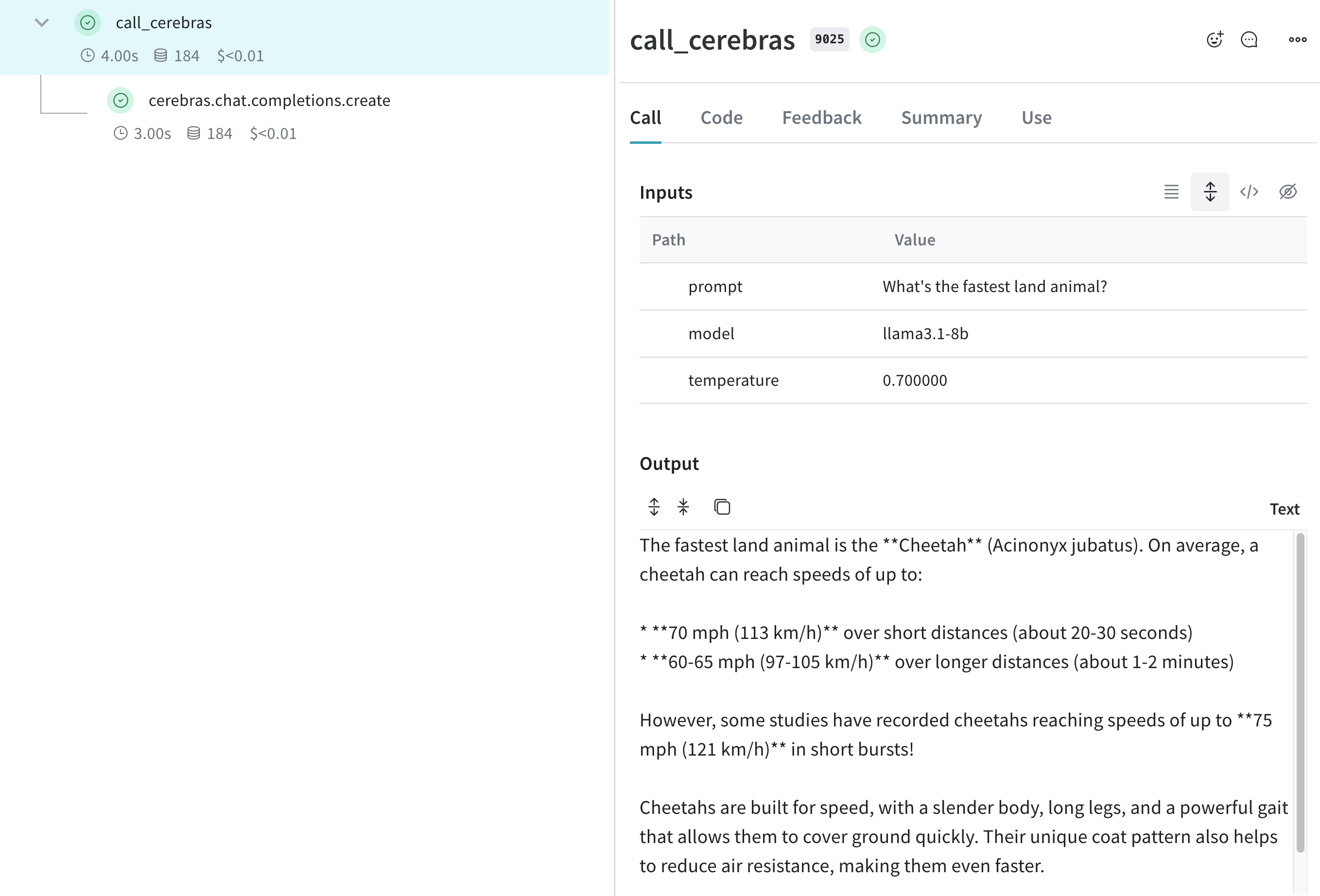
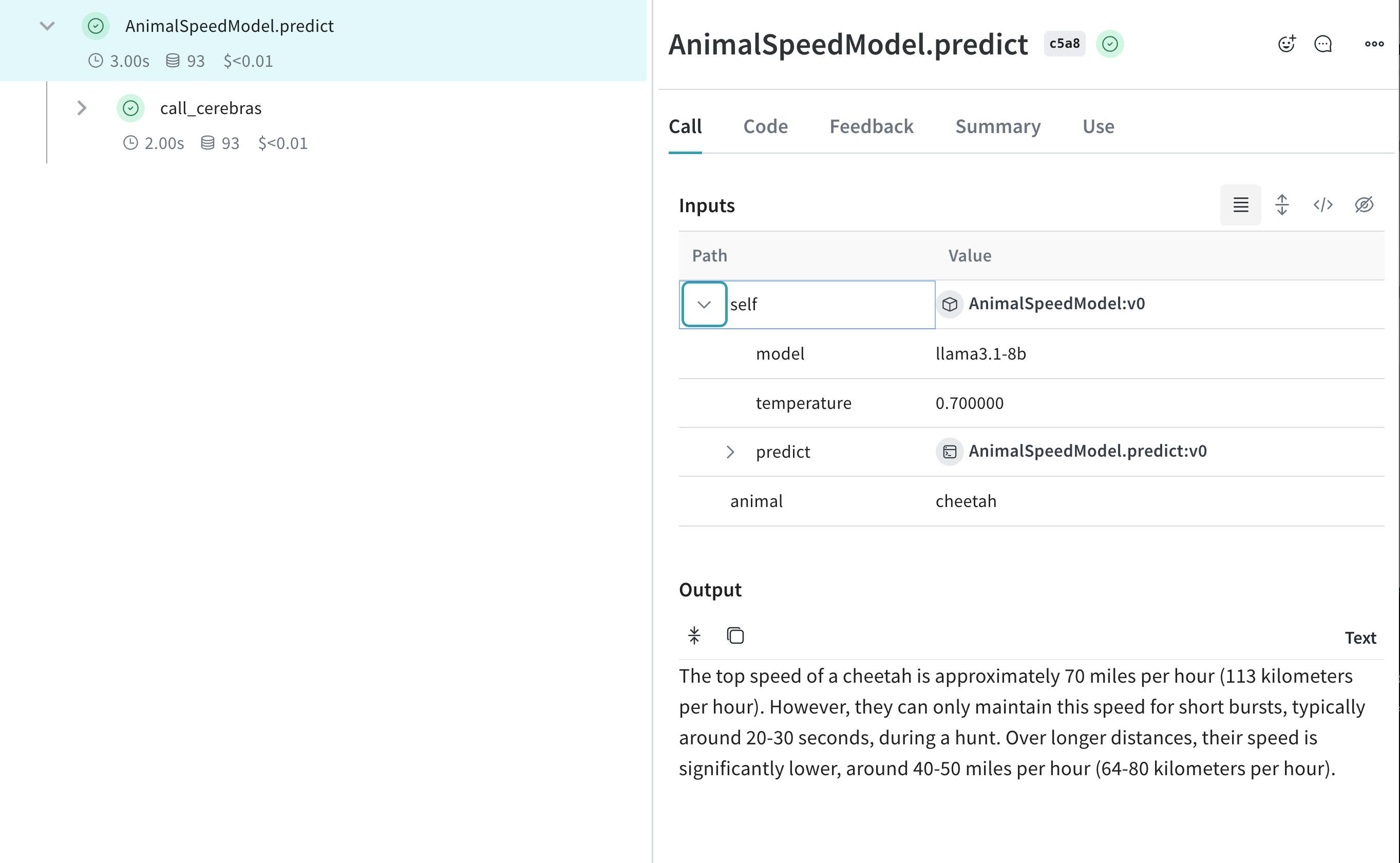
import os
import weave
from cerebras.cloud.sdk import Cerebras
# Weave 프로젝트 초기화
weave.init("cerebras_speedster")
client = Cerebras(api_key=os.environ["CEREBRAS_API_KEY"])
# Weave가 이 함수의 입력, 출력 및 코드를 추적합니다
@weave.op
def animal_speedster(animal: str, model: str) -> str:
"Find out how fast an animal can run"
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": f"How fast can a {animal} run?"}],
)
return response.choices[0].message.content
animal_speedster("cheetah", "llama3.1-8b")
animal_speedster("ostrich", "llama3.1-8b")
animal_speedster("human", "llama3.1-8b")