Example blog & Colab
Read here to see how to train a model with PaddleOCR on the ICDAR2015 dataset. This also comes with a Google Colab and the corresponding live W&B dashboard is available here. There is also a Chinese version of this blog here: W&B对您的OCR模型进行训练和调试Sign up and create an API key
An API key authenticates your machine to W&B. You can generate an API key from your user profile.For a more streamlined approach, go to User Settings and create an API key. Copy the API key immediately and save it in a secure location such as a password manager.
- Click your user profile icon in the upper right corner.
- Select User Settings, then scroll to the API Keys section.
Install the wandb library and log in
To install the wandb library locally and log in:
- Command Line
- Python
- Python notebook
-
Set the
WANDB_API_KEYenvironment variable to your API key. -
Install the
wandblibrary and log in.
Add wandb to your config.yml file
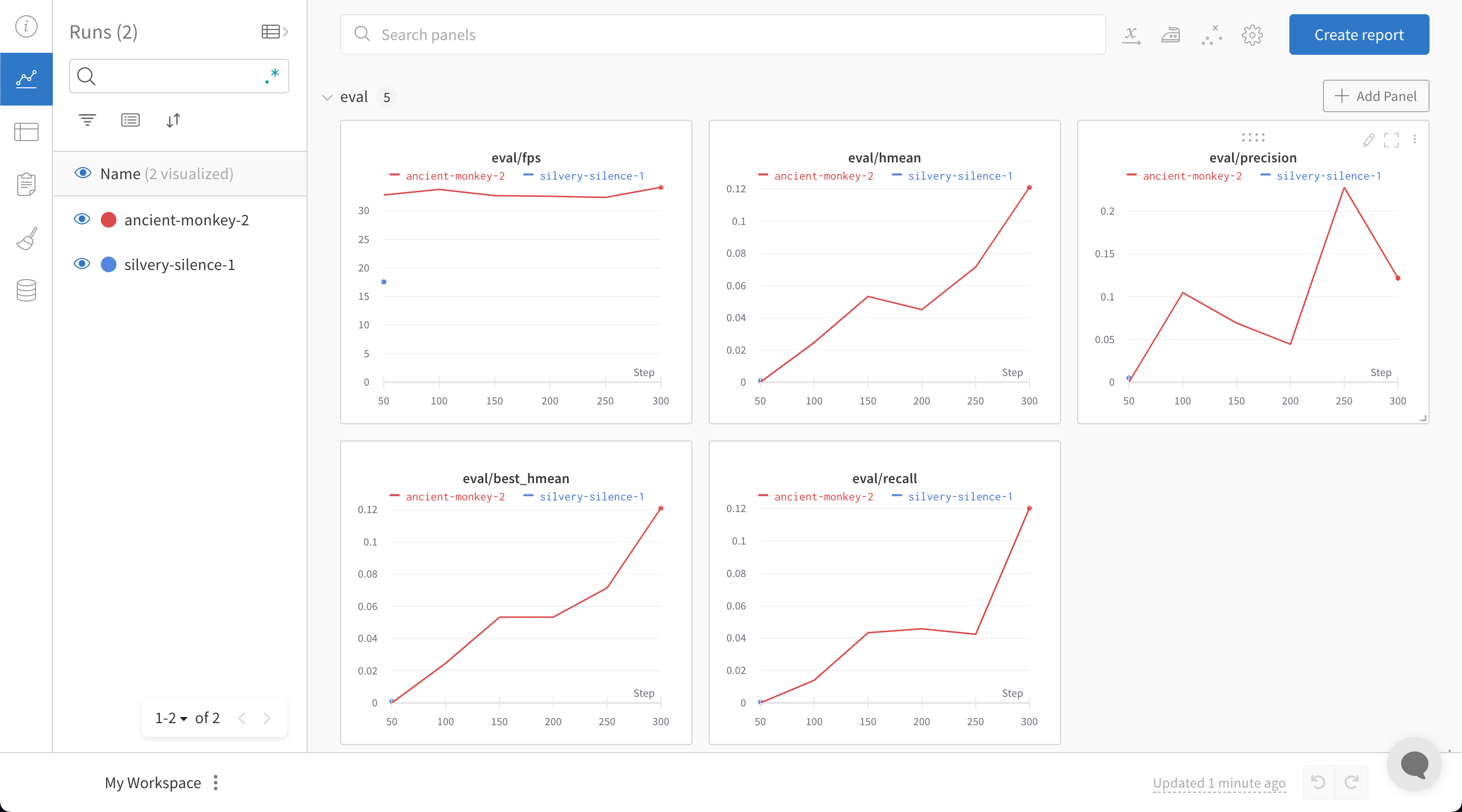
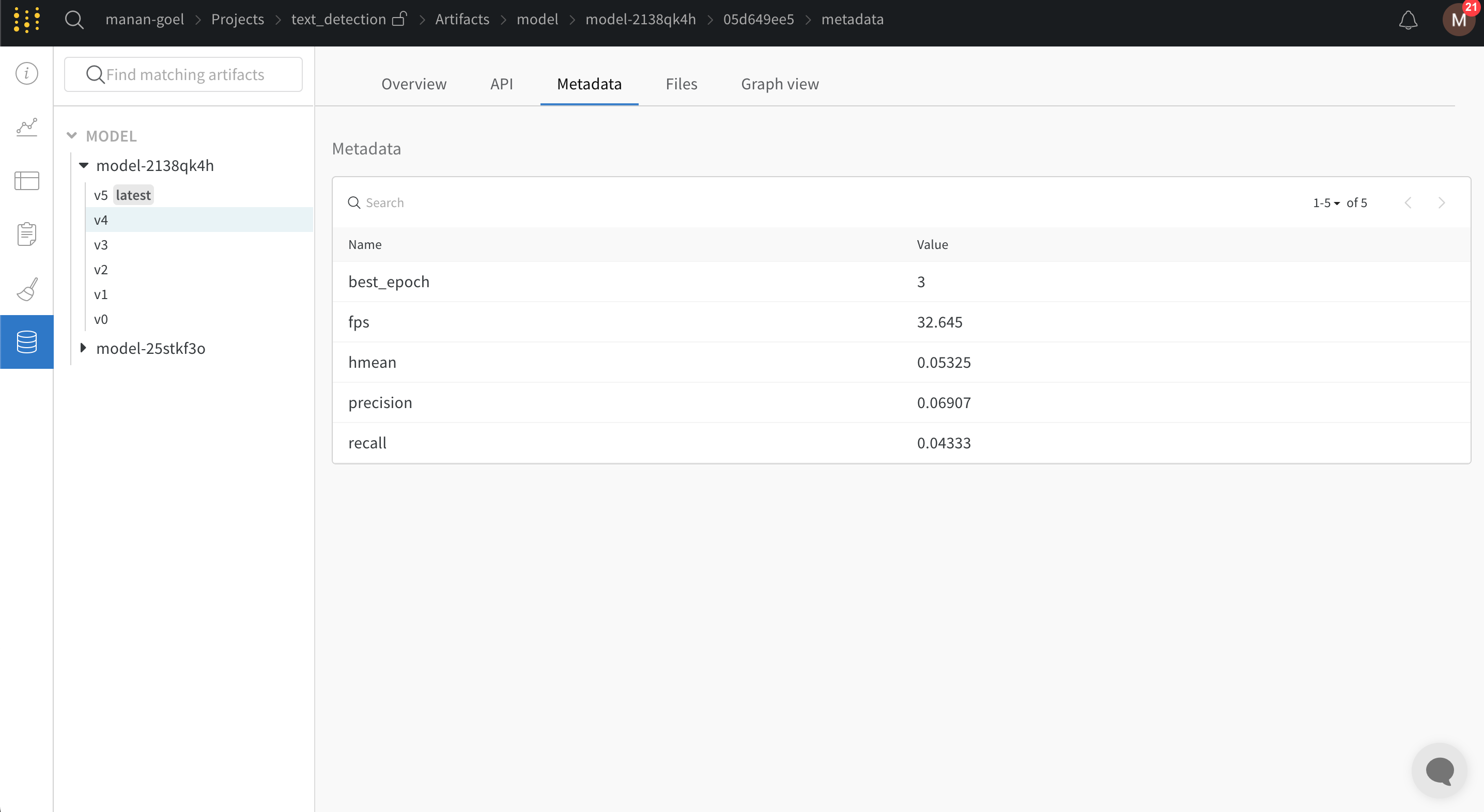
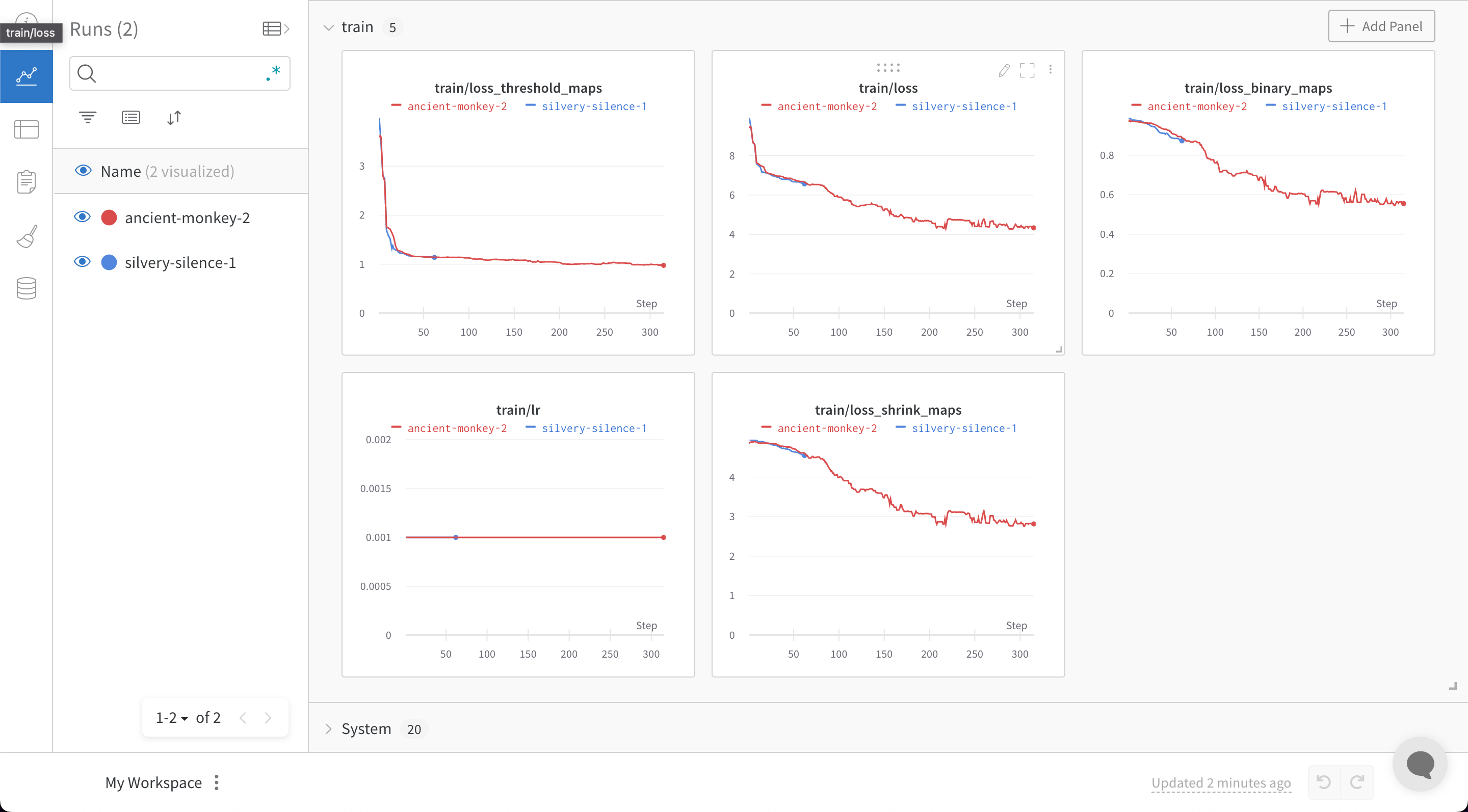
PaddleOCR requires configuration variables to be provided using a yaml file. Adding the following snippet at the end of the configuration yaml file will automatically log all training and validation metrics to a W&B dashboard along with model checkpoints:
wandb.init() can also be added under the wandb header in the yaml file:
Pass the config.yml file to train.py
The yaml file is then provided as an argument to the training script available in the PaddleOCR repository.
train.py file with W&B turned on, a link will be generated to bring you to your W&B dashboard: