AgentChat), 멀티 에이전트 핵심 기능(Core), 외부 서비스 인테그레이션(Extensions)을 제공해 복잡한 멀티 에이전트 시스템을 더 쉽게 만들 수 있도록 지원합니다. 또한 AutoGen은 코드 없이 에이전트 프로토타입을 만들 수 있는 Studio도 제공합니다. 자세한 내용은 AutoGen 공식 문서를 참조하세요.
이 가이드는 AutoGen에 대한 기본적인 이해가 있다고 가정합니다.
autogen_agentchat, autogen_core, autogen_ext 내 상호작용을 자동으로 추적합니다. 이 가이드에서는 AutoGen과 함께 Weave를 구성하는 방법을 안내하고, 모델 클라이언트, 도구를 사용하는 에이전트, 그룹 채팅, 메모리, RAG 워크플로, 에이전트 런타임, 순차 워크플로, 코드 실행기를 다루는 예시를 보여줍니다. 이 가이드를 마치면 Weave에서 AutoGen 애플리케이션의 상세한 트레이스를 캡처해 에이전트 동작을 디버그하고, LLM 사용을 모니터링하며, 복잡한 워크플로 전반에서 에이전트가 어떻게 상호작용하는지 이해할 수 있습니다.
사전 요구 사항
pip install autogen_agentchat "autogen_ext[openai,anthropic]" weave
import os
os.environ["OPENAI_API_KEY"] = "[YOUR-OPENAI-API-KEY]"
os.environ["ANTHROPIC_API_KEY"] = "[YOUR-ANTHROPIC-API-KEY]"
기본 설정
import weave
weave.init("autogen-demo")
autogen-demo 프로젝트로 트레이스를 전송하도록 설정되고, 이후 스크립트에서 발생하는 모든 AutoGen 활동이 Weave에 의해 자동으로 캡처됩니다.
모델 클라이언트용 트레이스
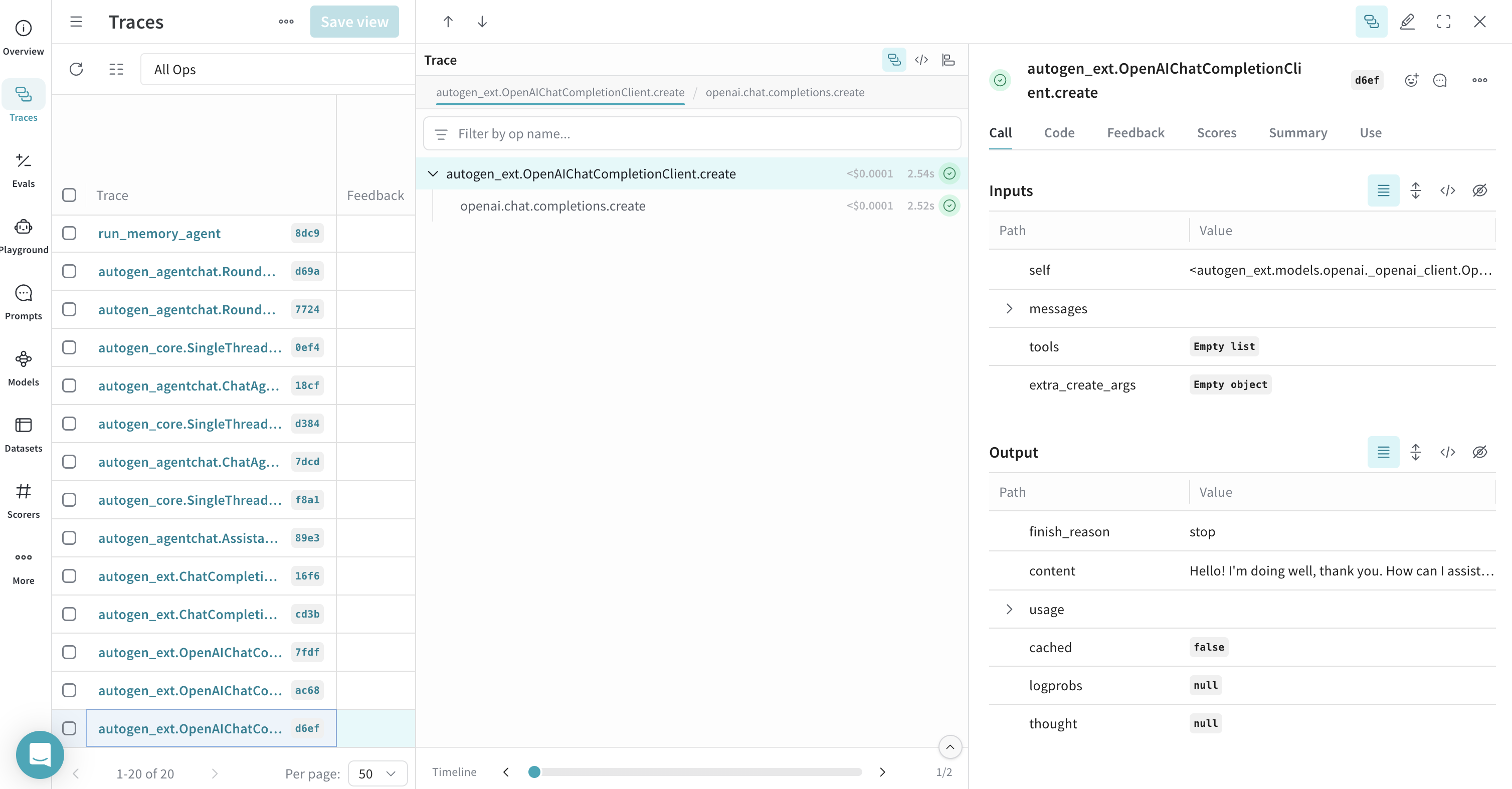
클라이언트 create Call 트레이스
OpenAIChatCompletionClient의 Call을 트레이스하는 방법을 보여줍니다.
