
elif units == "metric":
return f"The weather in {city} is 23 °C and Sunny."
else:
return f"Sorry, I don't know the weather in {city}."
model_client = OpenAIChatCompletionClient(model=model_name)
assistant_agent = AssistantAgent(
name="assistant_agent",
model_client=model_client,
tools=[get_weather],
memory=[user_memory],
)
# コンソールへのストリーミング出力を行う場合:
# stream = assistant_agent.run_stream(task="What is the weather in New York?")
# await Console(stream)
result = await assistant_agent.run(task="What is the weather in New York?")
print(result)
await model_client.close()
asyncio.run(run_memory_agent())
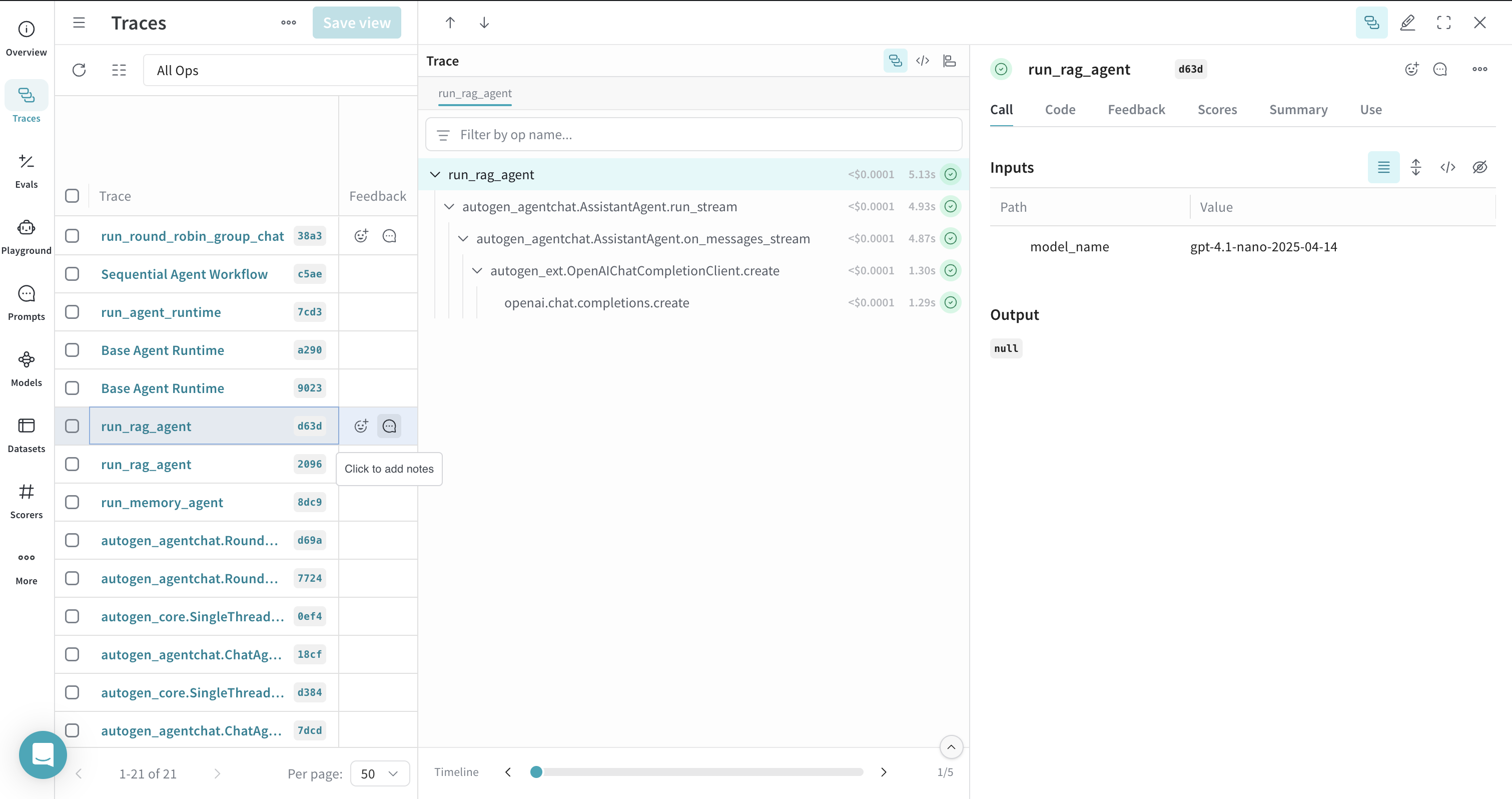
RAG ワークフローのトレース
ChromaDBVectorMemory のようなメモリシステムを使用したドキュメントのインデックス作成や取得を含む Retrieval Augmented Generation (RAG) ワークフローをトレースできます。インデックス作成、取得、その結果の LLM Call を 1 つのトレースにまとめて表示できるようにフロー全体を可視化するには、RAG プロセスを @weave.op() でデコレートします。
この RAG の例では
chromadb が必要です。pip install chromadb でインストールしてください。# !pip install -q chromadb
# 環境に chromadb がインストールされていることを確認してください: `pip install chromadb`
import re
from typing import List
import os
from pathlib import Path
import aiofiles
import aiohttp
from autogen_core.memory import Memory, MemoryContent, MemoryMimeType
from autogen_ext.memory.chromadb import (
ChromaDBVectorMemory,
PersistentChromaDBVectorMemoryConfig,
)
class SimpleDocumentIndexer:
def __init__(self, memory: Memory, chunk_size: int = 1500) -> None:
self.memory = memory
self.chunk_size = chunk_size
async def _fetch_content(self, source: str) -> str:
if source.startswith(("http://", "https://")):
async with aiohttp.ClientSession() as session:
async with session.get(source) as response:
return await response.text()
else:
async with aiofiles.open(source, "r", encoding="utf-8") as f:
return await f.read()
def _strip_html(self, text: str) -> str:
text = re.sub(r"<[^>]*>", " ", text)
text = re.sub(r"\\s+", " ", text)
return text.strip()
def _split_text(self, text: str) -> List[str]:
chunks: list[str] = []
for i in range(0, len(text), self.chunk_size):
chunk = text[i : i + self.chunk_size]
chunks.append(chunk.strip())
return chunks
async def index_documents(self, sources: List[str]) -> int:
total_chunks = 0
for source in sources:
try:
content = await self._fetch_content(source)
if "<" in content and ">" in content:
content = self._strip_html(content)
chunks = self._split_text(content)
for i, chunk in enumerate(chunks):
await self.memory.add(
MemoryContent(
content=chunk,
mime_type=MemoryMimeType.TEXT,
metadata={"source": source, "chunk_index": i},
)
)
total_chunks += len(chunks)
except Exception as e:
print(f"Error indexing {source}: {str(e)}")
return total_chunks
@weave.op
async def run_rag_agent(model_name="gpt-4o"):
rag_memory = ChromaDBVectorMemory(
config=PersistentChromaDBVectorMemoryConfig(
collection_name="autogen_docs",
persistence_path=os.path.join(str(Path.home()), ".chromadb_autogen_weave"),
k=3,
score_threshold=0.4,
)
)
# await rag_memory.clear() # 既存のメモリをクリアする場合はコメントアウトを解除してください
async def index_autogen_docs() -> None:
indexer = SimpleDocumentIndexer(memory=rag_memory)
sources = [
"https://raw.githubusercontent.com/microsoft/autogen/main/README.md",
"https://microsoft.github.io/autogen/dev/user-guide/agentchat-user-guide/tutorial/agents.html",
]
chunks: int = await indexer.index_documents(sources)
print(f"Indexed {chunks} chunks from {len(sources)} AutoGen documents")
# コレクションが空の場合、または再インデックスしたい場合のみ実行します
# デモ目的では、毎回インデックスを作成するか、インデックス済みかどうかを確認することができます。
# この例では run のたびにインデックスを試みます。チェック処理の追加を検討してください。
await index_autogen_docs()
model_client = OpenAIChatCompletionClient(model=model_name)
rag_assistant = AssistantAgent(
name="rag_assistant",
model_client=model_client,
memory=[rag_memory],
)
# コンソールへのストリーミング出力を行う場合:
# stream = rag_assistant.run_stream(task="What is AgentChat?")
# await Console(stream)
result = await rag_assistant.run(task="What is AgentChat?")
