이 페이지에 표시된 모든 코드 샘플은 Python으로 작성되었습니다.
Google Colab에서 Weave로 Hugging Face Hub 사용해 보기
별도의 설정 없이 Hugging Face Hub와 Weave를 사용해 보고 싶으신가요? 여기 표시된 코드 샘플을 Google Colab의 Jupyter Notebook에서 사용해 볼 수 있습니다.
Overview
huggingface_hub Python 라이브러리는 Hub에 호스팅된 모델에 대해 여러 서비스 전반에서 Inference를 실행할 수 있는 통합 인터페이스를 제공합니다. InferenceClient를 사용해 이러한 모델을 호출할 수 있습니다.
Weave는 InferenceClient의 트레이스를 자동으로 수집합니다. 추적을 시작하려면 weave.init()를 호출한 다음 평소처럼 라이브러리를 사용하세요.
사전 요구 사항
-
Weave에서
huggingface_hub를 사용하려면 먼저 필요한 라이브러리를 설치하거나 최신 버전으로 업그레이드해야 합니다. 다음 명령어는huggingface_hub와weave가 이미 설치된 경우 최신 버전으로 업그레이드하고, 설치되어 있지 않은 경우 설치하며, 설치 출력도 최소화합니다. -
Hugging Face Hub의 모델에 대해 Inference를 사용하려면 User Access Token을 설정하세요. 토큰은 Hugging Face Hub Settings page에서 설정하거나, 프로그래밍 방식으로 설정할 수 있습니다. 다음 코드 예제는 사용자가
HUGGINGFACE_TOKEN을 입력하라는 프롬프트를 표시한 뒤, 해당 토큰을 환경 변수로 설정합니다.
기본 트레이싱
InferenceClient의 트레이스를 자동으로 수집합니다. 추적을 시작하려면 weave.init()를 호출해 Weave를 초기화한 다음 평소처럼 라이브러리를 사용하세요.