import asyncio
from autogen_core.models import UserMessage
from autogen_ext.models.openai import OpenAIChatCompletionClient
# from autogen_ext.models.anthropic import AnthropicChatCompletionClient
async def simple_client_call(model_name = "gpt-4o"):
model_client = OpenAIChatCompletionClient(
model=model_name,
)
# 또는 Anthropic이나 다른 모델 클라이언트를 사용할 수 있습니다
# model_client = AnthropicChatCompletionClient(
# model="claude-3-haiku-20240307"
# )
response = await model_client.create(
[UserMessage(content="Hello, how are you?", source="user")]
)
print(response)
asyncio.run(simple_client_call())
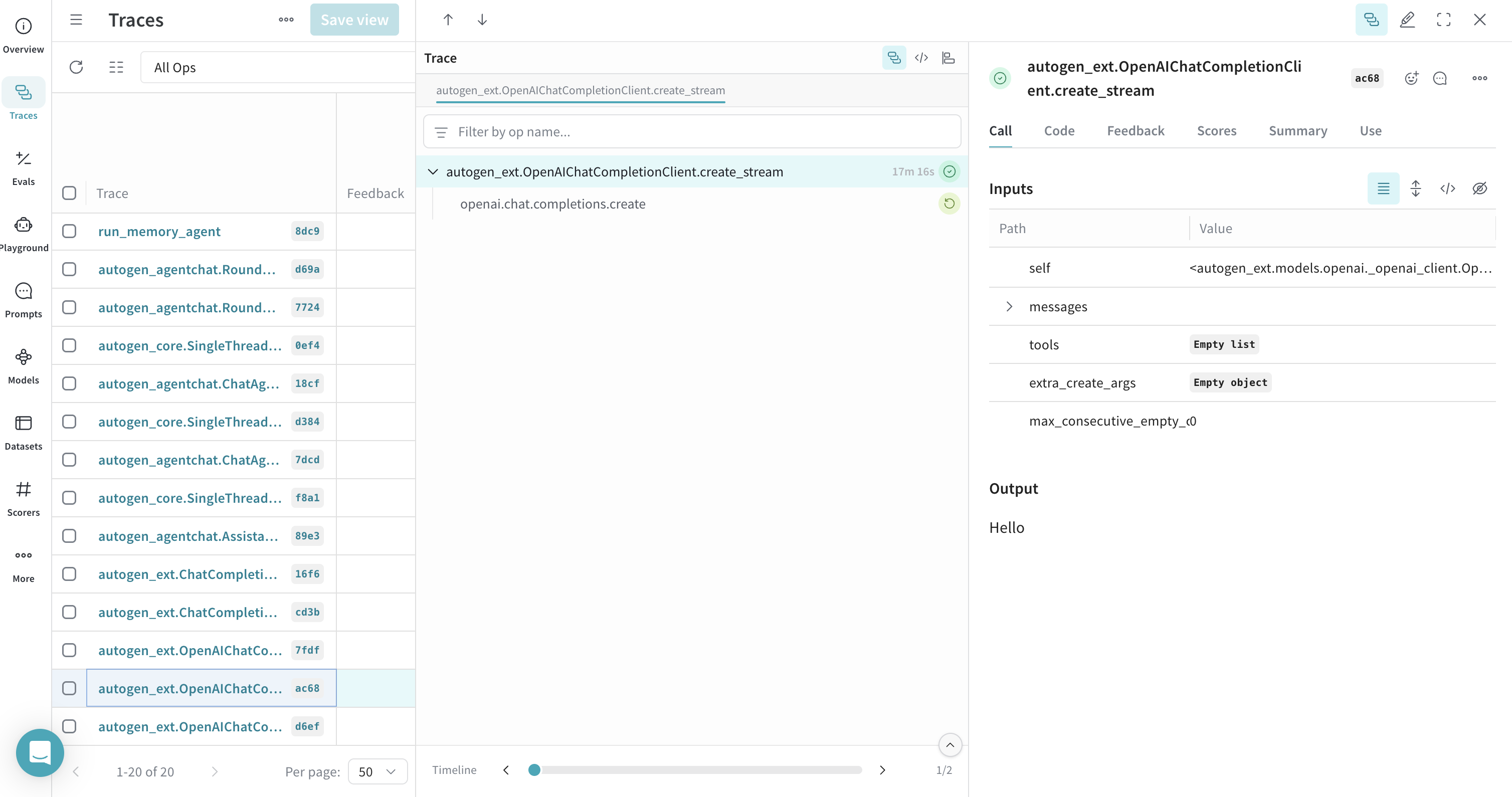
스트리밍을 사용하는 클라이언트 create call의 트레이스
async def simple_client_call_stream(model_name = "gpt-4o"):
openai_model_client = OpenAIChatCompletionClient(model=model_name)
async for item in openai_model_client.create_stream(
[UserMessage(content="Hello, how are you?", source="user")]
):
print(item, flush=True, end="")
asyncio.run(simple_client_call_stream())
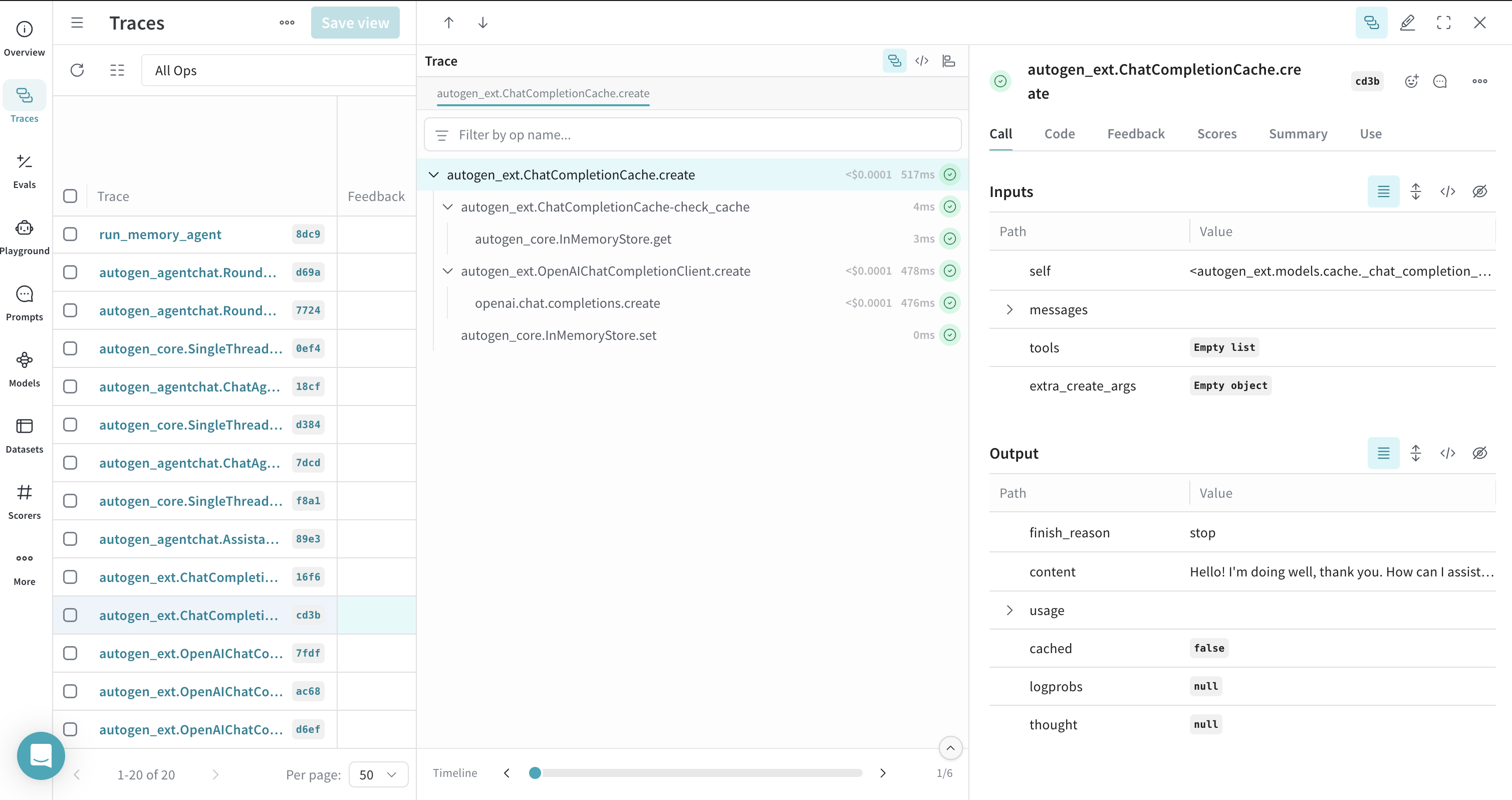
캐시된 클라이언트 call의 트레이스
ChatCompletionCache를 사용할 수 있으며, Weave는 이러한 상호작용을 트레이스해 응답이 캐시에서 온 것인지 새 call에서 온 것인지 보여줍니다.
