Model Registry Terms and Concepts
4 minute read
The following terms describe key components of the W&B Model Registry: model version, model artifact, and registered model.
Model version
A model version represents a single model checkpoint. Model versions are a snapshot at a point in time of a model and its files within an experiment.
A model version is an immutable directory of data and metadata that describes a trained model. W&B suggests that you add files to your model version that let you store (and restore) your model architecture and learned parameters at a later date.
A model version belongs to one, and only one, model artifact. A model version can belong to zero or more, registered models. Model versions are stored in a model artifact in the order they are logged to the model artifact. W&B automatically creates a new model version if it detects that a model you log (to the same model artifact) has different contents than a previous model version.
Store files within model versions that are produced from the serialization process provided by your modeling library (for example, PyTorch and Keras).
Model alias
Model aliases are mutable strings that allow you to uniquely identify or reference a model version in your registered model with a semantically related identifier. You can only assign an alias to one version of a registered model. This is because an alias should refer to a unique version when used programmatically. It also allows aliases to be used to capture a model’s state (champion, candidate, production).
It is common practice to use aliases such as "best", "latest", "production", or "staging" to mark model versions with special purposes.
For example, suppose you create a model and assign it a "best" alias. You can refer to that specific model with run.use_model
import wandb
run = wandb.init()
name = f"{entity/project/model_artifact_name}:{alias}"
run.use_model(name=name)
Model tags
Model tags are keywords or labels that belong to one or more registered models.
Use model tags to organize registered models into categories and to search over those categories in the Model Registry’s search bar. Model tags appear at the top of the Registered Model Card. You might choose to use them to group your registered models by ML task, owning team, or priority. The same model tag can be added to multiple registered models to allow for grouping.
Model artifact
A model artifact is a collection of logged model versions. Model versions are stored in a model artifact in the order they are logged to the model artifact.
A model artifact can contain one or more model versions. A model artifact can be empty if no model versions are logged to it.
For example, suppose you create a model artifact. During model training, you periodically save your model during checkpoints. Each checkpoint corresponds to its own model version. All of the model versions created during your model training and checkpoint saving are stored in the same model artifact you created at the beginning of your training script.
The proceeding image shows a model artifact that contains three model versions: v0, v1, and v2.
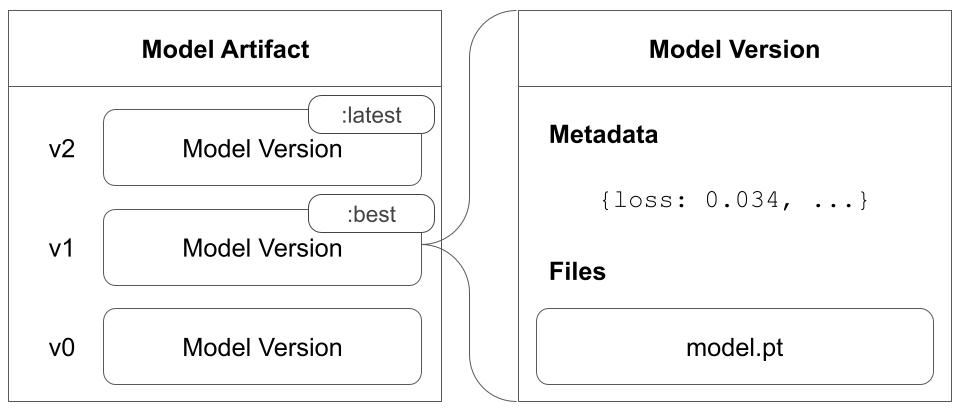
View an example model artifact here.
Registered model
A registered model is a collection of pointers (links) to model versions. You can think of a registered model as a folder of “bookmarks” of candidate models for the same ML task. Each “bookmark” of a registered model is a pointer to a model version that belongs to a model artifact. You can use model tags to group your registered models.
Registered models often represent candidate models for a single modeling use case or task. For example, you might create registered model for different image classification task based on the model you use: ImageClassifier-ResNet50, ImageClassifier-VGG16, DogBreedClassifier-MobileNetV2 and so on. Model versions are assigned version numbers in the order in which they were linked to the registered model.
View an example Registered Model here.
Feedback
Was this page helpful?
Glad to hear it! If you have further feedback, please let us know.
Sorry to hear that. Please tell us how we can improve.