print(result)
await rag_memory.close()
await model_client.close()
asyncio.run(run_rag_agent())
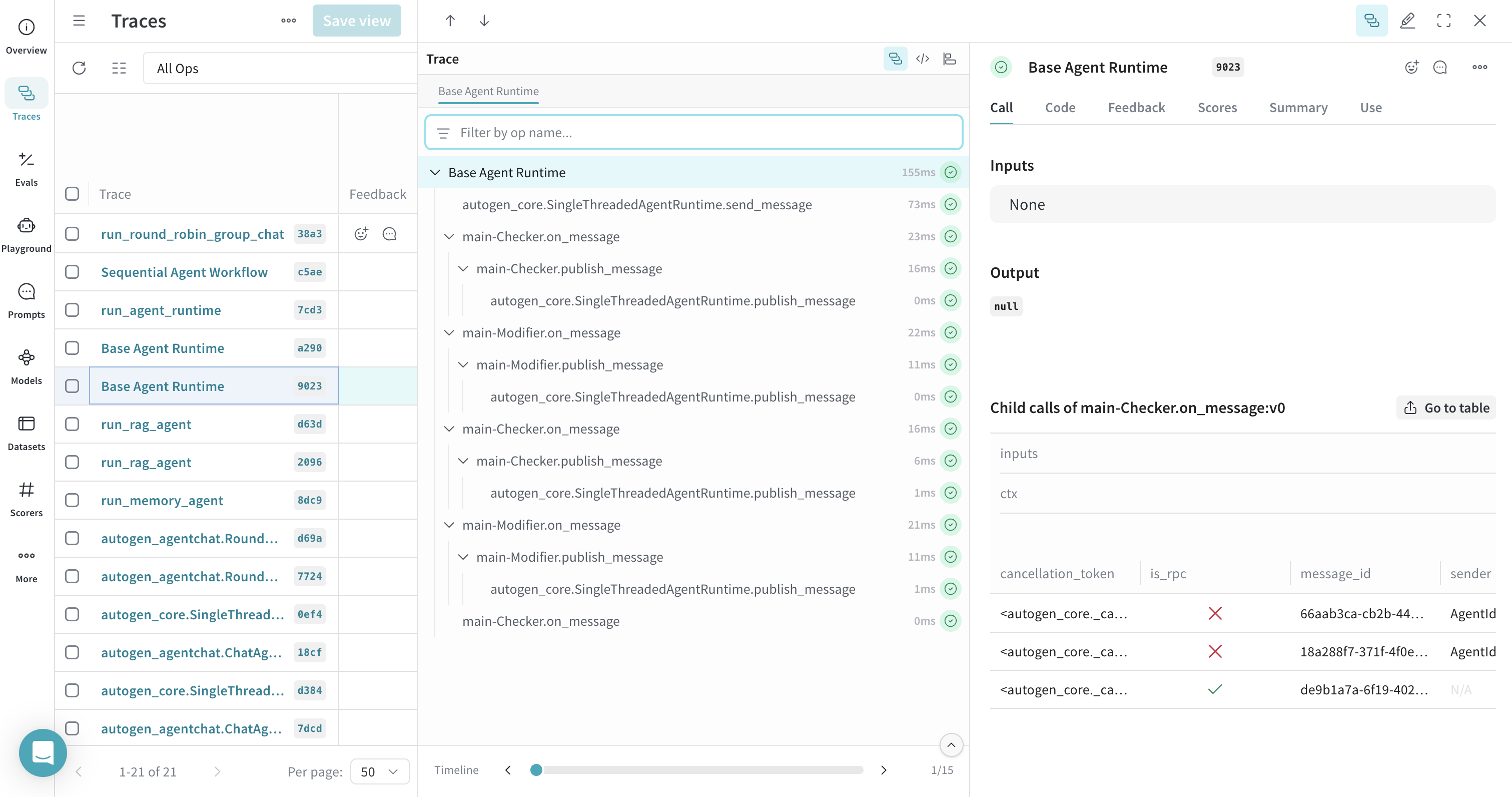
エージェントランタイムのトレース
SingleThreadedAgentRuntime など、AutoGen のエージェントランタイム内のオペレーションをトレースできます。関連するトレースをグループ化して、ランタイムの実行中に呼び出されるメッセージハンドラーの完全なシーケンスを確認できるようにするには、ランタイムの実行関数を @weave.op() でラップしてください。
from dataclasses import dataclass
from typing import Callable
from autogen_core import (
DefaultTopicId,
MessageContext,
RoutedAgent,
default_subscription,
message_handler,
AgentId,
SingleThreadedAgentRuntime
)
@dataclass
class Message:
content: int
@default_subscription
class Modifier(RoutedAgent):
def __init__(self, modify_val: Callable[[int], int]) -> None:
super().__init__("A modifier agent.")