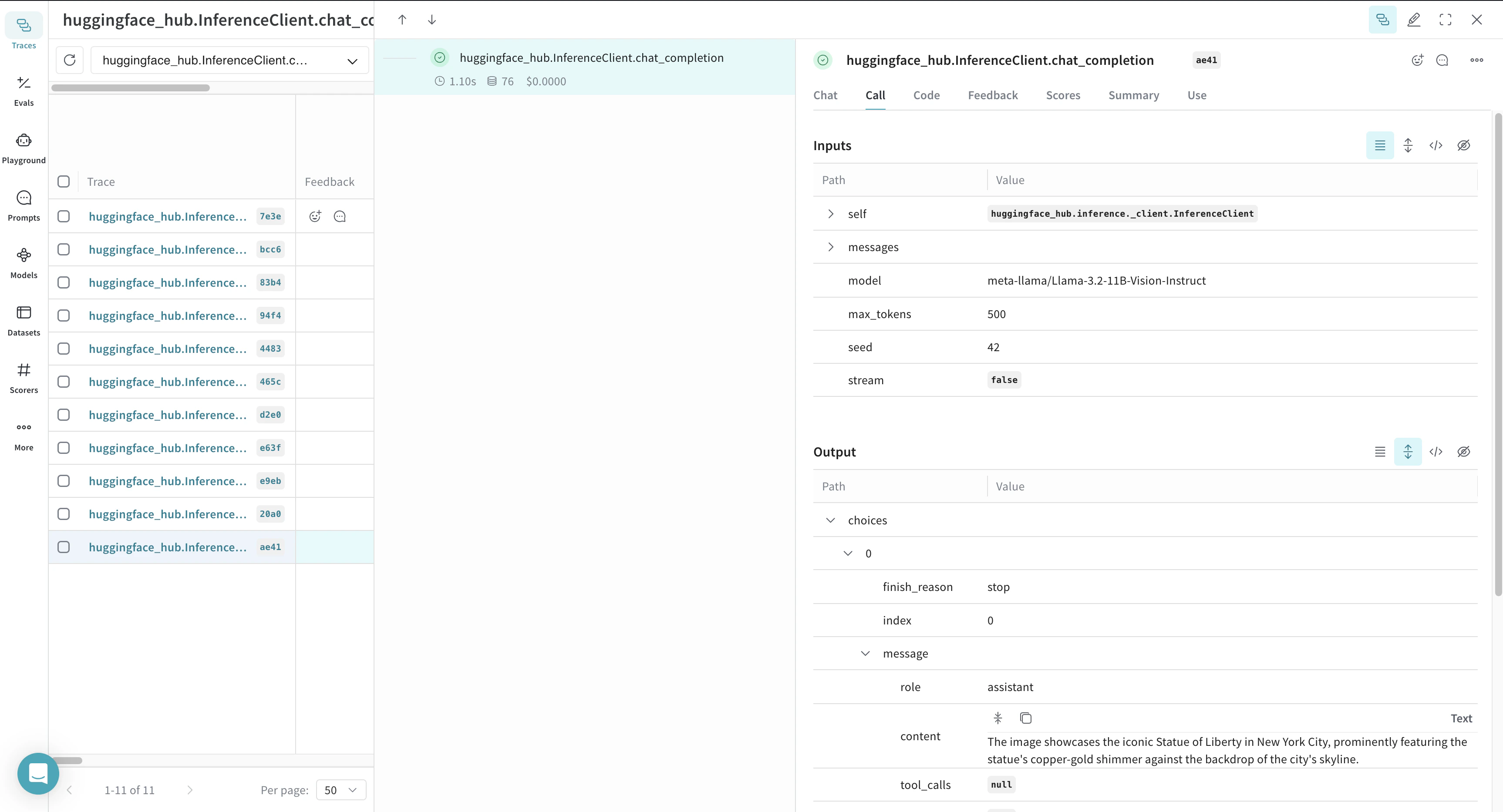
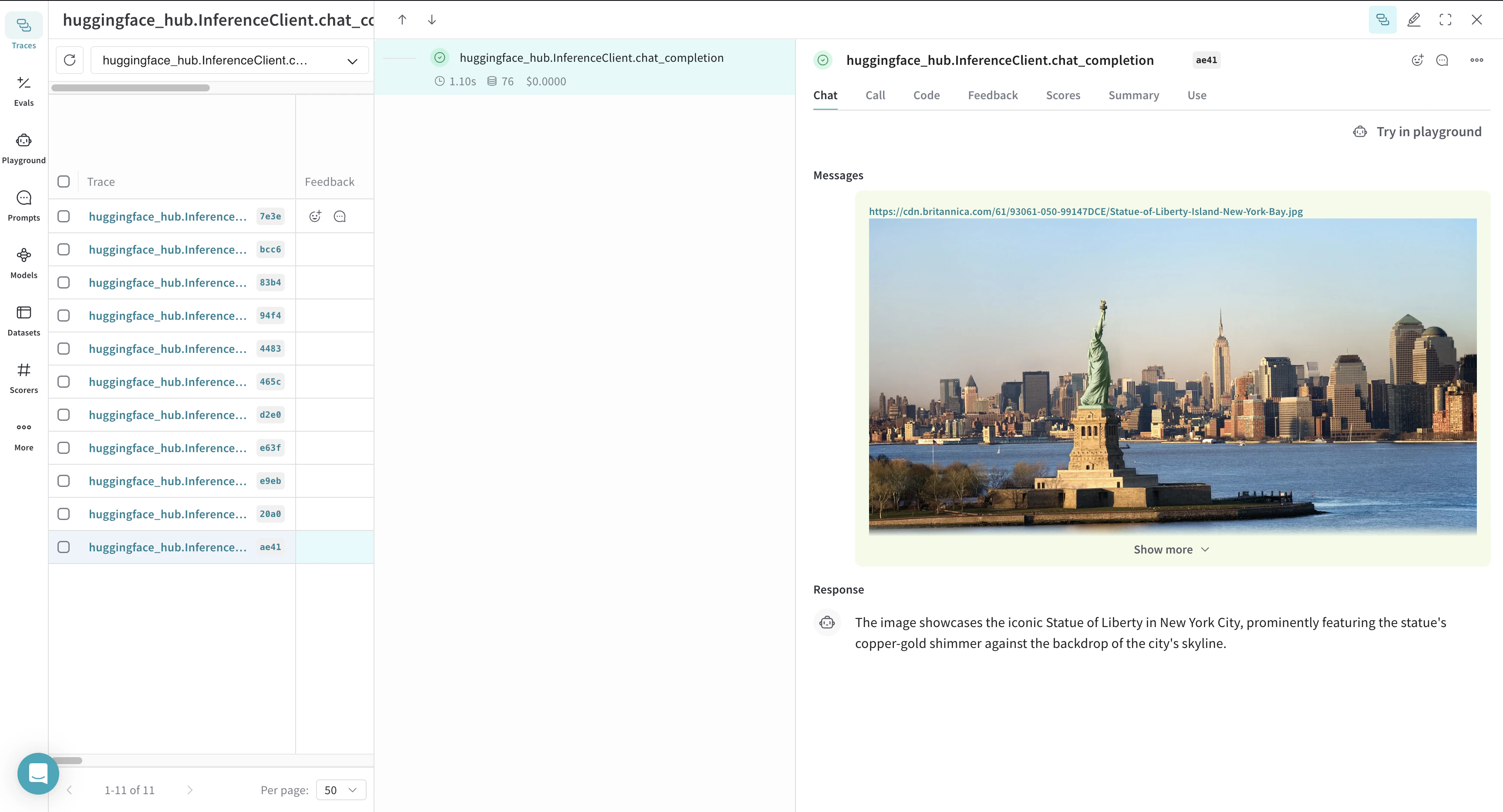
다음 예시는 Weave를 사용해 Hugging Face Hub에 Inference call을 로깅하는 방법을 보여줍니다:
함수를 트레이스하기
@weave.op를 사용해 함수 호출을 추적할 수 있습니다. 이렇게 하면 입력, 출력, 실행 로직이 캡처되어 디버깅과 성능 분석에 도움이 됩니다.
여러 op를 중첩하면 추적된 함수의 구조화된 트리를 만들 수 있습니다. Weave는 코드도 자동으로 버전 관리하므로 Git에 변경 사항을 커밋하기 전, 실험하는 동안의 중간 상태까지 보존합니다.
추적을 시작하려면 추적하려는 함수에 @weave.op를 데코레이터로 추가하세요.
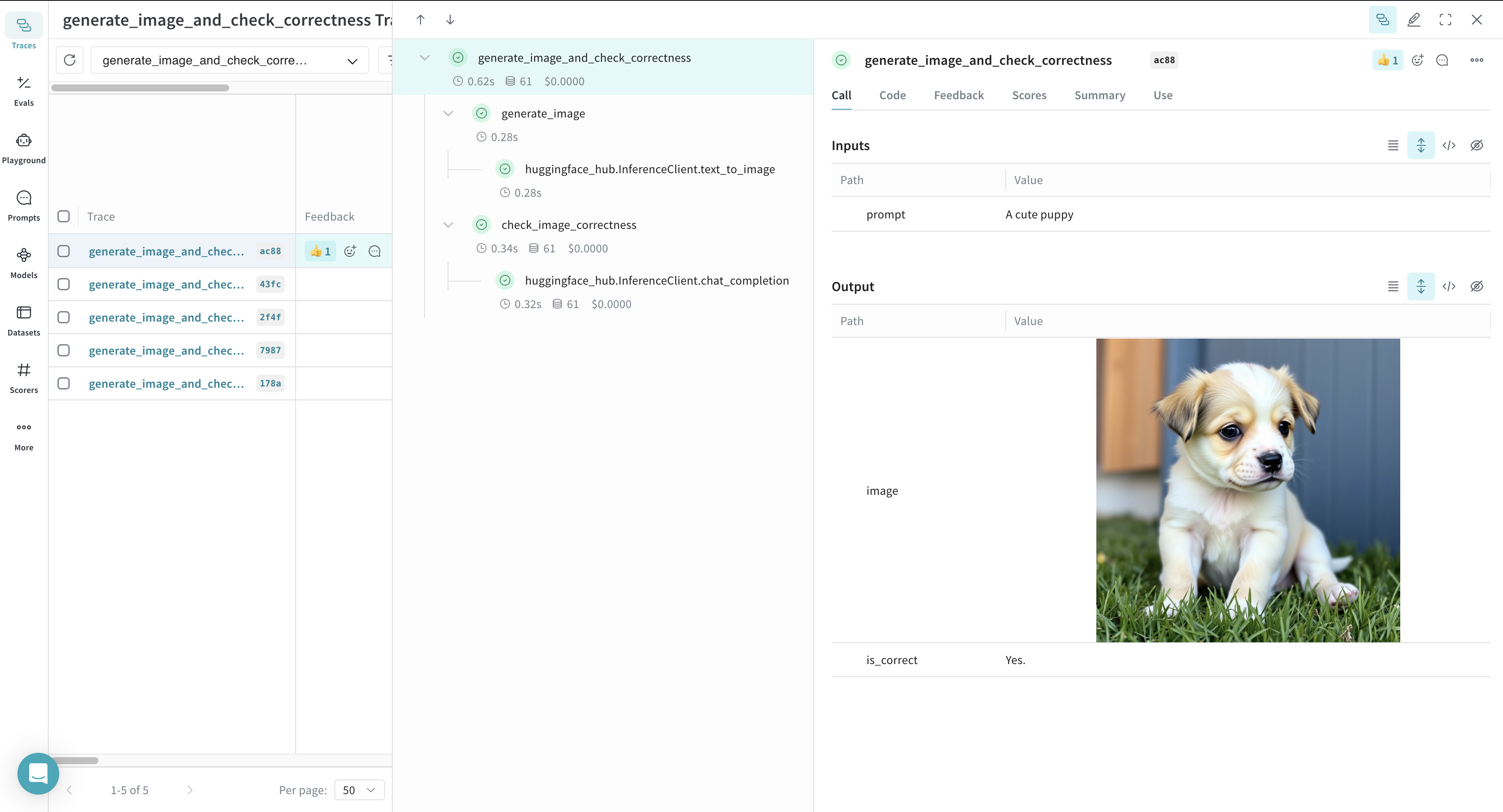
다음 예시에서 Weave는 generate_image, check_image_correctness, generate_image_and_check_correctness의 세 함수를 추적합니다. 이 함수들은 이미지를 생성하고, 생성된 이미지가 주어진 프롬프트와 일치하는지 검증합니다.
@weave.op로 감싼 모든 함수 호출을 로깅하므로 Weave UI에서 실행 세부 사항을 분석할 수 있습니다.
실험에 Model 활용하기
Model 클래스는 시스템 프롬프트와 모델 설정 같은 실험 세부 정보를 기록하고 정리해, 서로 다른 반복 버전을 비교할 수 있게 해줍니다.
코드를 버전 관리하고 입력과 출력을 기록하는 것 외에도, Model은 애플리케이션 동작을 제어하는 구조화된 매개변수를 저장합니다. 따라서 어떤 설정이 가장 좋은 결과를 냈는지 추적할 수 있습니다. 또한 Weave Model을 Weave 서빙 및 Evaluations와 통합해 더 많은 인사이트를 얻을 수 있습니다.