from autogen_ext.models.cache import ChatCompletionCache
async def run_cache_client(model_name = "gpt-4o"):
openai_model_client = OpenAIChatCompletionClient(model=model_name)
cache_client = ChatCompletionCache(openai_model_client,)
response = await cache_client.create(
[UserMessage(content="Hello, how are you?", source="user")]
)
print(response) # OpenAI의 응답을 출력해야 합니다
response = await cache_client.create(
[UserMessage(content="Hello, how are you?", source="user")]
)
print(response) # 캐시된 응답을 출력해야 합니다
asyncio.run(run_cache_client())
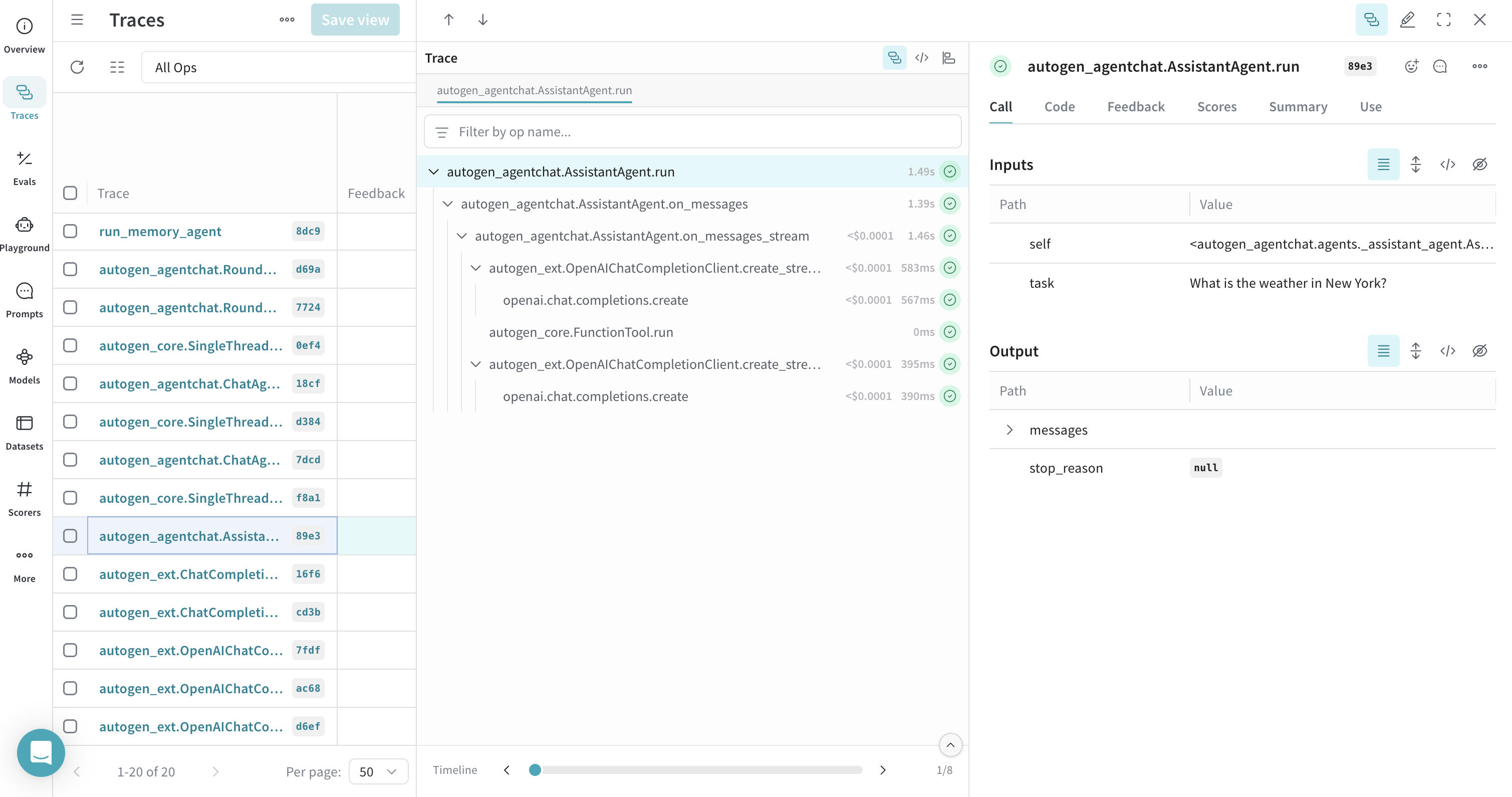
도구 call을 사용하는 에이전트의 트레이스
AssistantAgent에 연결합니다.
from autogen_agentchat.agents import AssistantAgent
async def get_weather(city: str) -> str:
return f"The weather in {city} is 73 degrees and Sunny."
async def run_agent_with_tools(model_name = "gpt-4o"):
model_client = OpenAIChatCompletionClient(model=model_name)
agent = AssistantAgent(
name="weather_agent",
model_client=model_client,
tools=[get_weather],
system_message="You are a helpful assistant.",
reflect_on_tool_use=True,
)
# 콘솔에 스트리밍 출력하려면:
# await Console(agent.run_stream(task="What is the weather in New York?"))
res = await agent.run(task="What is the weather in New York?")
print(res)
await model_client.close()
asyncio.run(run_agent_with_tools())
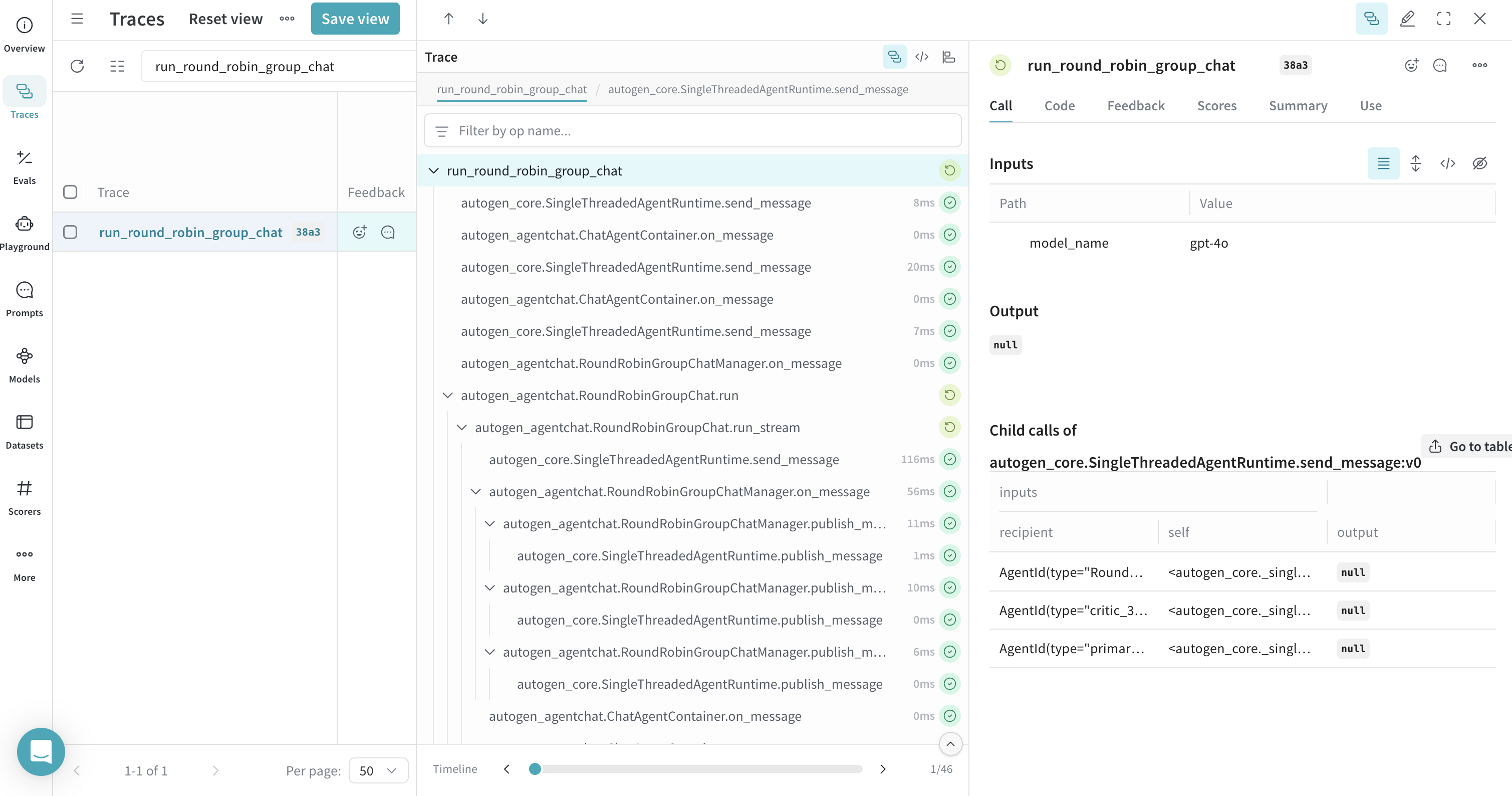
라운드 로빈 GroupChat의 트레이스
RoundRobinGroupChat과 같은 그룹 채팅에서의 상호작용은 Weave가 트레이스하므로, 에이전트 간 대화 흐름을 트레이스할 수 있습니다. 더 쉽게 확인할 수 있도록 모든 에이전트 턴을 하나의 상위 트레이스 아래로 그룹화하려면 그룹 채팅 함수를 @weave.op로 래핑하세요. 이 단계는 선택 사항이지만 권장됩니다.