self._modify_val = modify_val
@message_handler
async def handle_message(self, message: Message, ctx: MessageContext) -> None:
val = self._modify_val(message.content)
print(f"{'-'*80}\\nModifier:\\nModified {message.content} to {val}")
await self.publish_message(Message(content=val), DefaultTopicId())
@default_subscription
class Checker(RoutedAgent):
def __init__(self, run_until: Callable[[int], bool]) -> None:
super().__init__("A checker agent.")
self._run_until = run_until
@message_handler
async def handle_message(self, message: Message, ctx: MessageContext) -> None:
if not self._run_until(message.content):
print(f"{'-'*80}\\nChecker:\\n{message.content} passed the check, continue.")
await self.publish_message(
Message(content=message.content), DefaultTopicId()
)
else:
print(f"{'-'*80}\\nChecker:\\n{message.content} failed the check, stopping.")
# エージェントランタイム全体の呼び出しを単一のトレースで
# トレースするために、ここにweave opを追加します
# 任意ですが、使用することを強くお勧めします
@weave.op
async def run_agent_runtime() -> None:
runtime = SingleThreadedAgentRuntime()
await Modifier.register(
runtime,
"modifier",
lambda: Modifier(modify_val=lambda x: x - 1),
)
await Checker.register(
runtime,
"checker",
lambda: Checker(run_until=lambda x: x <= 1),
)
runtime.start()
await runtime.send_message(Message(content=3), AgentId("checker", "default"))
await runtime.stop_when_idle()
asyncio.run(run_agent_runtime())
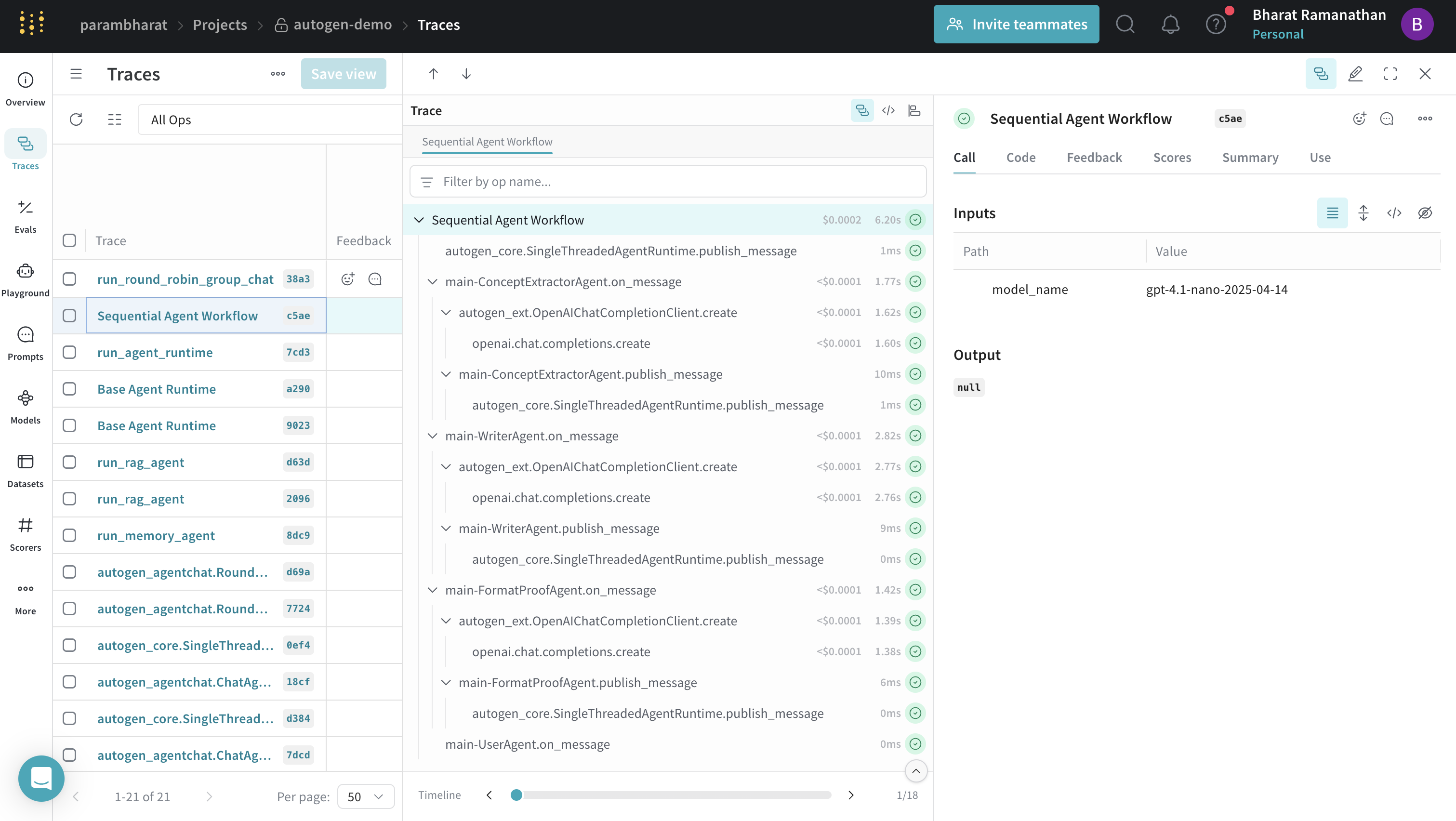
逐次ワークフローのトレース
@weave.op() を使用すると、ワークフロー全体の高レベルなトレースを提供できます。これにより、各エージェントの寄与は単一の親Callの下にネストされます。次の例では、コンセプト抽出、ライター、整形と校正を行うエージェント、ユーザーエージェントをチェーンして、洗練されたマーケティングコピーを生成します。
from autogen_core import TopicId, type_subscription
from autogen_core.models import ChatCompletionClient, SystemMessage, UserMessage
