このページに掲載されているコードサンプルは、すべて Python で記述されています。
Google Colab で Hugging Face Hub と Weave を試す
面倒な設定なしで Hugging Face Hub と Weave を試してみたいですか? ここで紹介しているコードサンプルは、Google Colab 上の Jupyter Notebook として試せます。
概要
huggingface_hub Python ライブラリは、Hub でホストされているモデルに対して、複数のサービスをまたいで推論を実行できる統一インターフェースを提供します。これらのモデルは InferenceClient を使用して呼び出せます。
Weave は InferenceClient のトレースを自動的に取得します。トラッキングを開始するには、weave.init() を呼び出してから、通常どおりライブラリを使用します。
事前準備
-
Weave で
huggingface_hubを使用する前に、必要なライブラリをインストールするか、最新バージョンにアップグレードする必要があります。次のコマンドは、huggingface_hubとweaveをインストールし、すでにインストール済みの場合は最新バージョンにアップグレードします。また、インストール時の出力も抑制します。 -
Hugging Face Hub 上のモデルで 推論 を使用するには、User Access Token を設定します。トークンは Hugging Face Hub の Settings ページ で設定することも、プログラムから設定することもできます。次のコード例では、
HUGGINGFACE_TOKENの入力を求め、そのトークンを環境変数に設定します。
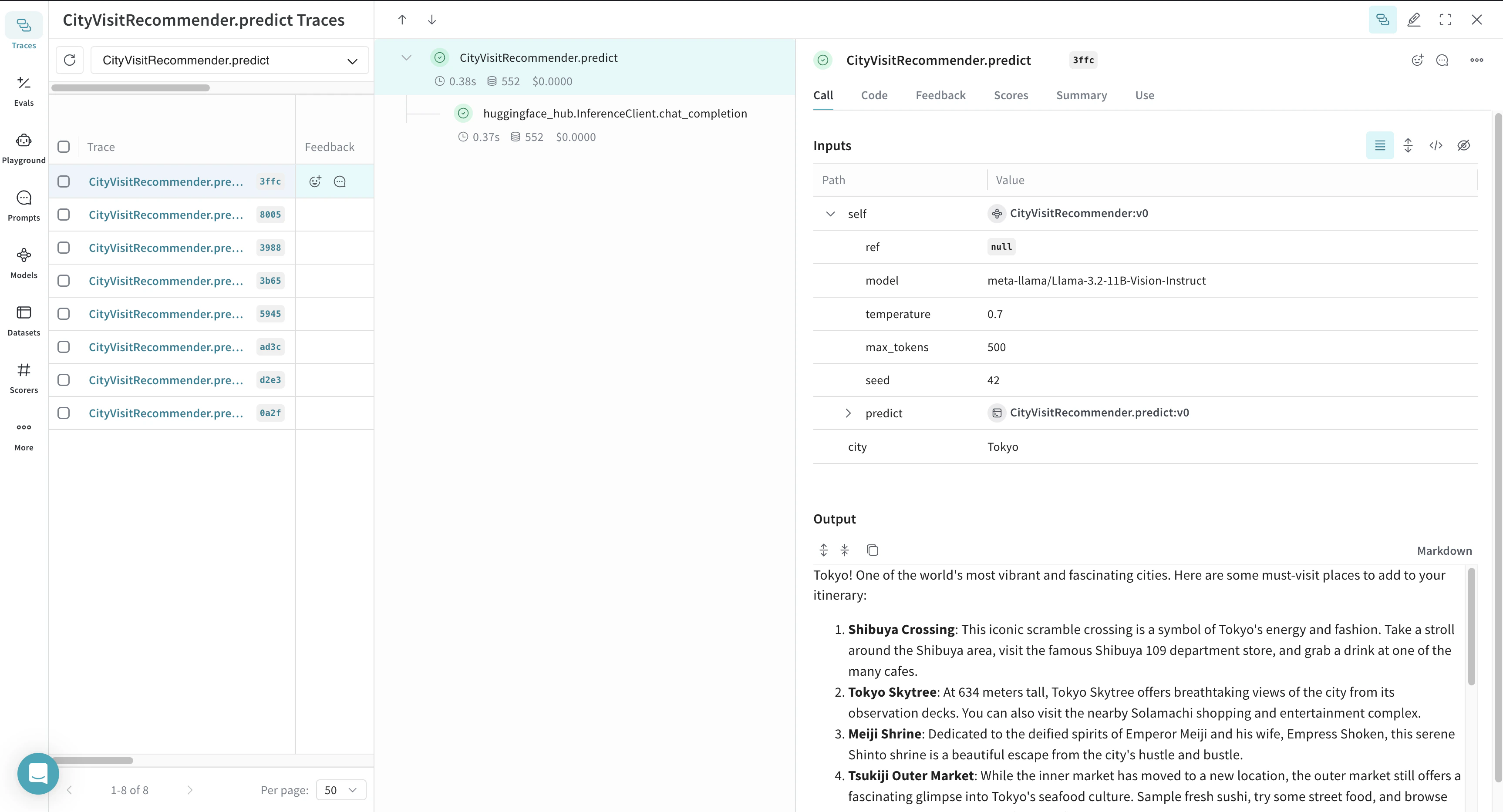
基本的なトレース
InferenceClient のトレースを自動的に取得します。トラッキングを開始するには、weave.init() を呼び出して Weave を初期化し、その後は通常どおりライブラリを使用します。
次の例では、Weave を使用して Hugging Face Hub への推論 Call をログする方法を示します。