from autogen_agentchat.conditions import TextMentionTermination
from autogen_agentchat.teams import RoundRobinGroupChat
# 전체 그룹 채팅을 트레이스하기 위해 여기에 weave op를 추가합니다
# 선택 사항이지만 사용하는 것을 강력히 권장합니다
@weave.op
async def run_round_robin_group_chat(model_name="gpt-4o"):
model_client = OpenAIChatCompletionClient(model=model_name)
primary_agent = AssistantAgent(
"primary",
model_client=model_client,
system_message="You are a helpful AI assistant.",
)
critic_agent = AssistantAgent(
"critic",
model_client=model_client,
system_message="Provide constructive feedback. Respond with 'APPROVE' to when your feedbacks are addressed.",
)
text_termination = TextMentionTermination("APPROVE")
team = RoundRobinGroupChat(
[primary_agent, critic_agent], termination_condition=text_termination
)
await team.reset()
# 콘솔에 스트리밍 출력하려면:
# await Console(team.run_stream(task="Write a short poem about the fall season."))
result = await team.run(task="Write a short poem about the fall season.")
print(result)
await model_client.close()
asyncio.run(run_round_robin_group_chat())
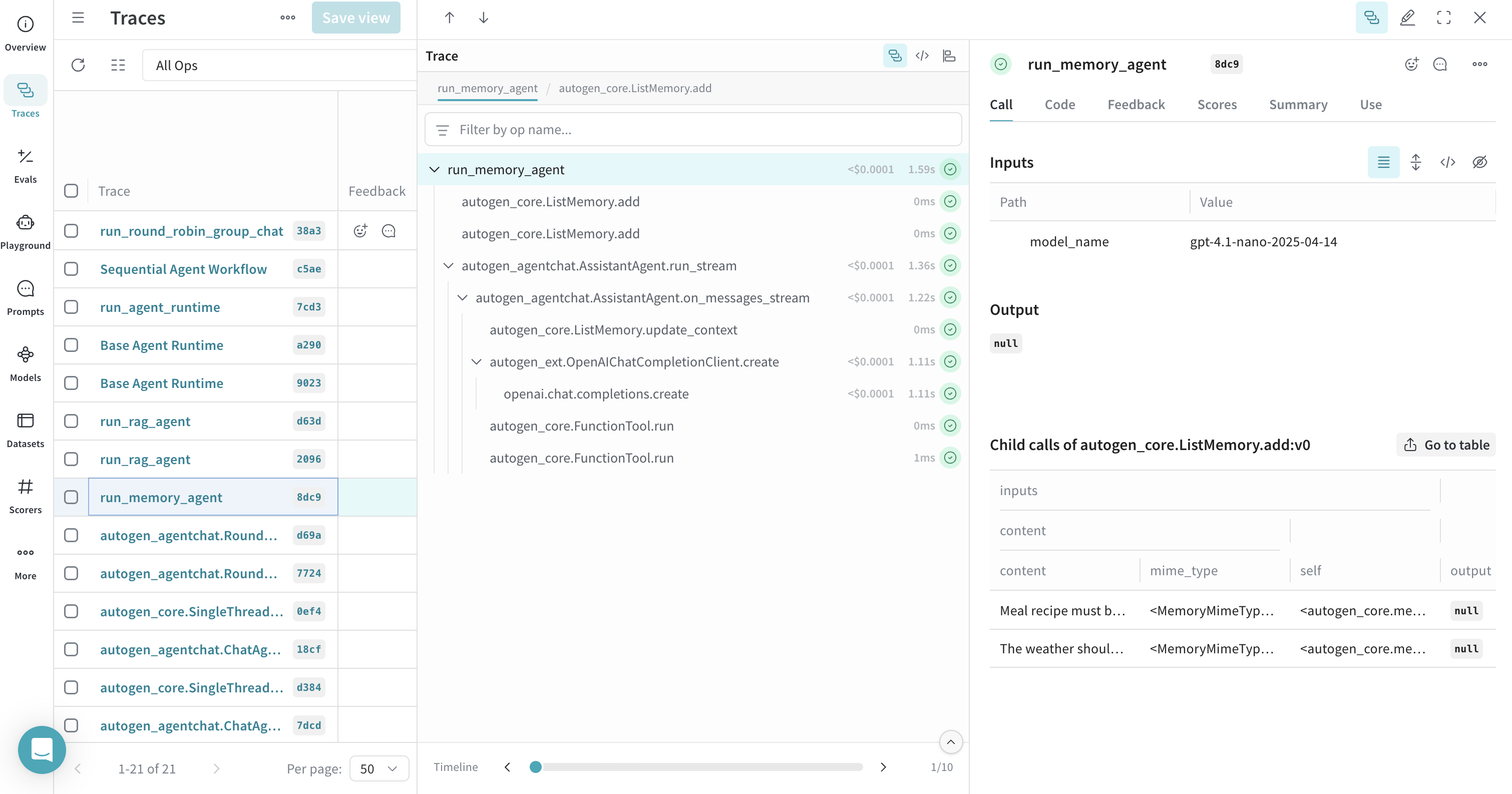
메모리용 트레이스
@weave.op()를 사용하여 메모리 오퍼레이션을 하나의 트레이스로 묶으면, 메모리 add 및 조회 Call이 이를 사용하는 에이전트 run과 함께 표시됩니다.
from autogen_core.memory import ListMemory, MemoryContent, MemoryMimeType
# 메모리 add Call과 메모리 get Call을 단일 트레이스 아래에서 트레이스하기 위해
# 여기에 weave op를 추가합니다.
# 완전히 선택 사항이지만 사용하는 것을 강력히 권장합니다.
@weave.op
async def run_memory_agent(model_name="gpt-4o"):
user_memory = ListMemory()
await user_memory.add(
MemoryContent(
content="The weather should be in metric units",
mime_type=MemoryMimeType.TEXT,
)
)
await user_memory.add(
MemoryContent(
content="Meal recipe must be vegan", mime_type=MemoryMimeType.TEXT
)
)
async def get_weather(city: str, units: str = "imperial") -> str:
if units == "imperial":
return f"The weather in {city} is 73 °F and Sunny."
elif units == "metric":
return f"The weather in {city} is 23 °C and Sunny."
else:
return f"Sorry, I don't know the weather in {city}."
model_client = OpenAIChatCompletionClient(model=model_name)
assistant_agent = AssistantAgent(
name="assistant_agent",
model_client=model_client,
tools=[get_weather],
memory=[user_memory],
)
# 콘솔에 스트리밍 출력하려면:
# stream = assistant_agent.run_stream(task="What is the weather in New York?")
# await Console(stream)
result = await assistant_agent.run(task="What is the weather in New York?")
print(result)
await model_client.close()
asyncio.run(run_memory_agent())
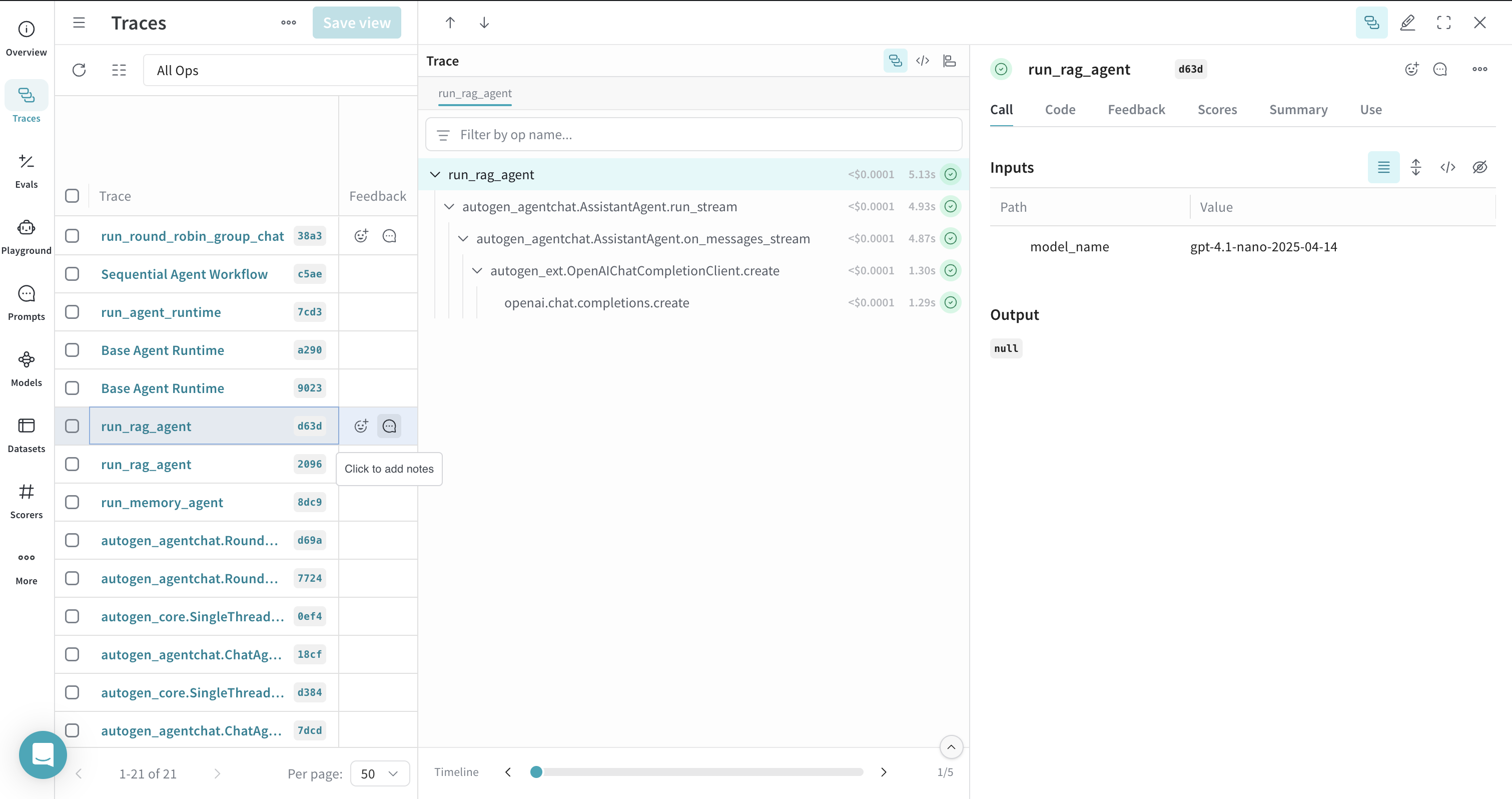
RAG 워크플로의 트레이스
ChromaDBVectorMemory와 같은 메모리 시스템을 사용한 문서 인덱싱 및 검색을 포함한 Retrieval Augmented Generation(RAG) 워크플로를 트레이싱할 수 있습니다. 인덱싱, 검색, 그리고 그에 따른 LLM Call이 하나의 트레이스에 함께 표시되도록 전체 흐름을 시각화하려면 RAG 프로세스를 @weave.op()으로 데코레이팅하세요.
이 RAG 예시를 사용하려면
chromadb가 필요합니다. pip install chromadb로 설치하세요.# !pip install -q chromadb
# 환경에 chromadb가 설치되어 있는지 확인하세요: `pip install chromadb`
import re
from typing import List
import os
from pathlib import Path
import aiofiles
import aiohttp
from autogen_core.memory import Memory, MemoryContent, MemoryMimeType
from autogen_ext.memory.chromadb import (
ChromaDBVectorMemory,
PersistentChromaDBVectorMemoryConfig,
)
class SimpleDocumentIndexer:
def __init__(self, memory: Memory, chunk_size: int = 1500) -> None:
self.memory = memory
self.chunk_size = chunk_size
async def _fetch_content(self, source: str) -> str:
if source.startswith(("http://", "https://")):
async with aiohttp.ClientSession() as session:
async with session.get(source) as response:
return await response.text()
else:
async with aiofiles.open(source, "r", encoding="utf-8") as f:
return await f.read()
def _strip_html(self, text: str) -> str:
text = re.sub(r"<[^>]*>", " ", text)
text = re.sub(r"\\s+", " ", text)
return text.strip()
def _split_text(self, text: str) -> List[str]:
chunks: list[str] = []
for i in range(0, len(text), self.chunk_size):
chunk = text[i : i + self.chunk_size]
chunks.append(chunk.strip())
return chunks
async def index_documents(self, sources: List[str]) -> int:
total_chunks = 0
for source in sources:
try:
content = await self._fetch_content(source)
if "<" in content and ">" in content:
content = self._strip_html(content)
chunks = self._split_text(content)
for i, chunk in enumerate(chunks):
await self.memory.add(
MemoryContent(
content=chunk,
mime_type=MemoryMimeType.TEXT,
metadata={"source": source, "chunk_index": i},
)
)
total_chunks += len(chunks)
except Exception as e:
print(f"Error indexing {source}: {str(e)}")
return total_chunks
@weave.op
async def run_rag_agent(model_name="gpt-4o"):
rag_memory = ChromaDBVectorMemory(
config=PersistentChromaDBVectorMemoryConfig(
collection_name="autogen_docs",
persistence_path=os.path.join(str(Path.home()), ".chromadb_autogen_weave"),
k=3,
score_threshold=0.4,
)
)
# await rag_memory.clear() # 기존 메모리를 초기화하려면 주석을 해제하세요
async def index_autogen_docs() -> None:
indexer = SimpleDocumentIndexer(memory=rag_memory)
sources = [
"https://raw.githubusercontent.com/microsoft/autogen/main/README.md",
"https://microsoft.github.io/autogen/dev/user-guide/agentchat-user-guide/tutorial/agents.html",
]
chunks: int = await indexer.index_documents(sources)
print(f"Indexed {chunks} chunks from {len(sources)} AutoGen documents")
# 컬렉션이 비어 있거나 재인덱싱이 필요한 경우에만 인덱싱하세요
# 데모 목적으로 매번 인덱싱하거나 이미 인덱싱되었는지 확인할 수 있습니다.
# 이 예시는 run마다 인덱싱을 시도합니다. 확인 로직 추가를 고려하세요.
await index_autogen_docs()
model_client = OpenAIChatCompletionClient(model=model_name)
rag_assistant = AssistantAgent(
name="rag_assistant",
model_client=model_client,
memory=[rag_memory],
)
# 콘솔에 스트리밍으로 출력하려면:
# stream = rag_assistant.run_stream(task="What is AgentChat?")
# await Console(stream)
result = await rag_assistant.run(task="What is AgentChat?")
print(result)
await rag_memory.close()
await model_client.close()
asyncio.run(run_rag_agent())
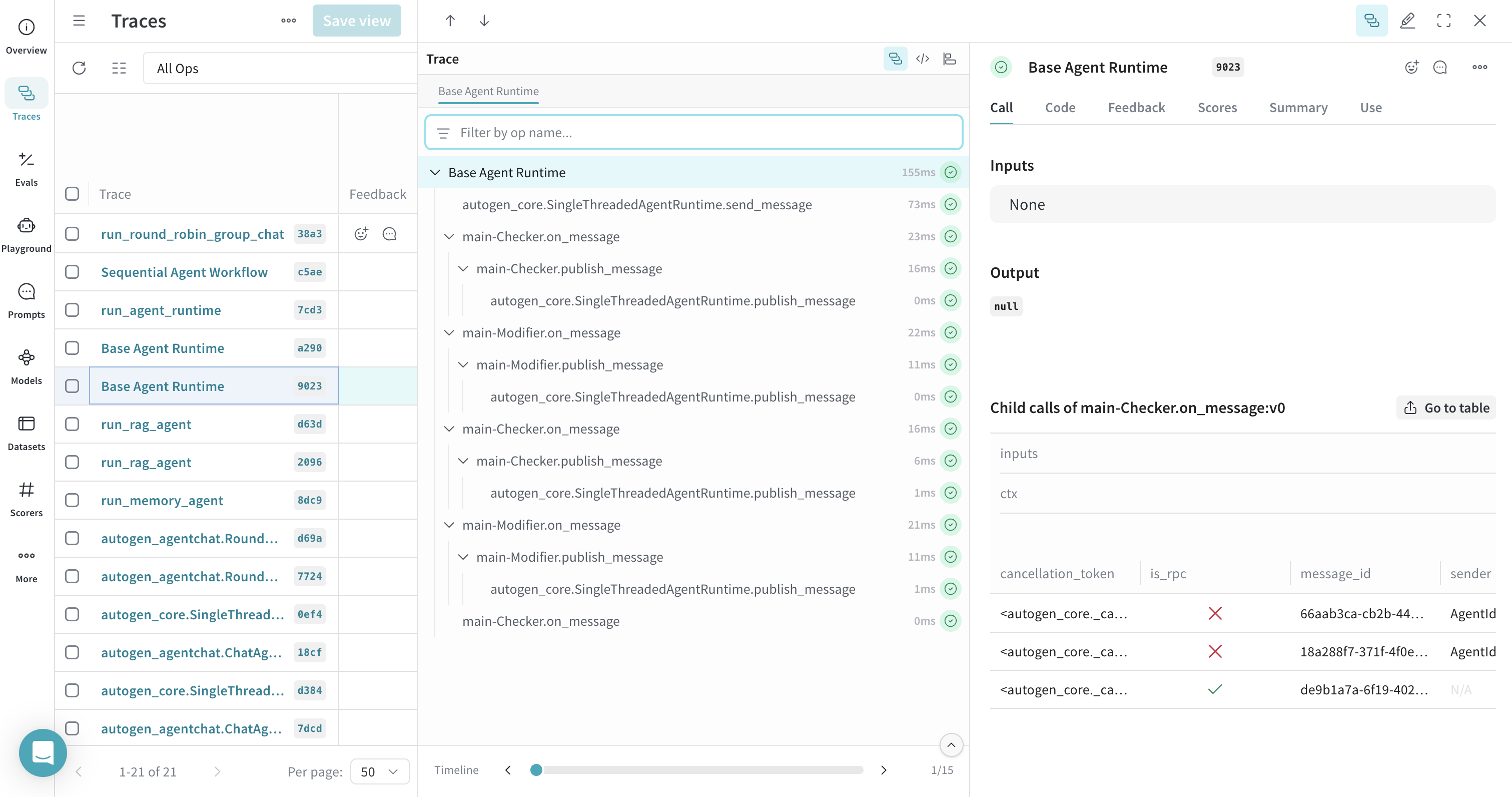
에이전트 런타임의 트레이스
SingleThreadedAgentRuntime와 같은 AutoGen의 에이전트 런타임 내부의 오퍼레이션을 트레이스할 수 있습니다. 런타임 실행 함수를 @weave.op()으로 감싸면 관련된 트레이스를 그룹화하여 런타임 run 중에 호출되는 메시지 핸들러의 전체 실행 순서를 확인할 수 있습니다.
from dataclasses import dataclass
from typing import Callable
from autogen_core import (
DefaultTopicId,
MessageContext,
RoutedAgent,
default_subscription,
message_handler,
AgentId,
SingleThreadedAgentRuntime
)
@dataclass
class Message:
content: int
@default_subscription
class Modifier(RoutedAgent):
def __init__(self, modify_val: Callable[[int], int]) -> None:
super().__init__("A modifier agent.")
self._modify_val = modify_val
@message_handler
async def handle_message(self, message: Message, ctx: MessageContext) -> None:
val = self._modify_val(message.content)
print(f"{'-'*80}\\nModifier:\\nModified {message.content} to {val}")
await self.publish_message(Message(content=val), DefaultTopicId())
@default_subscription
class Checker(RoutedAgent):
def __init__(self, run_until: Callable[[int], bool]) -> None:
super().__init__("A checker agent.")
self._run_until = run_until
@message_handler
async def handle_message(self, message: Message, ctx: MessageContext) -> None:
if not self._run_until(message.content):
print(f"{'-'*80}\\nChecker:\\n{message.content} passed the check, continue.")
await self.publish_message(
Message(content=message.content), DefaultTopicId()
)
else:
print(f"{'-'*80}\\nChecker:\\n{message.content} failed the check, stopping.")
# 전체 에이전트 런타임 Call을 하나의 트레이스로 추적하기 위해
# 여기에서 weave op를 추가합니다
# 완전히 선택 사항이지만 사용을 강력히 권장합니다
@weave.op
async def run_agent_runtime() -> None:
runtime = SingleThreadedAgentRuntime()
await Modifier.register(
runtime,
"modifier",
lambda: Modifier(modify_val=lambda x: x - 1),
)
await Checker.register(
runtime,
"checker",
lambda: Checker(run_until=lambda x: x <= 1),
)
runtime.start()
await runtime.send_message(Message(content=3), AgentId("checker", "default"))
await runtime.stop_when_idle()
asyncio.run(run_agent_runtime())
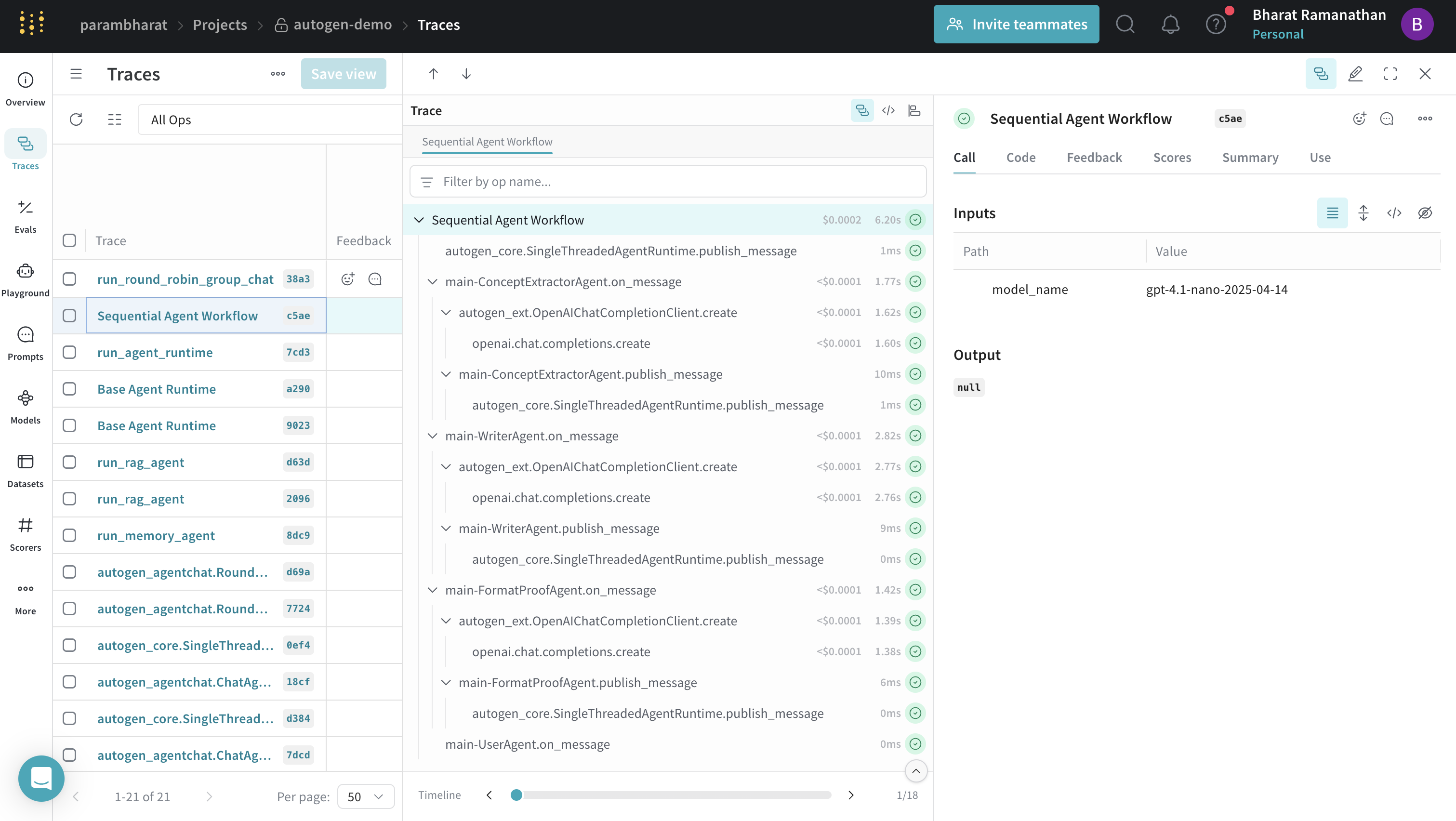
순차적 워크플로를 위한 트레이스
@weave.op()를 사용하세요. 다음 예시에서는 개념 추출기, 작성기, 형식 지정 및 교정 에이전트, 그리고 사용자 에이전트를 체인으로 연결해 완성도 높은 마케팅 카피를 생성합니다.
from autogen_core import TopicId, type_subscription
from autogen_core.models import ChatCompletionClient, SystemMessage, UserMessage
@dataclass
class WorkflowMessage:
content: str
concept_extractor_topic_type = "ConceptExtractorAgent"
writer_topic_type = "WriterAgent"
format_proof_topic_type = "FormatProofAgent"
user_topic_type = "User"
@type_subscription(topic_type=concept_extractor_topic_type)
class ConceptExtractorAgent(RoutedAgent):
def __init__(self, model_client: ChatCompletionClient) -> None:
super().__init__("A concept extractor agent.")
self._system_message = SystemMessage(
content=(
"You are a marketing analyst. Given a product description, identify:\n"
"- Key features\n"
"- Target audience\n"
"- Unique selling points\n\n"
)
)
self._model_client = model_client
@message_handler
async def handle_user_description(self, message: WorkflowMessage, ctx: MessageContext) -> None:
prompt = f"Product description: {message.content}"
llm_result = await self._model_client.create(
messages=[self._system_message, UserMessage(content=prompt, source=self.id.key)],
cancellation_token=ctx.cancellation_token,
)
response = llm_result.content
assert isinstance(response, str)
print(f"{'-'*80}\\n{self.id.type}:\\n{response}")
await self.publish_message(
WorkflowMessage(response), topic_id=TopicId(writer_topic_type, source=self.id.key)
)
@type_subscription(topic_type=writer_topic_type)
class WriterAgent(RoutedAgent):
def __init__(self, model_client: ChatCompletionClient) -> None:
super().__init__("A writer agent.")
self._system_message = SystemMessage(
content=(
"You are a marketing copywriter. Given a block of text describing features, audience, and USPs, "
"compose a compelling marketing copy (like a newsletter section) that highlights these points. "
"Output should be short (around 150 words), output just the copy as a single text block."
)
)
self._model_client = model_client
@message_handler
async def handle_intermediate_text(self, message: WorkflowMessage, ctx: MessageContext) -> None:
prompt = f"Below is the info about the product:\\n\\n{message.content}"
llm_result = await self._model_client.create(
messages=[self._system_message, UserMessage(content=prompt, source=self.id.key)],
cancellation_token=ctx.cancellation_token,
)
response = llm_result.content
assert isinstance(response, str)
print(f"{'-'*80}\\n{self.id.type}:\\n{response}")
await self.publish_message(
WorkflowMessage(response), topic_id=TopicId(format_proof_topic_type, source=self.id.key)
)
@type_subscription(topic_type=format_proof_topic_type)
class FormatProofAgent(RoutedAgent):
def __init__(self, model_client: ChatCompletionClient) -> None:
super().__init__("A format & proof agent.")
self._system_message = SystemMessage(
content=(
"You are an editor. Given the draft copy, correct grammar, improve clarity, ensure consistent tone, "
"give format and make it polished. Output the final improved copy as a single text block."
)
)
self._model_client = model_client
@message_handler
async def handle_intermediate_text(self, message: WorkflowMessage, ctx: MessageContext) -> None:
prompt = f"Draft copy:\\n{message.content}."
llm_result = await self._model_client.create(
messages=[self._system_message, UserMessage(content=prompt, source=self.id.key)],
cancellation_token=ctx.cancellation_token,
)
response = llm_result.content
assert isinstance(response, str)
print(f"{'-'*80}\\n{self.id.type}:\\n{response}")
await self.publish_message(
WorkflowMessage(response), topic_id=TopicId(user_topic_type, source=self.id.key)
)
@type_subscription(topic_type=user_topic_type)
class UserAgent(RoutedAgent):
def __init__(self) -> None:
super().__init__("A user agent that outputs the final copy to the user.")
@message_handler
async def handle_final_copy(self, message: WorkflowMessage, ctx: MessageContext) -> None:
print(f"\\n{'-'*80}\\n{self.id.type} received final copy:\\n{message.content}")
# we add this weave op here because we want to trace
# the entire agent workflow under a single trace
# it's completely optional but highly recommended to use it
@weave.op(call_display_name="Sequential Agent Workflow")
async def run_agent_workflow(model_name="gpt-4o"):
model_client = OpenAIChatCompletionClient(model=model_name)
runtime = SingleThreadedAgentRuntime()
await ConceptExtractorAgent.register(runtime, type=concept_extractor_topic_type, factory=lambda: ConceptExtractorAgent(model_client=model_client))
await WriterAgent.register(runtime, type=writer_topic_type, factory=lambda: WriterAgent(model_client=model_client))
await FormatProofAgent.register(runtime, type=format_proof_topic_type, factory=lambda: FormatProofAgent(model_client=model_client))
await UserAgent.register(runtime, type=user_topic_type, factory=lambda: UserAgent())
runtime.start()
await runtime.publish_message(
WorkflowMessage(
content="An eco-friendly stainless steel water bottle that keeps drinks cold for 24 hours"
),
topic_id=TopicId(concept_extractor_topic_type, source="default"),
)
await runtime.stop_when_idle()
await model_client.close()
asyncio.run(run_agent_workflow())
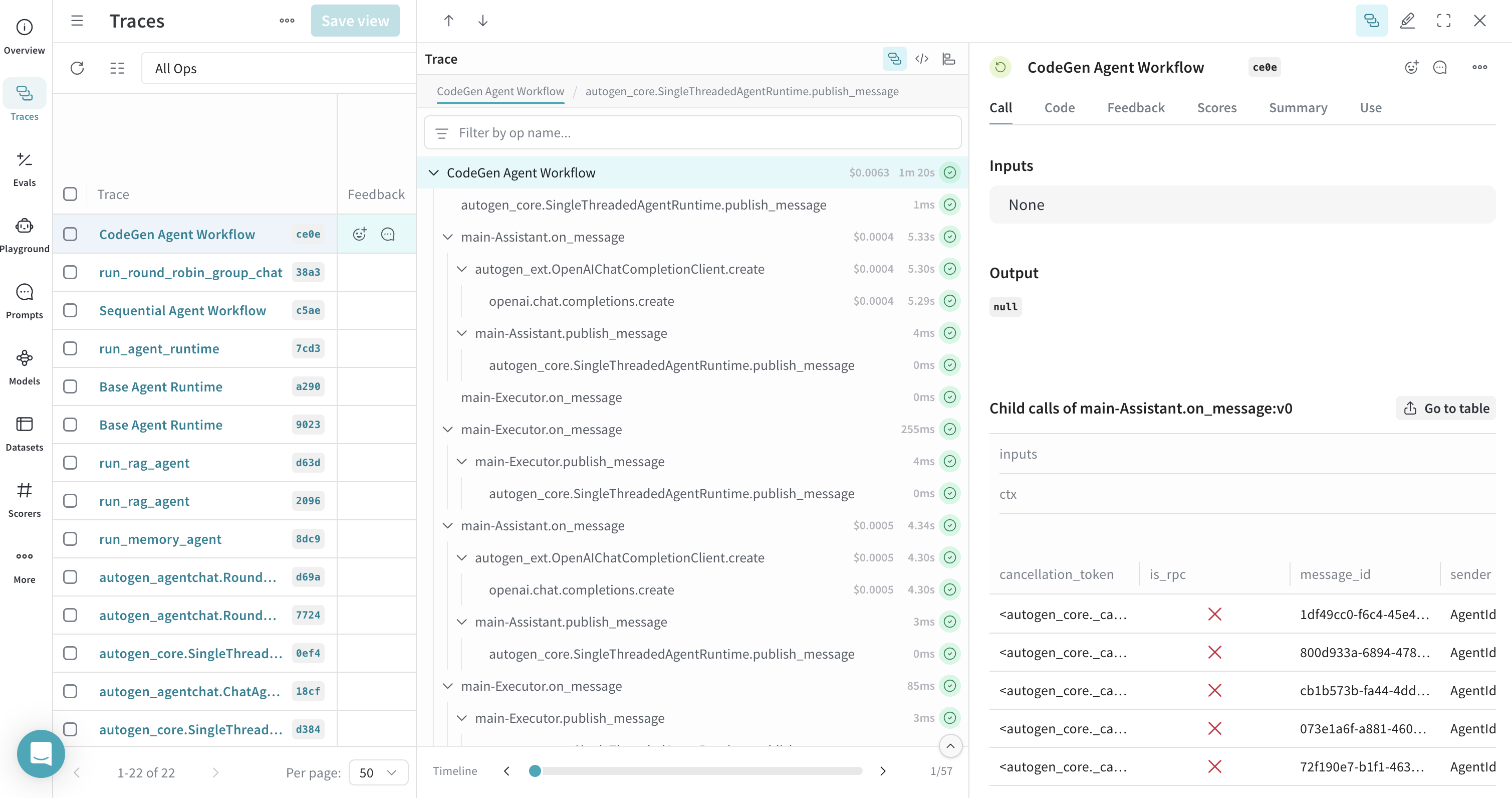
코드 실행기를 위한 트레이스
Docker 필요
이 예시에는 Docker를 사용한 코드 실행이 포함되어 있어 모든 환경(예: Colab)에서 작동하지 않을 수 있습니다. 이 예시를 사용해 보려면 로컬에서 Docker가 실행 중인지 확인하세요.
import tempfile
from autogen_core import DefaultTopicId
from autogen_core.code_executor import CodeBlock, CodeExecutor
from autogen_core.models import (
AssistantMessage,
ChatCompletionClient,
LLMMessage,
SystemMessage,
UserMessage,
)
from autogen_ext.code_executors.docker import DockerCommandLineCodeExecutor
@dataclass
class CodeGenMessage:
content: str
@default_subscription
class Assistant(RoutedAgent):
def __init__(self, model_client: ChatCompletionClient) -> None:
super().__init__("An assistant agent.")
self._model_client = model_client
self._chat_history: List[LLMMessage] = [
SystemMessage(
content="""Write Python script in markdown block, and it will be executed.
Always save figures to file in the current directory. Do not use plt.show(). All code required to complete this task must be contained within a single response.""",
)
]
@message_handler
async def handle_message(self, message: CodeGenMessage, ctx: MessageContext) -> None:
self._chat_history.append(UserMessage(content=message.content, source="user"))
result = await self._model_client.create(self._chat_history)
print(f"\\n{'-'*80}\\nAssistant:\\n{result.content}")
self._chat_history.append(AssistantMessage(content=result.content, source="assistant"))
await self.publish_message(CodeGenMessage(content=result.content), DefaultTopicId())
def extract_markdown_code_blocks(markdown_text: str) -> List[CodeBlock]:
pattern = re.compile(r"```(?:\\s*([\\w\\+\\-]+))?\\n([\\s\\S]*?)```")
matches = pattern.findall(markdown_text)
code_blocks: List[CodeBlock] = []
for match in matches:
language = match[0].strip() if match[0] else ""
code_content = match[1]
code_blocks.append(CodeBlock(code=code_content, language=language))
return code_blocks
@default_subscription
class Executor(RoutedAgent):
def __init__(self, code_executor: CodeExecutor) -> None:
super().__init__("An executor agent.")
self._code_executor = code_executor
@message_handler
async def handle_message(self, message: CodeGenMessage, ctx: MessageContext) -> None:
code_blocks = extract_markdown_code_blocks(message.content)
if code_blocks:
result = await self._code_executor.execute_code_blocks(
code_blocks, cancellation_token=ctx.cancellation_token
)
print(f"\\n{'-'*80}\\nExecutor:\\n{result.output}")
await self.publish_message(CodeGenMessage(content=result.output), DefaultTopicId())
# 전체 코드 생성 워크플로를 단일 트레이스로 트레이스하기 위해
# 여기에 weave op를 추가합니다
# 선택 사항이지만 사용하는 것을 강력히 권장합니다
@weave.op(call_display_name="CodeGen Agent Workflow")
async def run_codegen(model_name="gpt-4o"): # 업데이트된 모델
work_dir = tempfile.mkdtemp()
runtime = SingleThreadedAgentRuntime()
# 이 예제를 실행하려면 Docker가 실행 중이어야 합니다
try:
async with DockerCommandLineCodeExecutor(work_dir=work_dir) as executor:
model_client = OpenAIChatCompletionClient(model=model_name)
await Assistant.register(runtime, "assistant", lambda: Assistant(model_client=model_client))
await Executor.register(runtime, "executor", lambda: Executor(executor))
runtime.start()
await runtime.publish_message(
CodeGenMessage(content="Create a plot of NVDA vs TSLA stock returns YTD from 2024-01-01."),
DefaultTopicId(),
)
await runtime.stop_when_idle()
await model_client.close()
except Exception as e:
print(f"Could not run Docker code executor example: {e}")
print("Please ensure Docker is installed and running.")
finally:
import shutil
shutil.rmtree(work_dir)
asyncio.run(run_codegen())
더 알아보기
- Weave:
- AutoGen: