はじめに
uv を使って Verifiers ライブラリをインストールします (ライブラリの作者が推奨しています) 。ライブラリのインストールには、次のいずれかのコマンドを使用してください。
ロールアウトをトレースして評価する
実験管理とトレースを使用してモデルをファインチューニングする
verifiers repository には、使い始めるのに役立つ、すぐに実行できる例が含まれています。
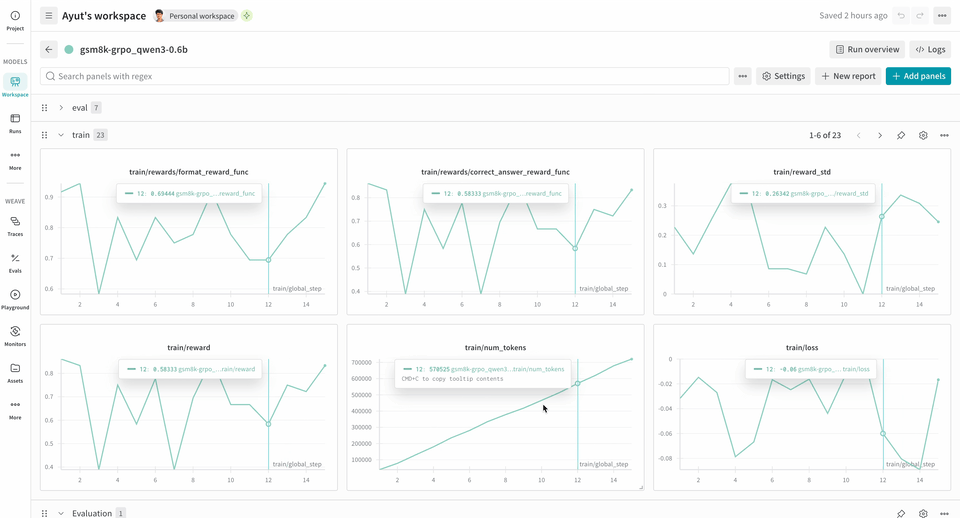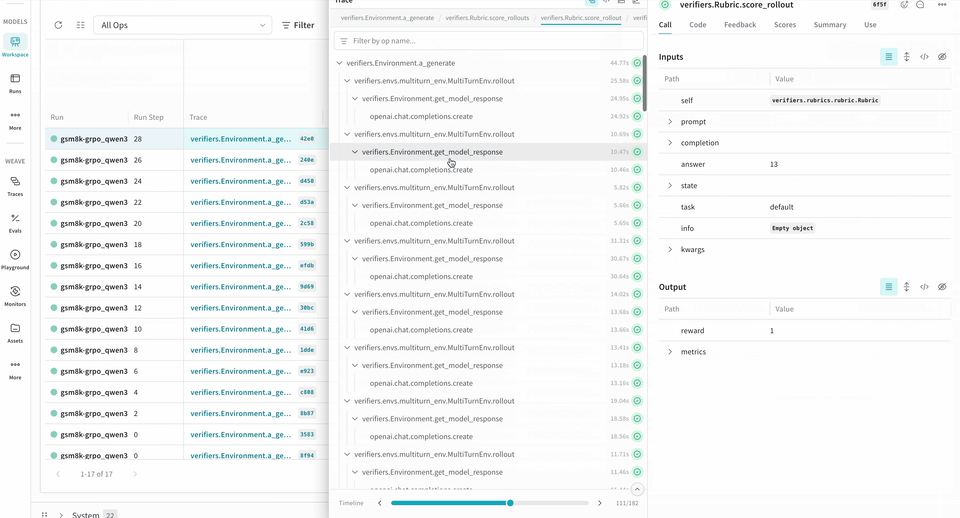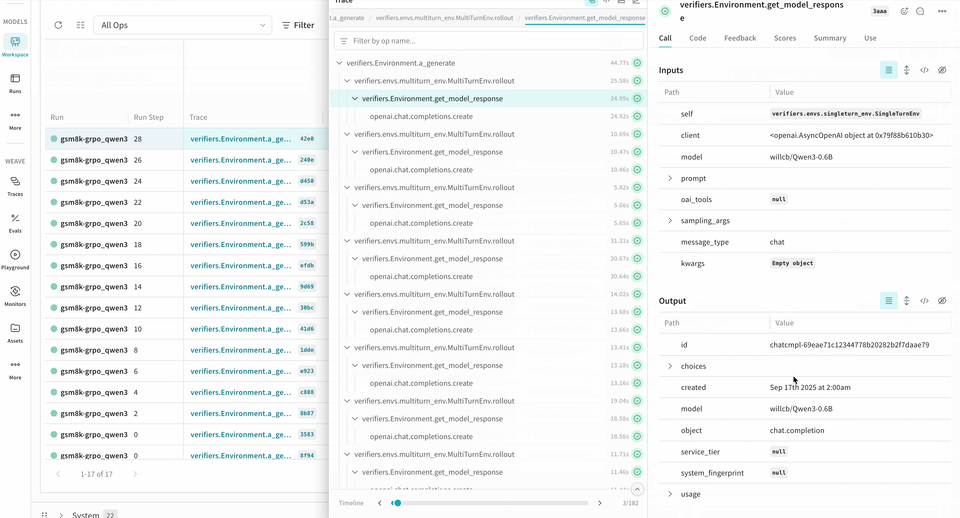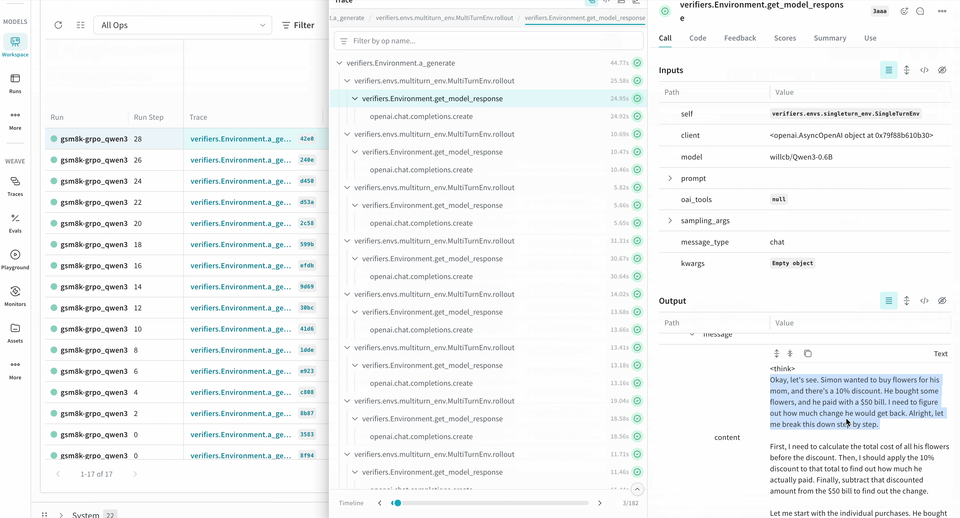
次の RL トレーニングパイプラインの例では、ローカルの推論サーバーを実行し、GSM8K データセットを使用してモデルをトレーニングします。モデルは数学の問題に対する答えを返し、トレーニングループは出力をスコアリングして、それに応じてモデルを更新します。W&B は損失、報酬、精度などのトレーニングメトリクスをログし、Weave は入力、出力、推論過程、スコアリングを取得します。
このパイプラインを使用するには:
- ソースからフレームワークをインストールします。次のコマンドでは、GitHub から Verifiers ライブラリと必要な依存関係をインストールします。
- 既成の環境をインストールします。次のコマンドで、事前設定済みの GSM8K トレーニング環境をインストールできます。
- モデルをトレーニングします。次のコマンドは、それぞれ推論サーバーとトレーニングループを起動します。このワークフロー例では、デフォルトで
report_to=wandbが設定されているため、wandb.init()を別途呼び出す必要はありません。W&B にメトリクスをログするには、このマシンを認証するよう求められます。
この例は 2xH100 での動作を確認しており、安定性を高めるために以下の環境変数を設定しました。これらの変数は、デバイスメモリ割り当てにおける CUDA Unified Memory (CuMem) を無効にします。
Environment.a_generate および Rubric.score_rollouts method の logprobs は省略されます。これにより、トレーニング用の元のデータはそのまま保持しつつ、ペイロードを小さくできます。