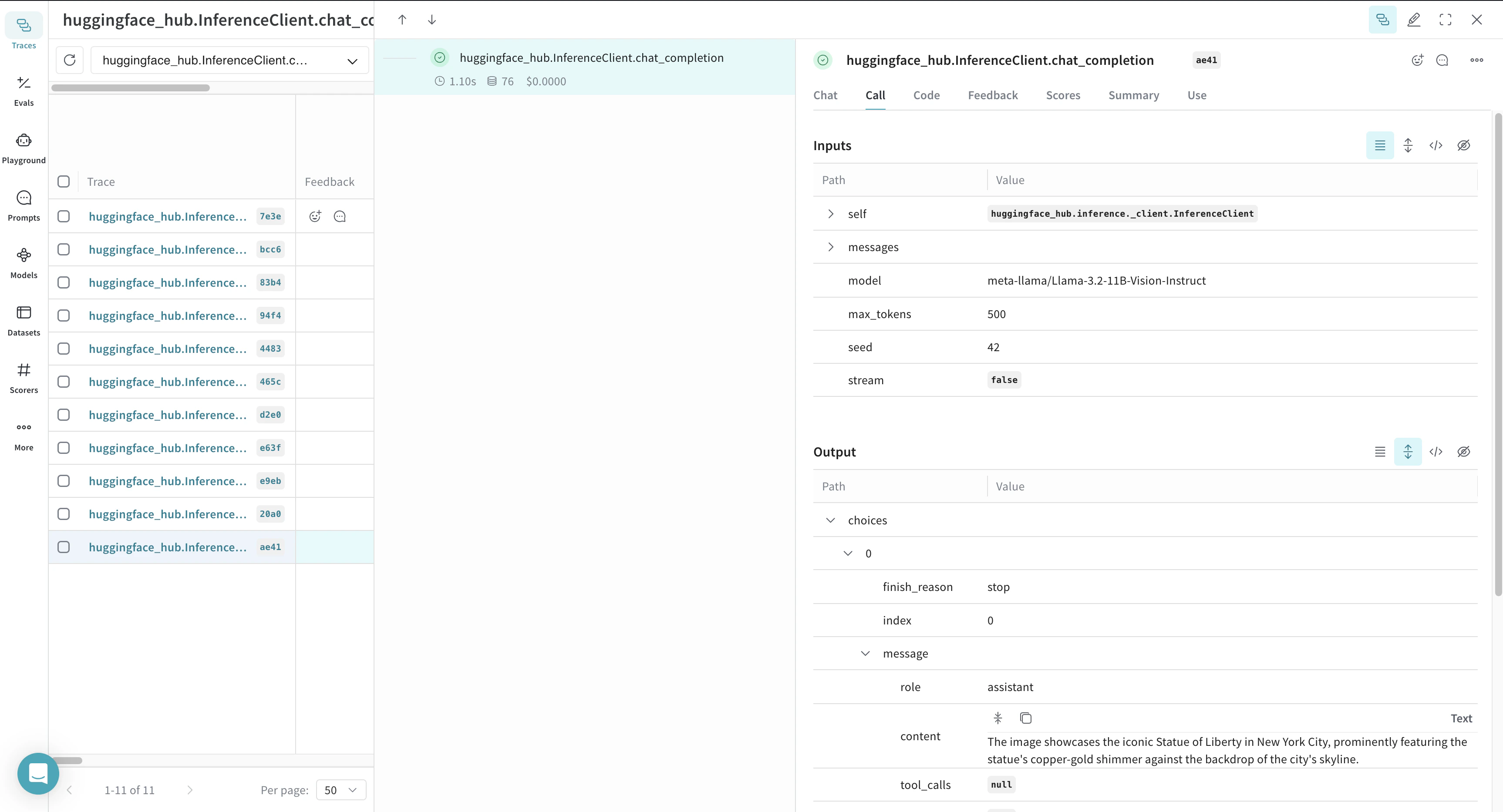
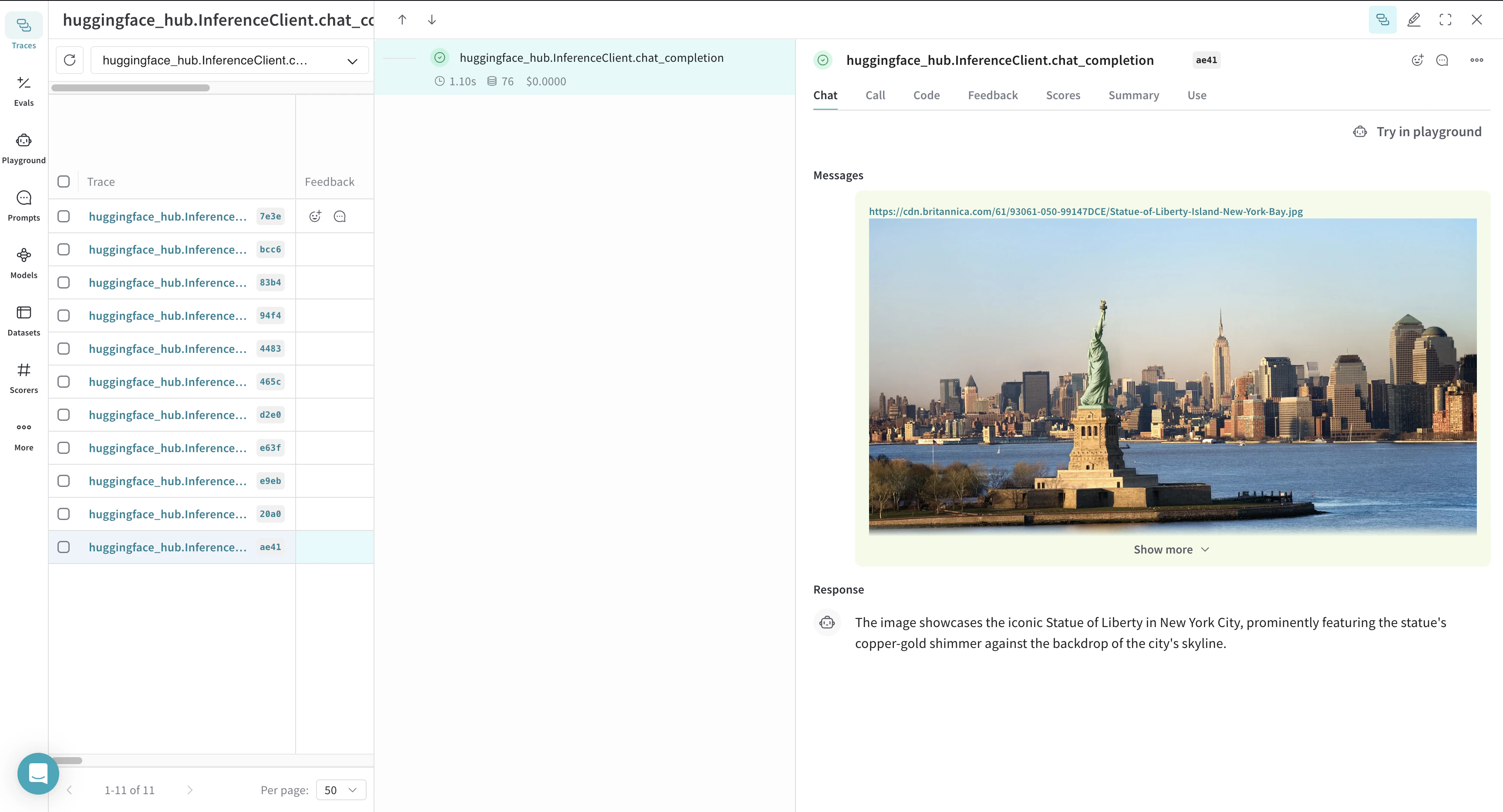
関数をトレースする
@weave.op を使用して関数のcallをトラッキングできます。これにより、入力、出力、実行ロジックが記録され、デバッグやパフォーマンス分析に役立ちます。
複数の op をネストすると、トラッキングされた関数の構造化されたツリーを構築できます。Weave はコードも自動的にバージョン管理するため、Git に変更をコミットする前であっても、実験中の中間状態が保持されます。
トラッキングを開始するには、トラッキングしたい関数に @weave.op デコレータを付けます。
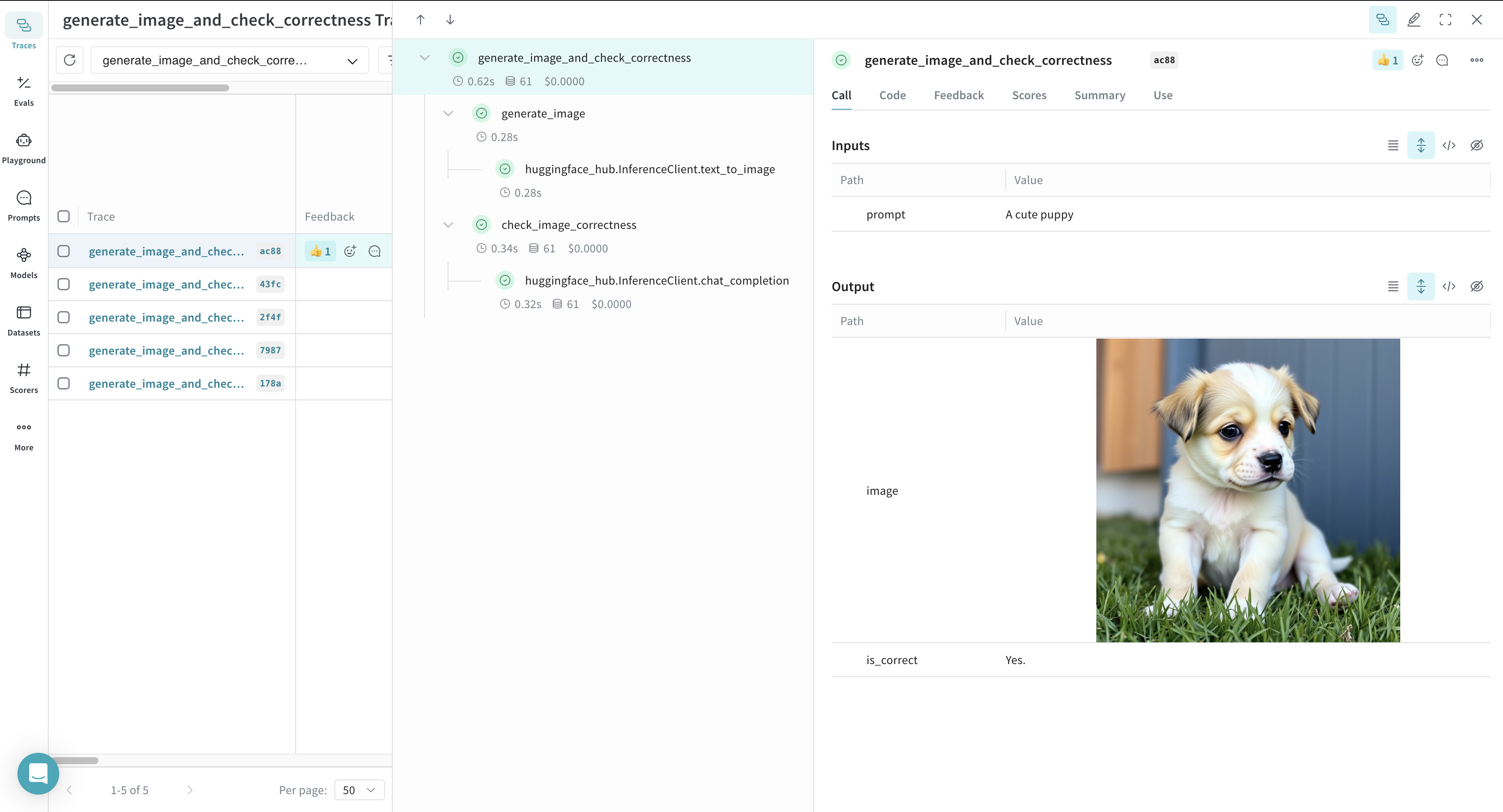
次の例では、Weave は generate_image、check_image_correctness、generate_image_and_check_correctness の 3 つの関数をトラッキングします。これらの関数は画像を生成し、それが指定されたプロンプトに一致するかどうかを検証します。
@weave.op でラップされたすべての関数callがログされるため、Weave UI で実行の詳細を分析できます。
実験には Model を使用する
Model クラスを使うと、system prompt やモデル設定などの実験の詳細を記録して整理でき、異なるイテレーションを比較できます。
コードのバージョン管理や入力と出力の記録に加えて、Model にはアプリケーションの動作を制御する構造化されたパラメーターも保存されます。これにより、どの設定が最良の結果をもたらしたかをトラッキングできます。さらに詳しく分析するために、Weave Model を Weave Serve や Evaluations と統合することもできます。
次の例では、旅行のおすすめ用の CityVisitRecommender モデルを定義します。パラメーターを変更するたびに新しいバージョンが生成されるため、反復的な実験を進められます。