weave.init() を呼び出すと、Weave は ChatNVIDIA ライブラリ経由で実行される LLM Call を自動的にトラッキングしてログします。このガイドでは、ChatNVIDIA を使用する Python 開発者向けに、トレースを取得する方法、独自の関数を Ops としてラップする方法、さらに Weave の Model クラスを使って Experiments を整理する方法を紹介します。これにより、LLM アプリケーションのデバッグ、改善の反復、比較をより効率的に行えます。
トレース
- Python
- TypeScript
Weave は ChatNVIDIA Python ライブラリ のトレースを自動的に取得できます。任意のプロジェクト名を指定して このコードを実行すると、Weave は指定したプロジェクト名の下で ChatNVIDIA の Call を取得し、入力、出力、メタデータを確認できます。
weave.init([PROJECT-NAME]) を呼び出すと、キャプチャを開始できます。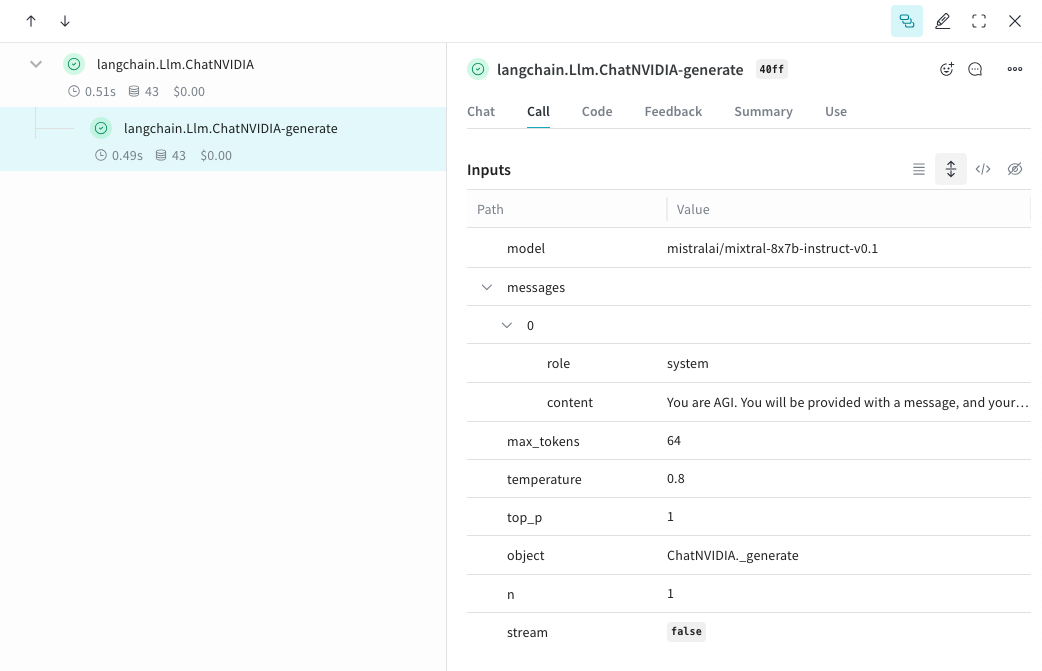
独自の ops をトラッキングする
- Python
- TypeScript
関数を Weave にアクセスし、UI で
@weave.op でラップすると、入力、出力、アプリケーション ロジックの取得が始まり、アプリ内でデータがどのように流れるかをデバッグできるようになります。ops は深くネストでき、トラッキングしたい関数のツリーを構築できます。また、実験を進める中で、まだ Git にコミットしていないアドホックな詳細を取得するためのコードの自動バージョン管理も開始されます。Python ライブラリ を呼び出す @weave.op でデコレートされた関数を作成します。次の例では、2 つの関数が op でラップされています。これにより、RAG アプリの取得ステップのような中間ステップが、アプリケーションの動作にどのように影響するかがわかります。get_pokemon_data をクリックすると、そのステップの入力と出力を確認できます。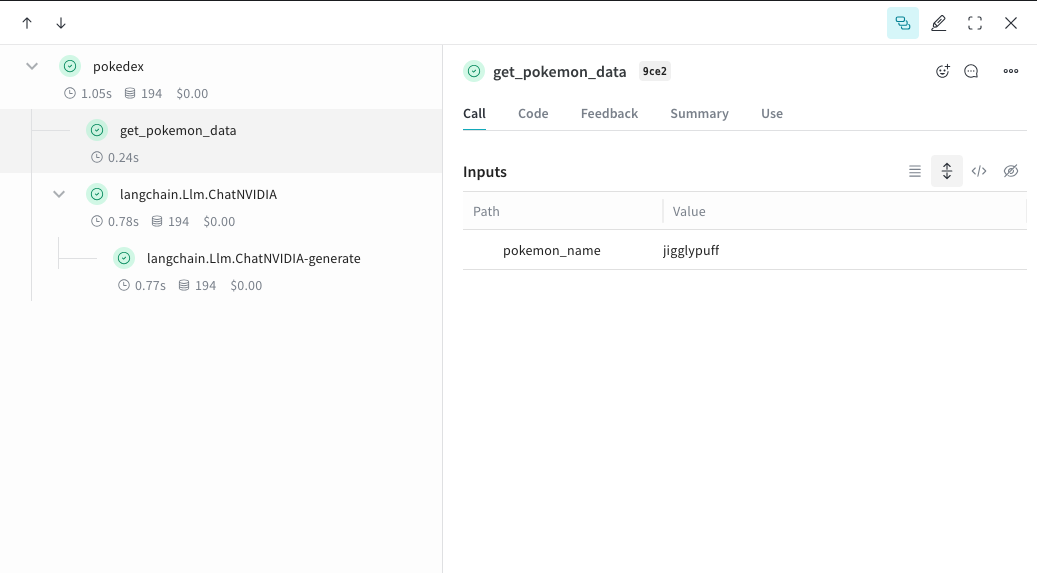
実験をしやすくするための Model を作成する
- Python
- TypeScript
実験には多くの要素が関わるため、整理が難しくなりがちです。
Model クラスを使用すると、システムプロンプトや使用しているモデルなど、アプリの実験に関する詳細を取得して整理できます。これにより、アプリのさまざまなイテレーションを整理して比較しやすくなります。 Model は、コードのバージョン管理や入力と出力の取得に加えて、アプリケーションの動作を制御する構造化されたパラメーターも取得できます。これにより、どのパラメーターが最も効果的だったかを簡単に見つけられます。また、Weave Models は serve や Evaluation でも使用できます。次の例では、model と system_message を試せます。これらのいずれかを変更するたびに、GrammarCorrectorModel の新しい version が作成されます。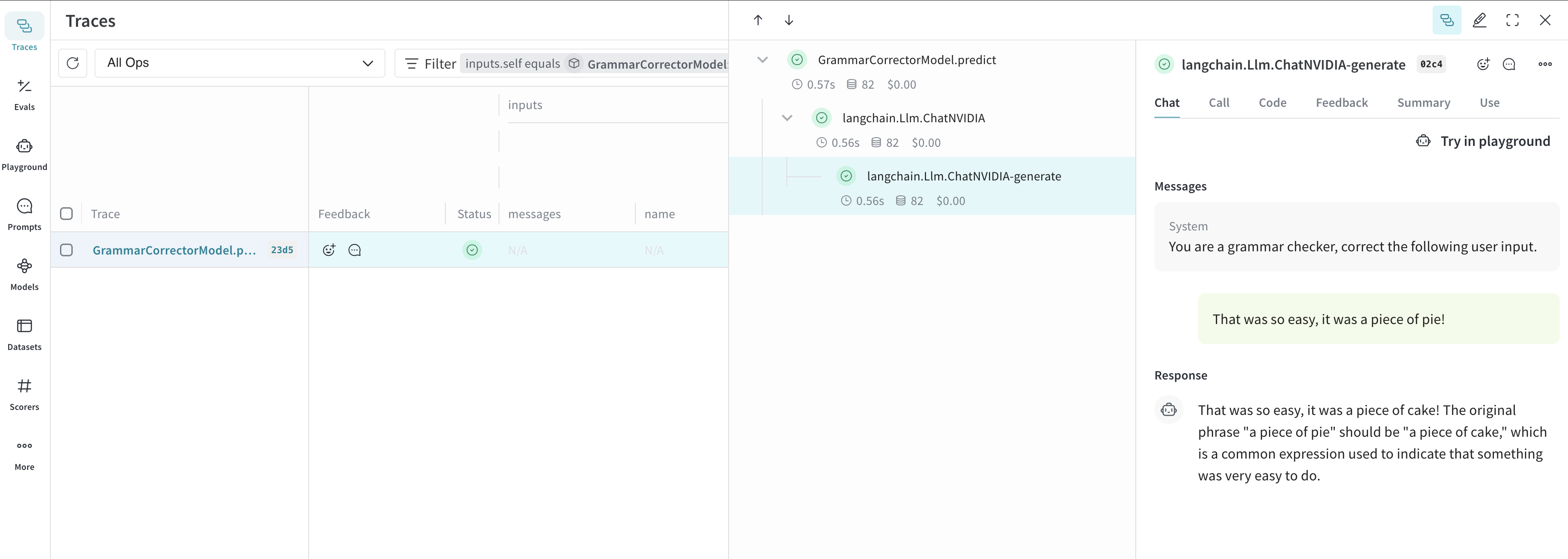
使用情報
invoke、stream、およびそれらの非同期版をサポートします。また、ツールの使用もサポートします。
ChatNVIDIA は多くのタイプのモデルでの使用を想定しているため、関数呼び出しはサポートしていません。