@dataclass
class WorkflowMessage:
content: str
concept_extractor_topic_type = "ConceptExtractorAgent"
writer_topic_type = "WriterAgent"
format_proof_topic_type = "FormatProofAgent"
user_topic_type = "User"
@type_subscription(topic_type=concept_extractor_topic_type)
class ConceptExtractorAgent(RoutedAgent):
def __init__(self, model_client: ChatCompletionClient) -> None:
super().__init__("コンセプト抽出エージェント。")
self._system_message = SystemMessage(
content=(
"あなたはマーケティングアナリストです。プロダクトの説明文をもとに、以下を特定してください:\n"
"- 主な機能\n"
"- ターゲットオーディエンス\n"
"- 独自の強み\n\n"
)
)
self._model_client = model_client
@message_handler
async def handle_user_description(self, message: WorkflowMessage, ctx: MessageContext) -> None:
prompt = f"プロダクトの説明: {message.content}"
llm_result = await self._model_client.create(
messages=[self._system_message, UserMessage(content=prompt, source=self.id.key)],
cancellation_token=ctx.cancellation_token,
)
response = llm_result.content
assert isinstance(response, str)
print(f"{'-'*80}\\n{self.id.type}:\\n{response}")
await self.publish_message(
WorkflowMessage(response), topic_id=TopicId(writer_topic_type, source=self.id.key)
)
@type_subscription(topic_type=writer_topic_type)
class WriterAgent(RoutedAgent):
def __init__(self, model_client: ChatCompletionClient) -> None:
super().__init__("ライターエージェント。")
self._system_message = SystemMessage(
content=(
"あなたはマーケティングコピーライターです。機能、ターゲットオーディエンス、独自の強みを説明するテキストをもとに、"
"これらのポイントを強調した説得力のあるマーケティングコピー(ニュースレターのセクションなど)を作成してください。"
"出力は短く(約150語)、コピーのみを1つのテキストブロックとして出力してください。"
)
)
self._model_client = model_client
@message_handler
async def handle_intermediate_text(self, message: WorkflowMessage, ctx: MessageContext) -> None:
prompt = f"以下はプロダクトに関する情報です:\\n\\n{message.content}"
llm_result = await self._model_client.create(
messages=[self._system_message, UserMessage(content=prompt, source=self.id.key)],
cancellation_token=ctx.cancellation_token,
)
response = llm_result.content
assert isinstance(response, str)
print(f"{'-'*80}\\n{self.id.type}:\\n{response}")
await self.publish_message(
WorkflowMessage(response), topic_id=TopicId(format_proof_topic_type, source=self.id.key)
)
@type_subscription(topic_type=format_proof_topic_type)
class FormatProofAgent(RoutedAgent):
def __init__(self, model_client: ChatCompletionClient) -> None:
super().__init__("フォーマット&校正エージェント。")
self._system_message = SystemMessage(
content=(
"あなたは編集者です。下書きのコピーをもとに、文法を修正し、明瞭さを向上させ、一貫したトーンを確保し、"
"フォーマットを整えて洗練させてください。改善した最終コピーを1つのテキストブロックとして出力してください。"
)
)
self._model_client = model_client
@message_handler
async def handle_intermediate_text(self, message: WorkflowMessage, ctx: MessageContext) -> None:
prompt = f"下書きコピー:\\n{message.content}."
llm_result = await self._model_client.create(
messages=[self._system_message, UserMessage(content=prompt, source=self.id.key)],
cancellation_token=ctx.cancellation_token,
)
response = llm_result.content
assert isinstance(response, str)
print(f"{'-'*80}\\n{self.id.type}:\\n{response}")
await self.publish_message(
WorkflowMessage(response), topic_id=TopicId(user_topic_type, source=self.id.key)
)
@type_subscription(topic_type=user_topic_type)
class UserAgent(RoutedAgent):
def __init__(self) -> None:
super().__init__("最終コピーをユーザーに出力するユーザーエージェント。")
@message_handler
async def handle_final_copy(self, message: WorkflowMessage, ctx: MessageContext) -> None:
print(f"\\n{'-'*80}\\n{self.id.type} が最終コピーを受信しました:\\n{message.content}")
# エージェントワークフロー全体を単一のトレースで追跡するために
# ここに weave op を追加しています
# 省略可能ですが、使用することを強くお勧めします
@weave.op(call_display_name="逐次エージェントワークフロー")
async def run_agent_workflow(model_name="gpt-4o"):
model_client = OpenAIChatCompletionClient(model=model_name)
runtime = SingleThreadedAgentRuntime()
await ConceptExtractorAgent.register(runtime, type=concept_extractor_topic_type, factory=lambda: ConceptExtractorAgent(model_client=model_client))
await WriterAgent.register(runtime, type=writer_topic_type, factory=lambda: WriterAgent(model_client=model_client))
await FormatProofAgent.register(runtime, type=format_proof_topic_type, factory=lambda: FormatProofAgent(model_client=model_client))
await UserAgent.register(runtime, type=user_topic_type, factory=lambda: UserAgent())
runtime.start()
await runtime.publish_message(
WorkflowMessage(
content="飲み物を24時間冷たく保つ、環境に優しいステンレス製ウォーターボトル"
),
topic_id=TopicId(concept_extractor_topic_type, source="default"),
)
await runtime.stop_when_idle()
await model_client.close()
asyncio.run(run_agent_workflow())
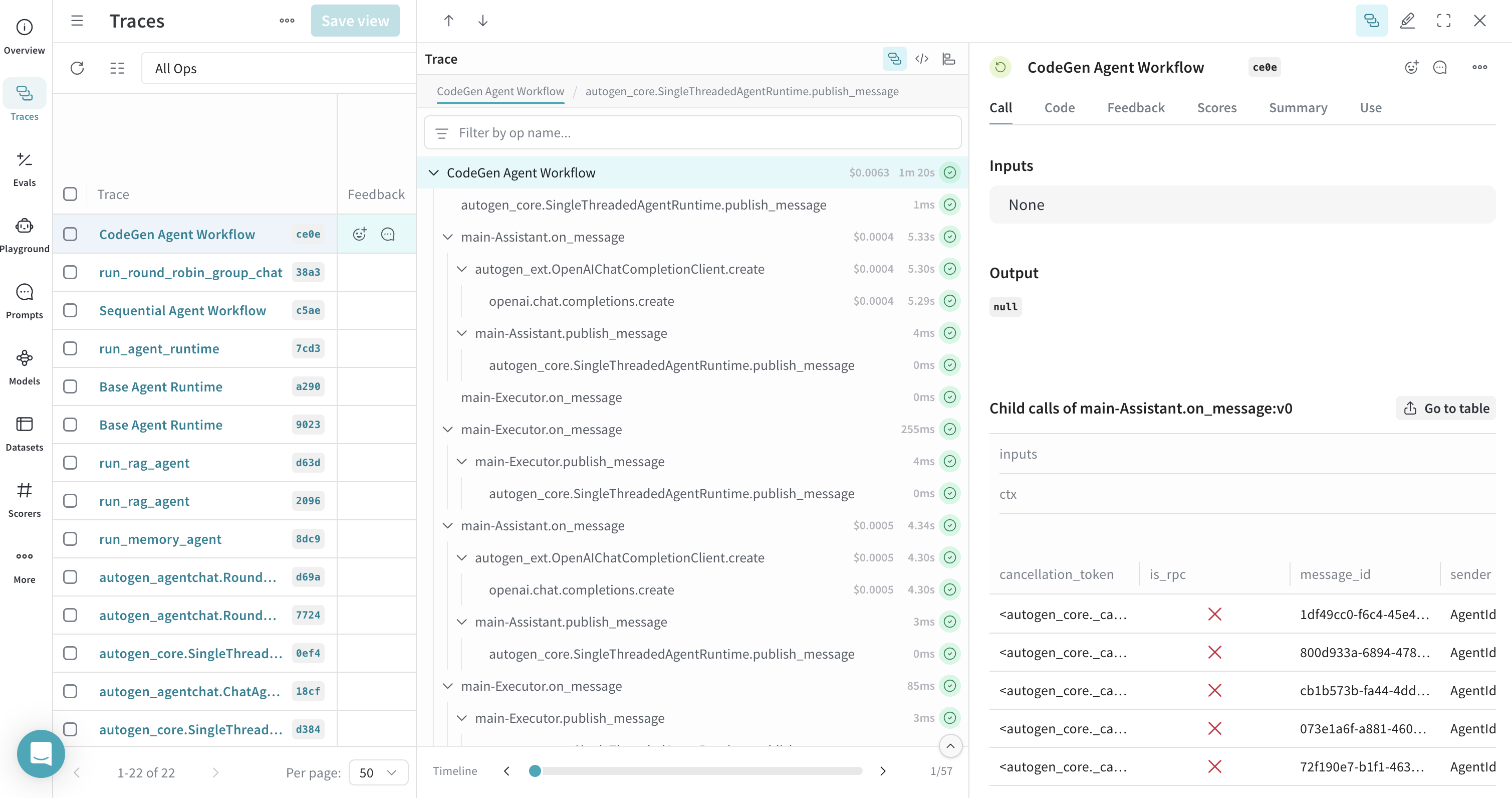
コードエグゼキュータのトレース
Docker が必要です
この例では Docker を使ってコードを実行するため、すべての環境で動作するとは限りません (たとえば、Colab 上で直接実行する場合など) 。この例を試す場合は、ローカルで Docker が実行されていることを確認してください。
import tempfile
from autogen_core import DefaultTopicId
from autogen_core.code_executor import CodeBlock, CodeExecutor
from autogen_core.models import (
AssistantMessage,
ChatCompletionClient,
LLMMessage,
SystemMessage,
UserMessage,
)
from autogen_ext.code_executors.docker import DockerCommandLineCodeExecutor
@dataclass
class CodeGenMessage:
content: str
@default_subscription
class Assistant(RoutedAgent):
def __init__(self, model_client: ChatCompletionClient) -> None:
super().__init__("An assistant agent.")
self._model_client = model_client
self._chat_history: List[LLMMessage] = [
SystemMessage(
content="""Write Python script in markdown block, and it will be executed.
Always save figures to file in the current directory. Do not use plt.show(). All code required to complete this task must be contained within a single response.""",
)
]
@message_handler
async def handle_message(self, message: CodeGenMessage, ctx: MessageContext) -> None:
self._chat_history.append(UserMessage(content=message.content, source="user"))
result = await self._model_client.create(self._chat_history)
print(f"\\n{'-'*80}\\nAssistant:\\n{result.content}")
self._chat_history.append(AssistantMessage(content=result.content, source="assistant"))
await self.publish_message(CodeGenMessage(content=result.content), DefaultTopicId())
def extract_markdown_code_blocks(markdown_text: str) -> List[CodeBlock]:
pattern = re.compile(r"```(?:\\s*([\\w\\+\\-]+))?\\n([\\s\\S]*?)```")
matches = pattern.findall(markdown_text)
code_blocks: List[CodeBlock] = []
for match in matches:
language = match[0].strip() if match[0] else ""
code_content = match[1]
code_blocks.append(CodeBlock(code=code_content, language=language))
return code_blocks
@default_subscription
class Executor(RoutedAgent):
def __init__(self, code_executor: CodeExecutor) -> None:
super().__init__("An executor agent.")
self._code_executor = code_executor
@message_handler
async def handle_message(self, message: CodeGenMessage, ctx: MessageContext) -> None:
code_blocks = extract_markdown_code_blocks(message.content)
if code_blocks:
result = await self._code_executor.execute_code_blocks(
code_blocks, cancellation_token=ctx.cancellation_token
)
print(f"\\n{'-'*80}\\nExecutor:\\n{result.output}")
await self.publish_message(CodeGenMessage(content=result.output), DefaultTopicId())
# ここにweave opを追加するのは、コード生成ワークフロー全体を
# 単一のトレースとして記録したいためです
# 任意ですが、使用することを強くお勧めします
@weave.op(call_display_name="CodeGen Agent Workflow")
async def run_codegen(model_name="gpt-4o"): # モデルを更新
work_dir = tempfile.mkdtemp()
runtime = SingleThreadedAgentRuntime()
# この例を実行する前にDockerが起動していることを確認してください
try:
async with DockerCommandLineCodeExecutor(work_dir=work_dir) as executor:
model_client = OpenAIChatCompletionClient(model=model_name)
await Assistant.register(runtime, "assistant", lambda: Assistant(model_client=model_client))
await Executor.register(runtime, "executor", lambda: Executor(executor))
runtime.start()
await runtime.publish_message(
CodeGenMessage(content="Create a plot of NVDA vs TSLA stock returns YTD from 2024-01-01."),
DefaultTopicId(),
)
await runtime.stop_when_idle()
await model_client.close()
except Exception as e:
print(f"Could not run Docker code executor example: {e}")
print("Please ensure Docker is installed and running.")
finally:
import shutil
shutil.rmtree(work_dir)
asyncio.run(run_codegen())
詳しくはこちら
- Weave:
- AutoGen: