import asyncio
from llama_index.core.evaluation import CorrectnessEvaluator
eval_examples = [
{
"id": "0",
"query": "What programming language did Paul Graham learn to teach himself AI when he was in college?",
"ground_truth": "Paul Graham learned Lisp to teach himself AI when he was in college.",
},
{
"id": "1",
"query": "What was the name of the startup Paul Graham co-founded that was eventually acquired by Yahoo?",
"ground_truth": "The startup Paul Graham co-founded that was eventually acquired by Yahoo was called Viaweb.",
},
{
"id": "2",
"query": "What is the capital city of France?",
"ground_truth": "I cannot answer this question because no information was provided in the text.",
},
]
llm_judge = OpenAI(model="gpt-4", temperature=0.0)
evaluator = CorrectnessEvaluator(llm=llm_judge)
@weave.op()
def correctness_evaluator(query: str, ground_truth: str, output: dict):
result = evaluator.evaluate(
query=query, reference=ground_truth, response=output["response"]
)
return {"correctness": float(result.score)}
evaluation = weave.Evaluation(dataset=eval_examples, scorers=[correctness_evaluator])
rag_pipeline = SimpleRAGPipeline()
asyncio.run(evaluation.evaluate(rag_pipeline))
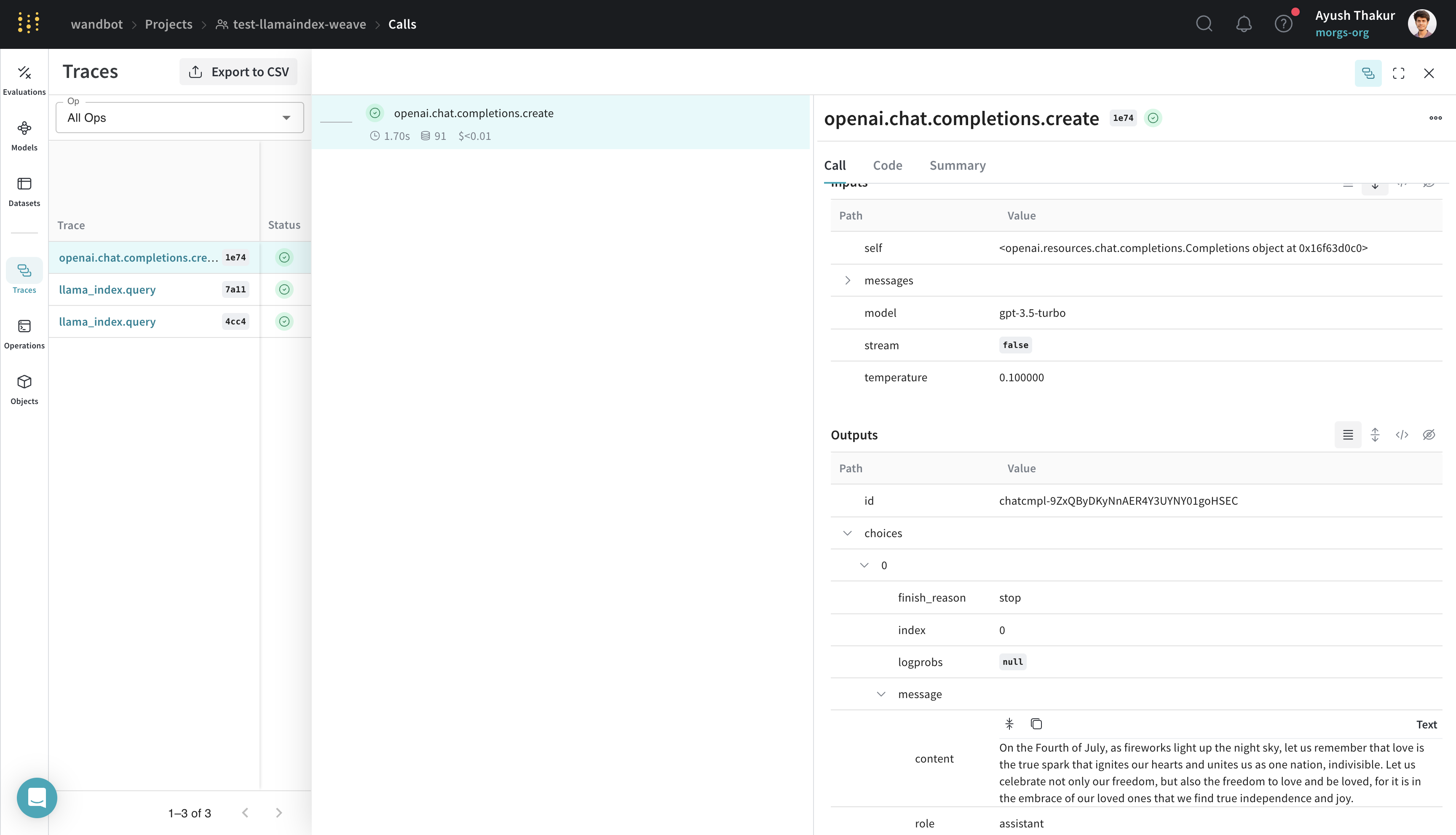
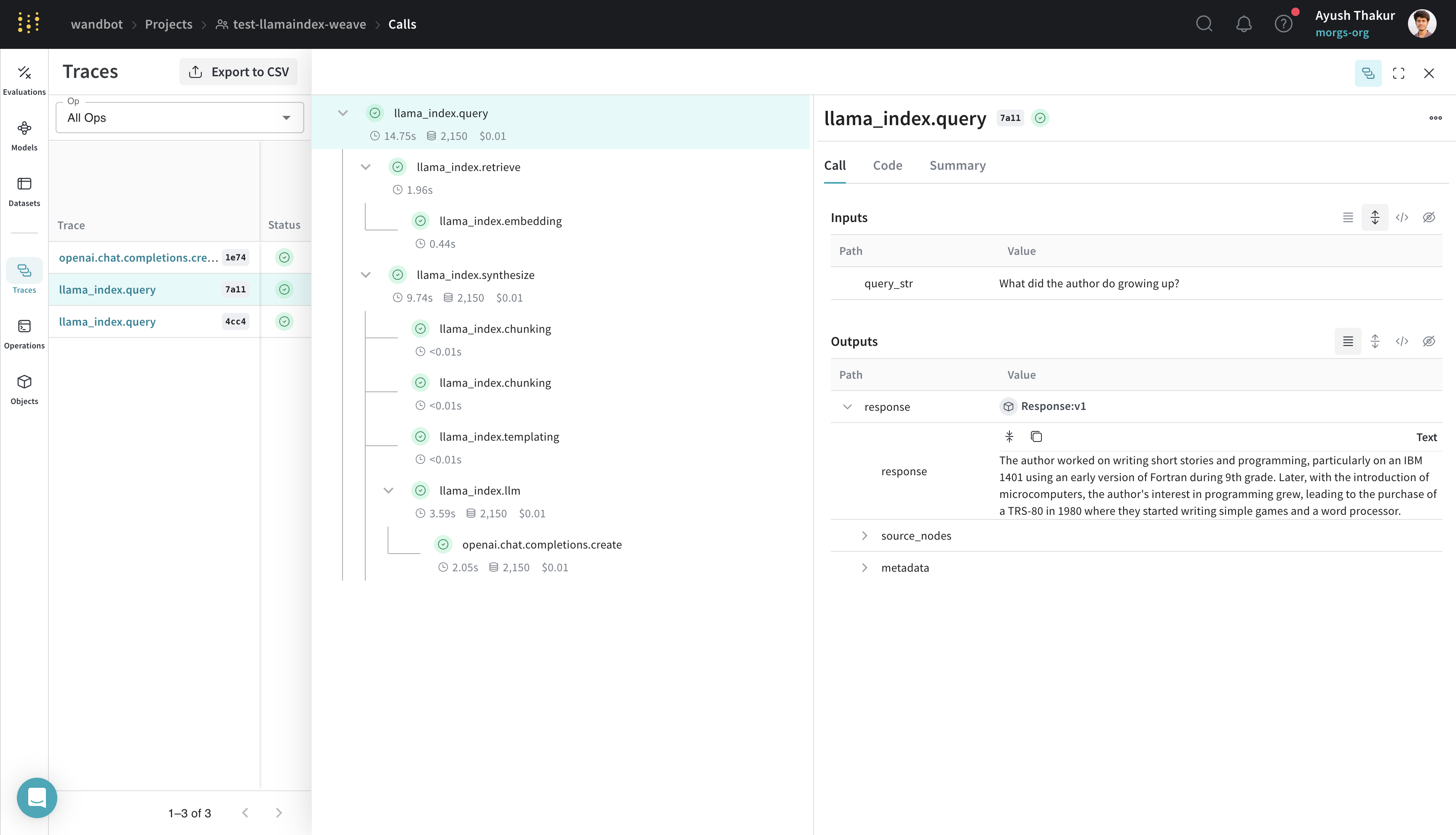
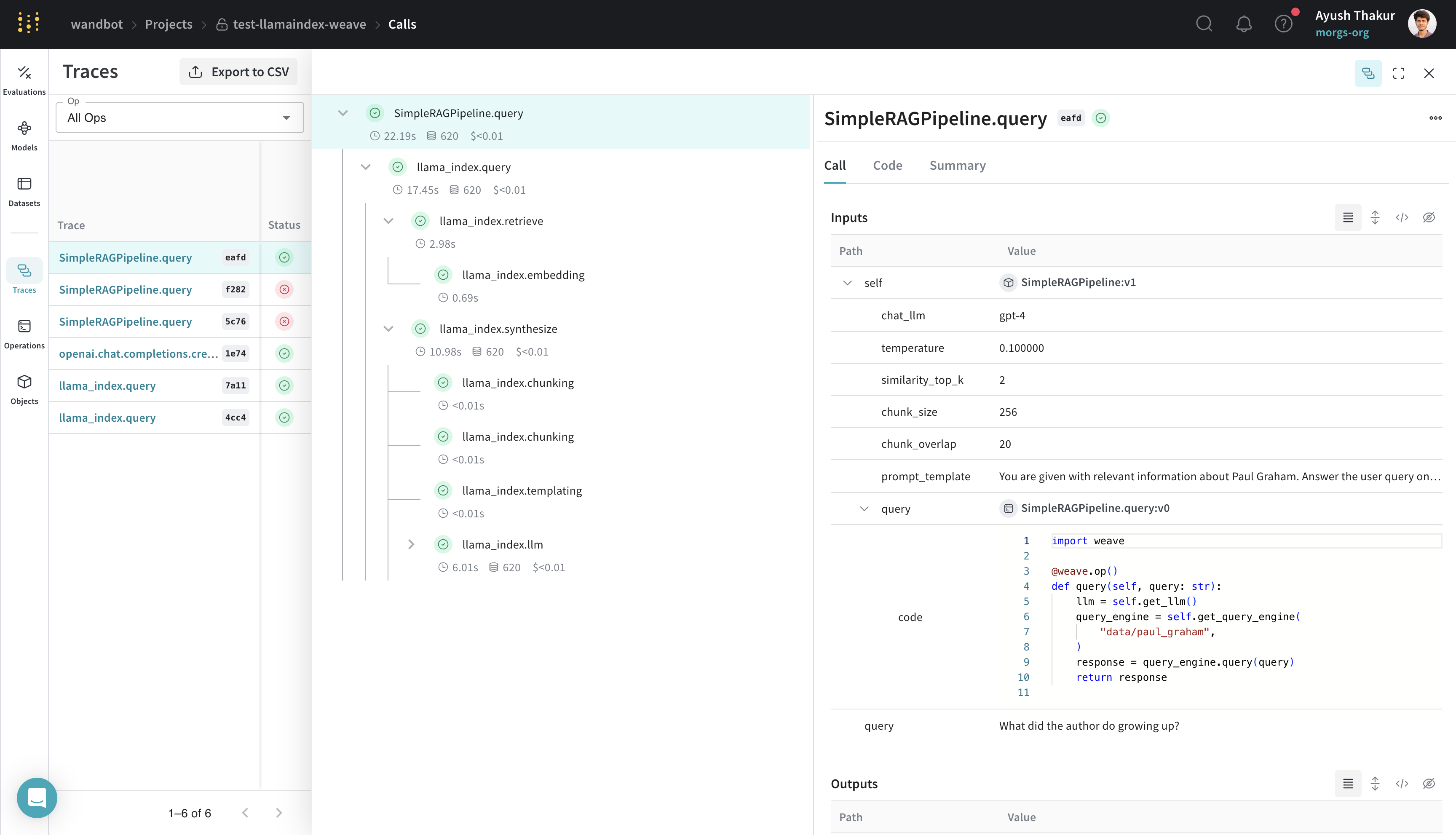
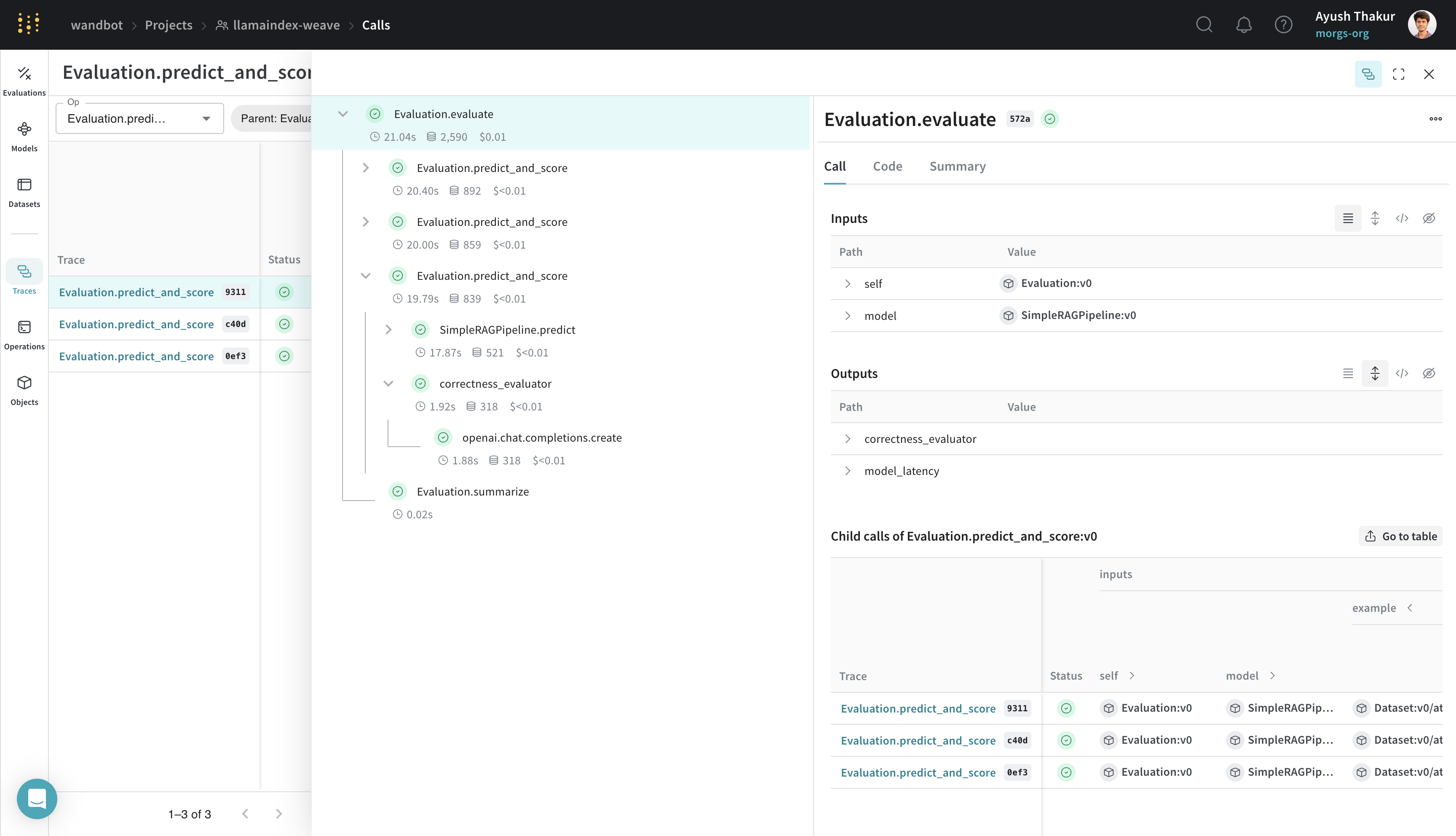 Weave を LlamaIndex とインテグレーションすることで、LLM アプリケーションの包括的なログすることとモニタリングが可能になり、評価を通じてデバッグとパフォーマンスの最適化を効率化できます。
Weave を LlamaIndex とインテグレーションすることで、LLM アプリケーションの包括的なログすることとモニタリングが可能になり、評価を通じてデバッグとパフォーマンスの最適化を効率化できます。