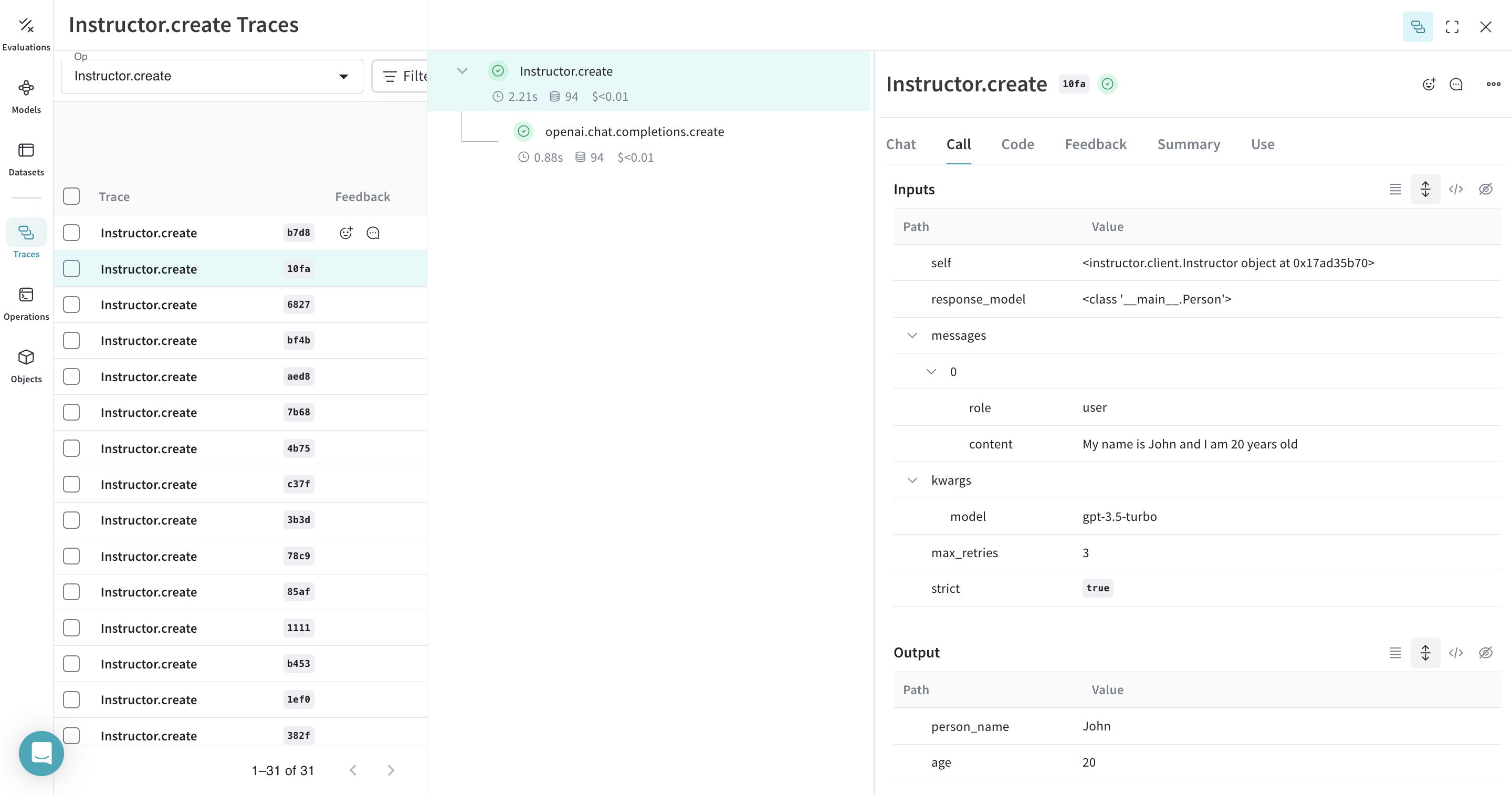
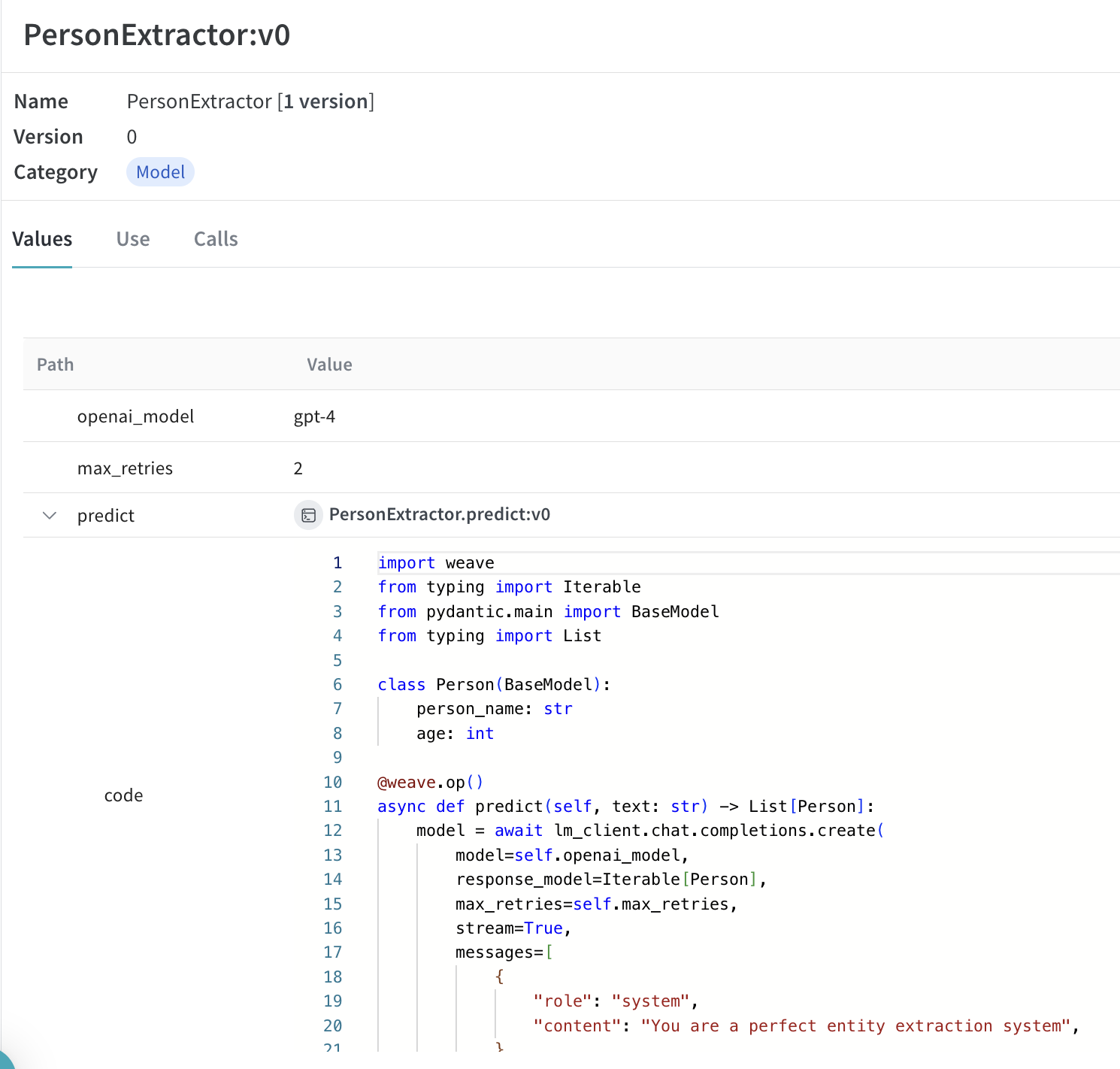
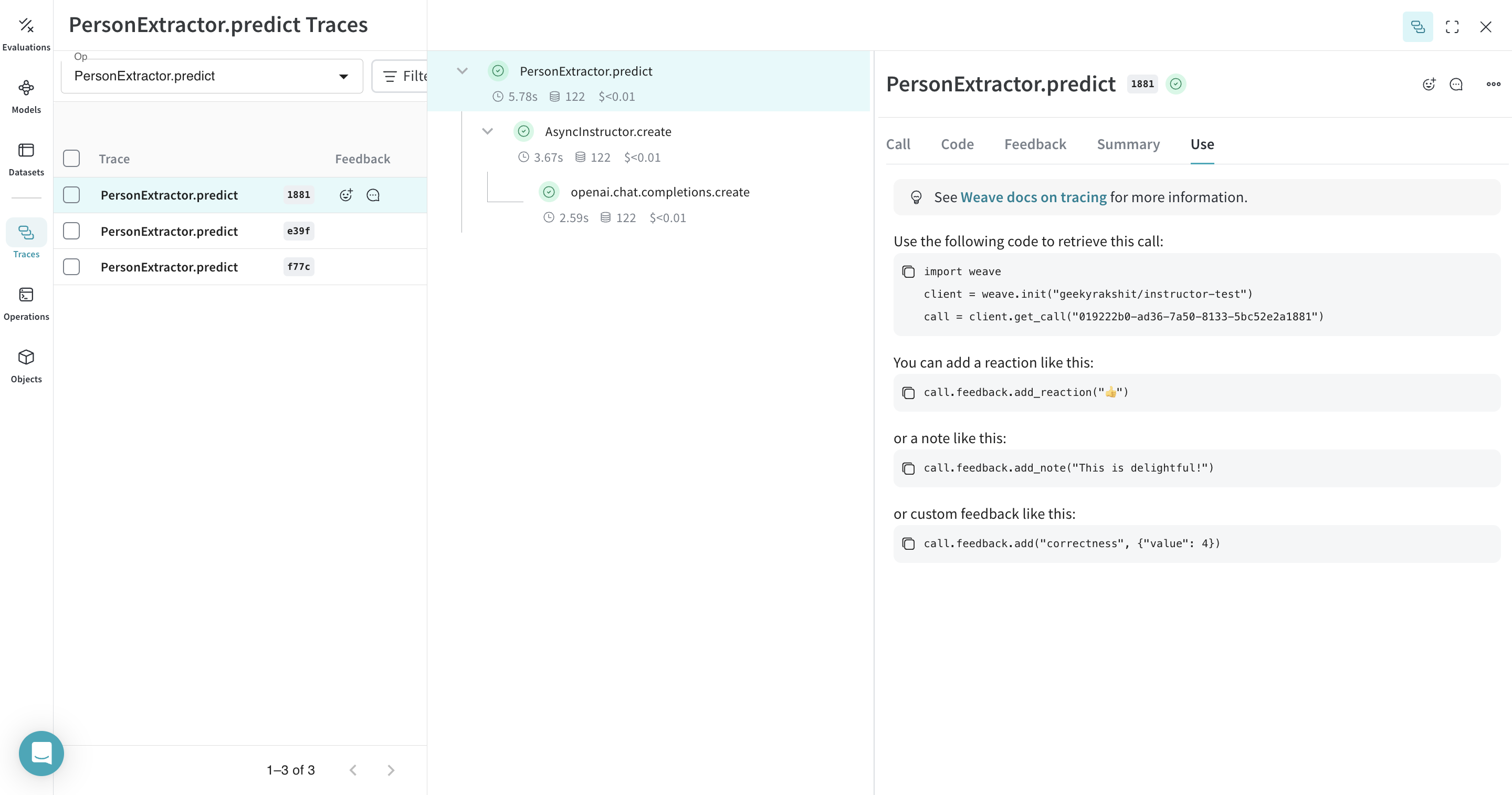
import asyncio
from typing import List, Iterable
import instructor
import weave
from openai import AsyncOpenAI
from pydantic import BaseModel
# 원하는 출력 구조 정의
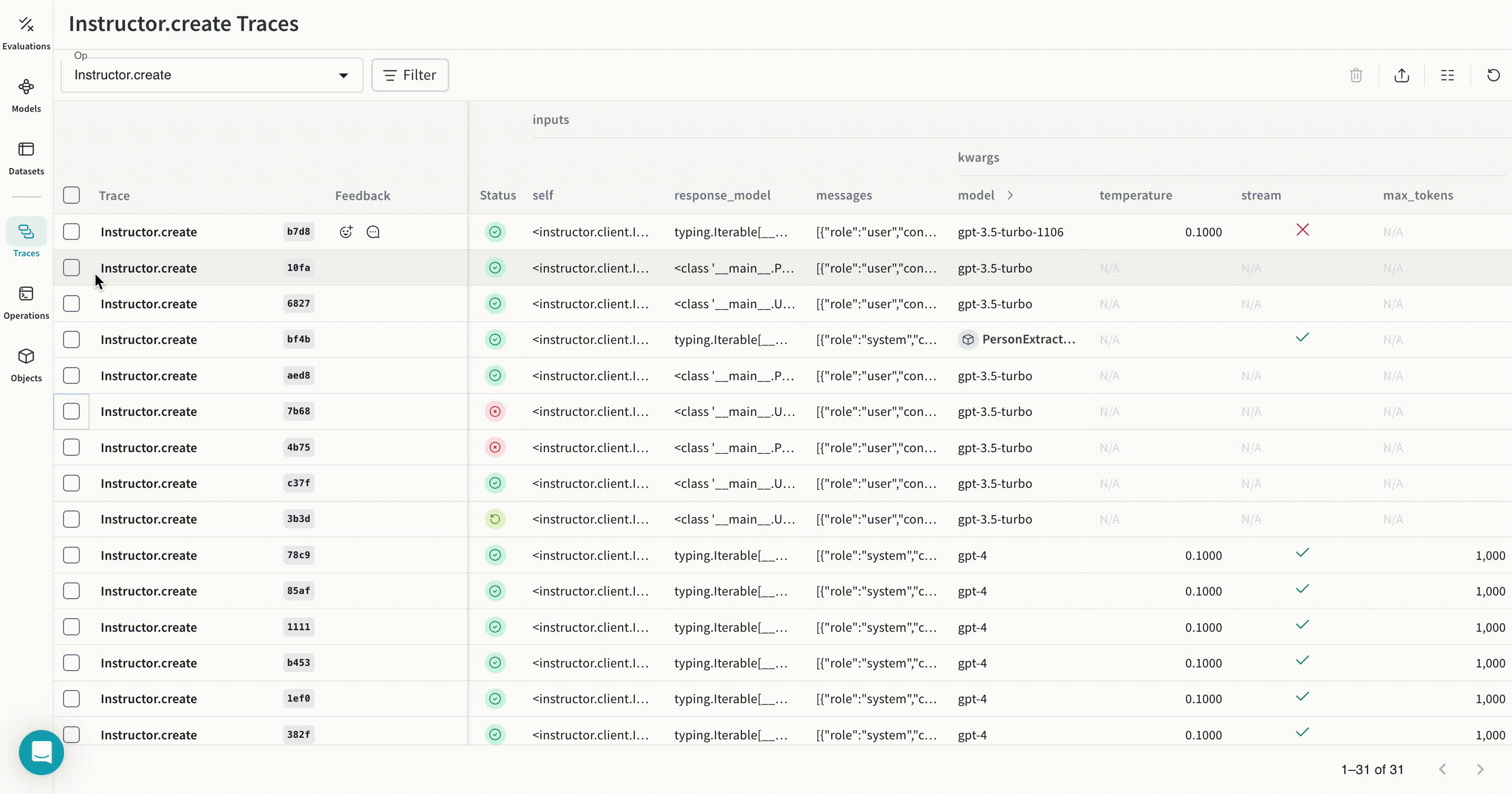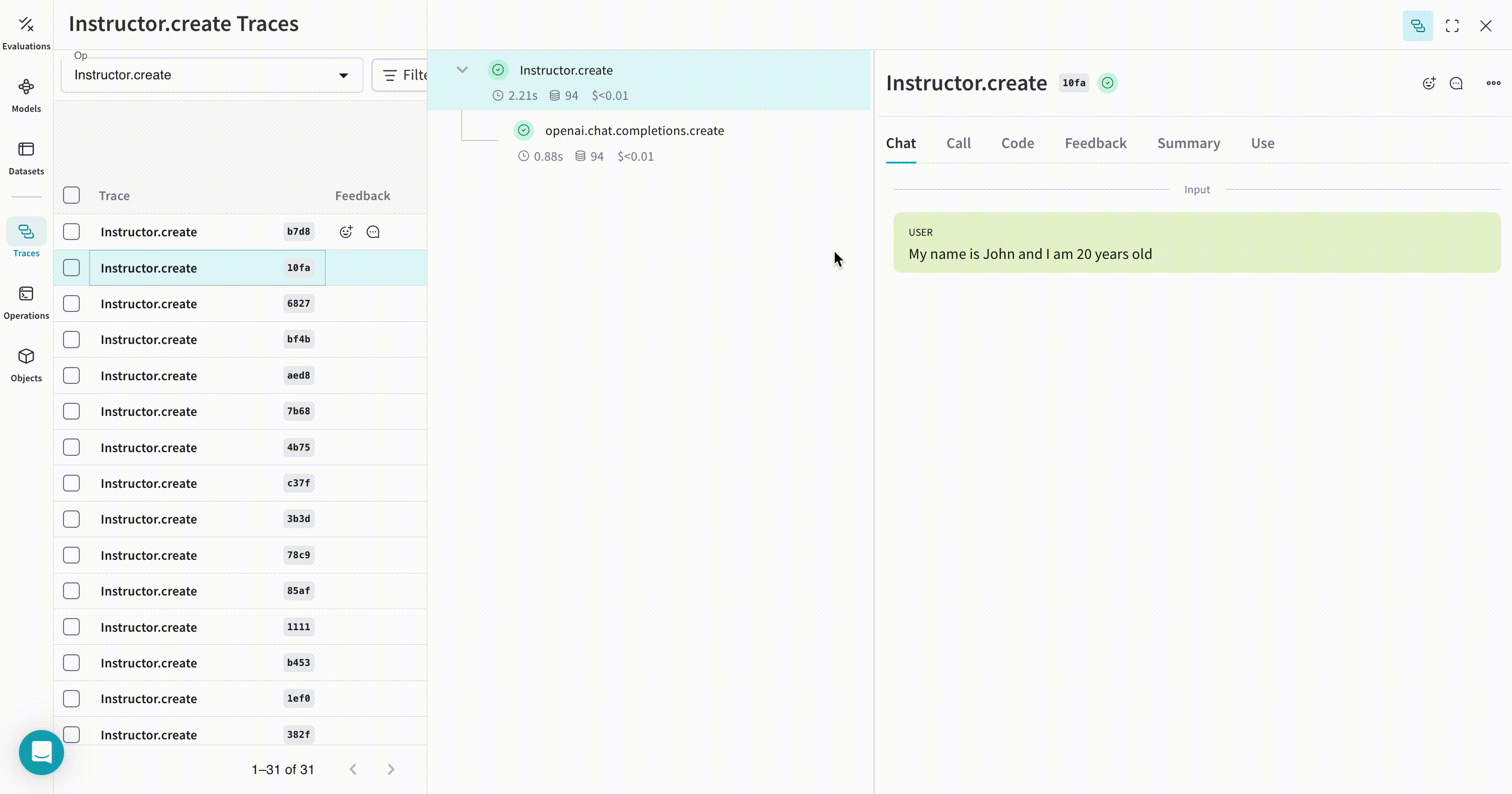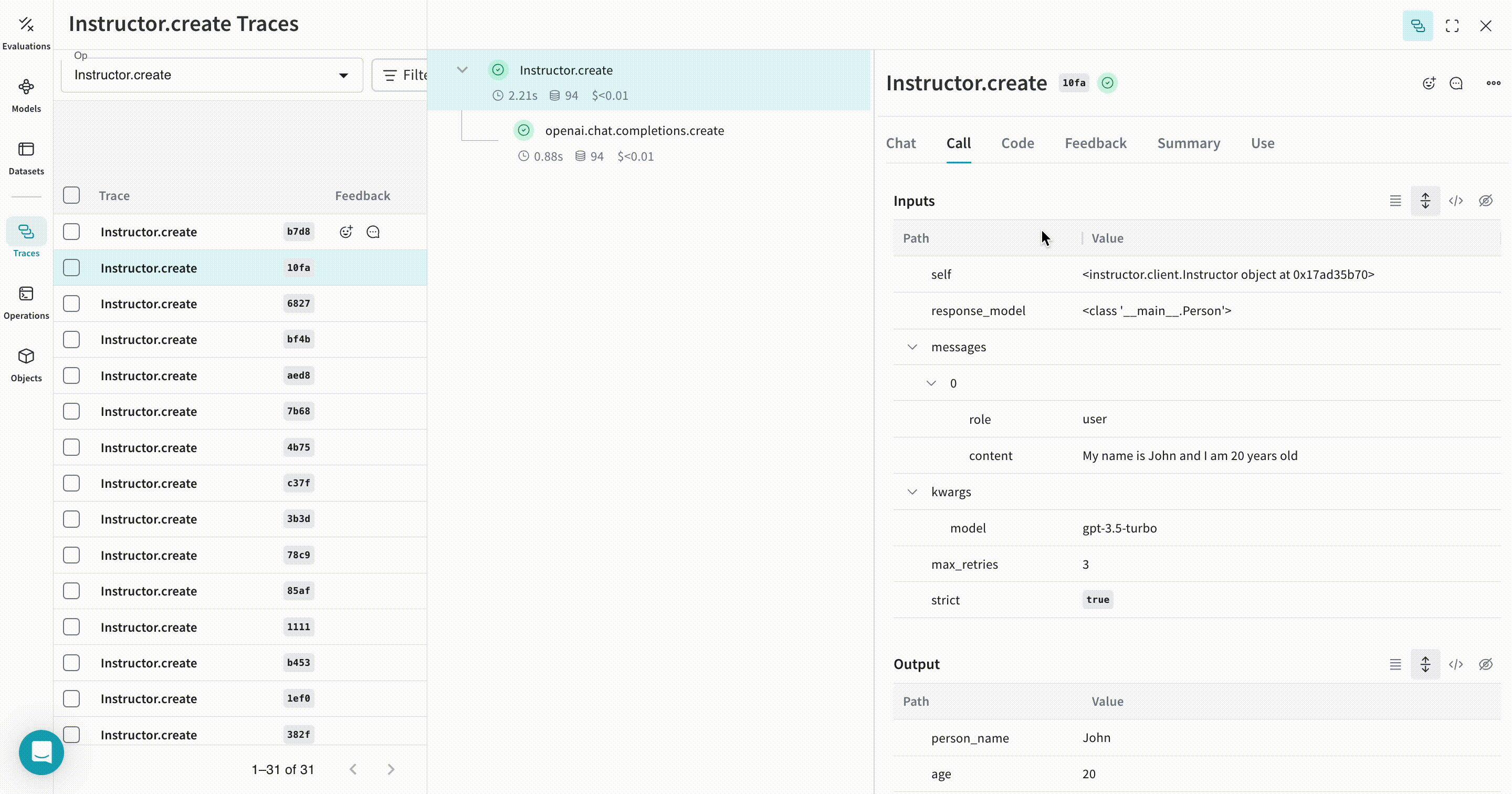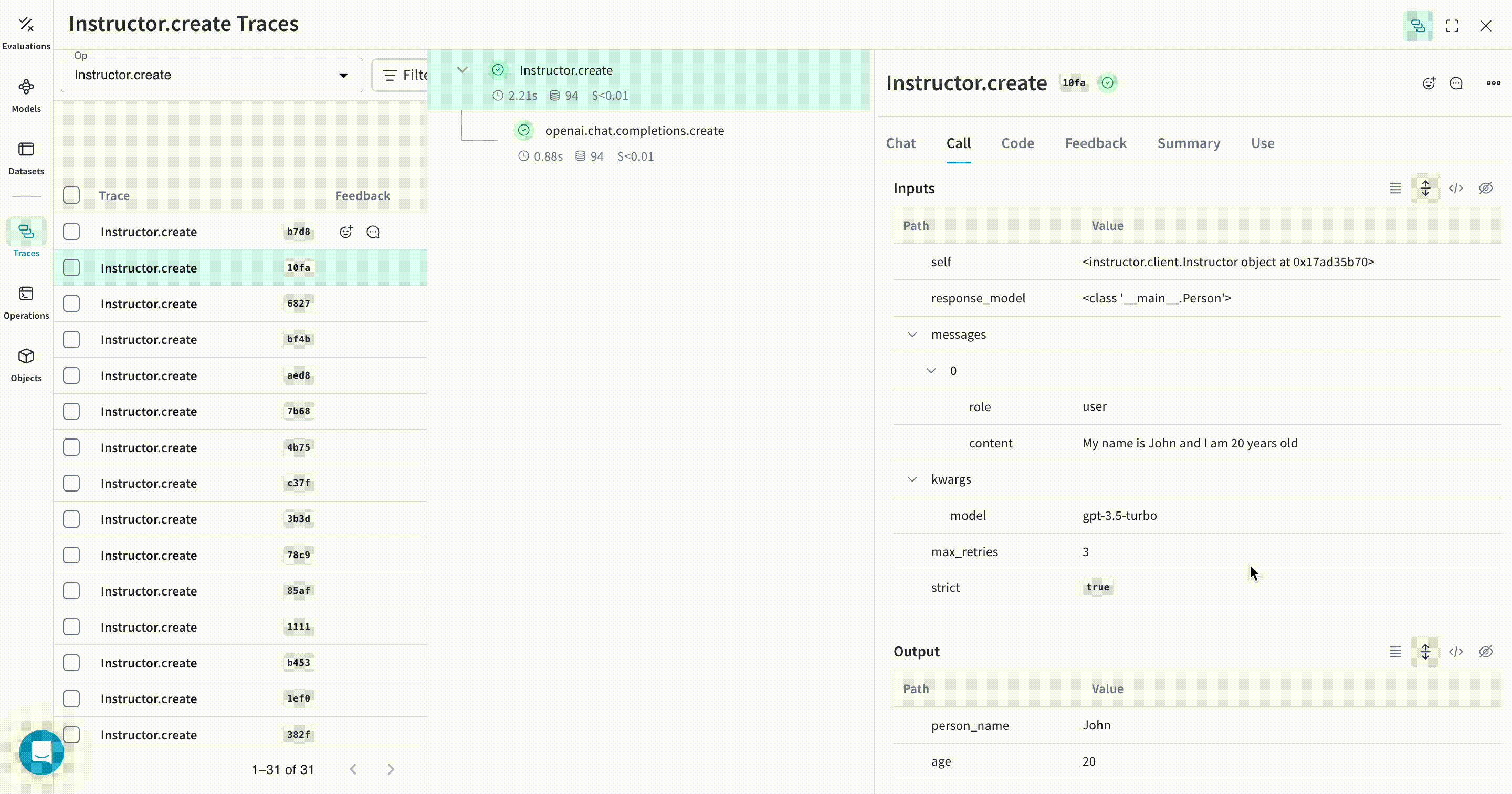
class Person(BaseModel):
person_name: str
age: int
# Weave 초기화
weave.init(project_name="instructor-test")
# OpenAI 클라이언트 패치
lm_client = instructor.from_openai(AsyncOpenAI())
class PersonExtractor(weave.Model):
openai_model: str
max_retries: int
@weave.op()
async def predict(self, text: str) -> List[Person]:
model = await lm_client.chat.completions.create(
model=self.openai_model,
response_model=Iterable[Person],
max_retries=self.max_retries,
stream=True,
messages=[
{
"role": "system",
"content": "You are a perfect entity extraction system",
},
{
"role": "user",
"content": f"Extract `{text}`",
},
],
)
return [m async for m in model]
model = PersonExtractor(openai_model="gpt-4", max_retries=2)
asyncio.run(model.predict("John is 30 years old"))