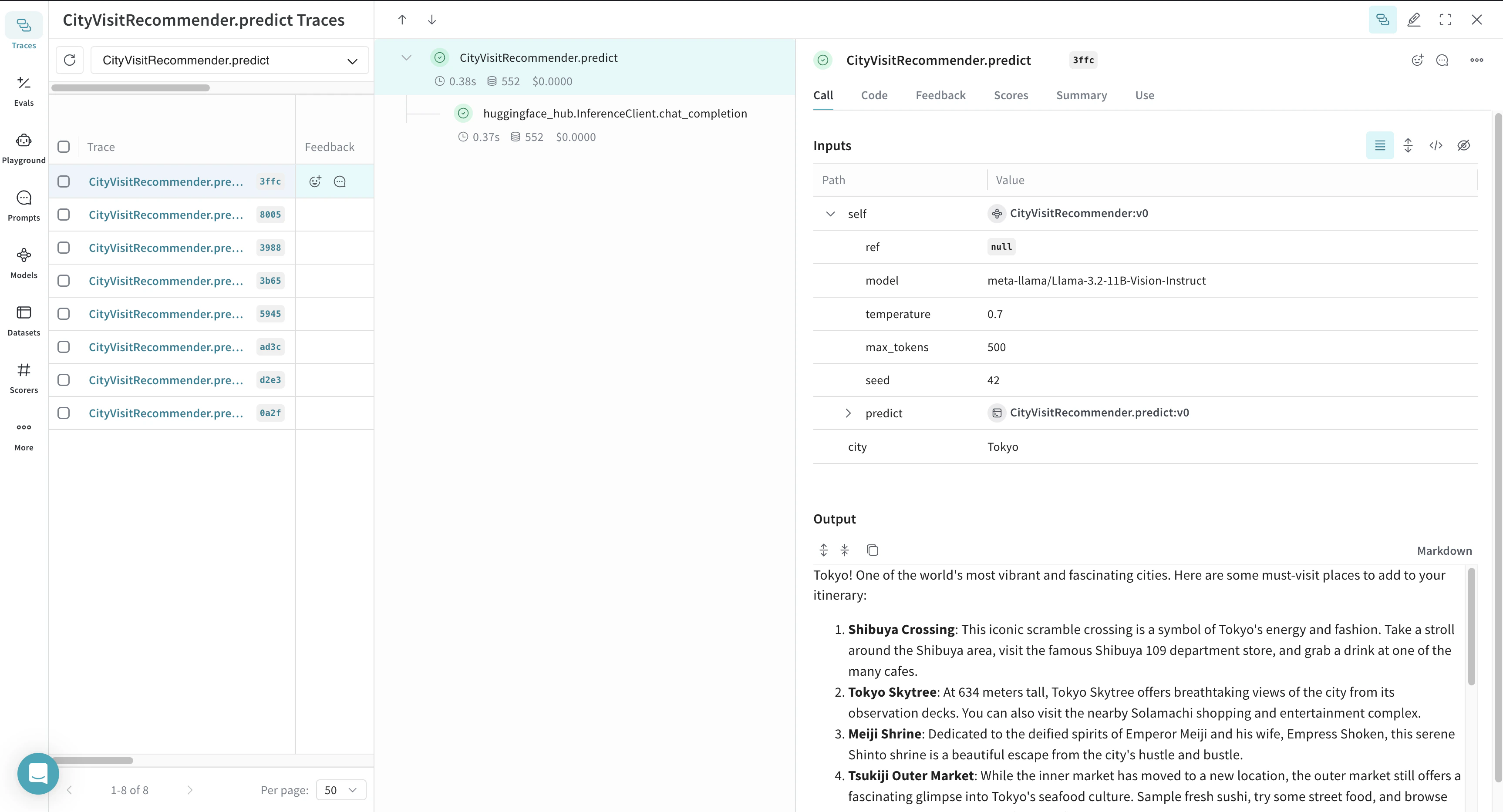
다음 예시에서는 여행 추천용 CityVisitRecommender 모델을 정의합니다. 매개변수를 수정할 때마다 새 버전이 생성되어 반복적인 실험을 지원합니다.