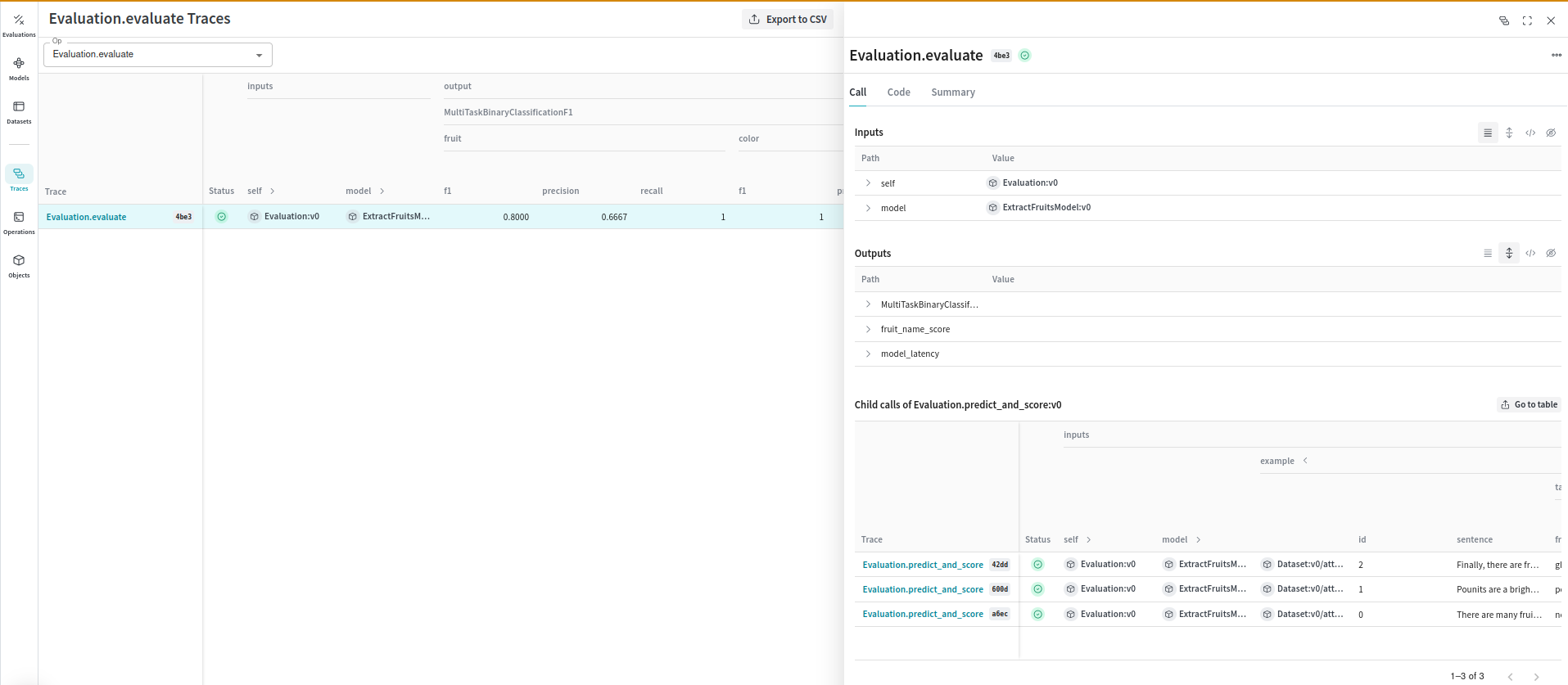
from weave.scorers import MultiTaskBinaryClassificationF1
sentences = [
"There are many fruits that were found on the recently discovered planet Goocrux. There are neoskizzles that grow there, which are purple and taste like candy.",
"Pounits are a bright green color and are more savory than sweet.",
"Finally, there are fruits called glowls, which have a very sour and bitter taste which is acidic and caustic, and a pale orange tinge to them.",
]
labels = [
{"fruit": "neoskizzles", "color": "purple", "flavor": "candy"},
{"fruit": "pounits", "color": "bright green", "flavor": "savory"},
{"fruit": "glowls", "color": "pale orange", "flavor": "sour and bitter"},
]
examples = [
{"id": "0", "sentence": sentences[0], "target": labels[0]},
{"id": "1", "sentence": sentences[1], "target": labels[1]},
{"id": "2", "sentence": sentences[2], "target": labels[2]},
]
@weave.op()
def fruit_name_score(target: dict, output: dict) -> dict:
return {"correct": target["fruit"] == output["fruit"]}
evaluation = weave.Evaluation(
dataset=examples,
scorers=[
MultiTaskBinaryClassificationF1(class_names=["fruit", "color", "flavor"]),
fruit_name_score,
],
)
scores = asyncio.run(evaluation.evaluate(model)))
# Jupyter Notebook에서 실행하는 경우:
# scores = await evaluation.evaluate(model)
print(scores)

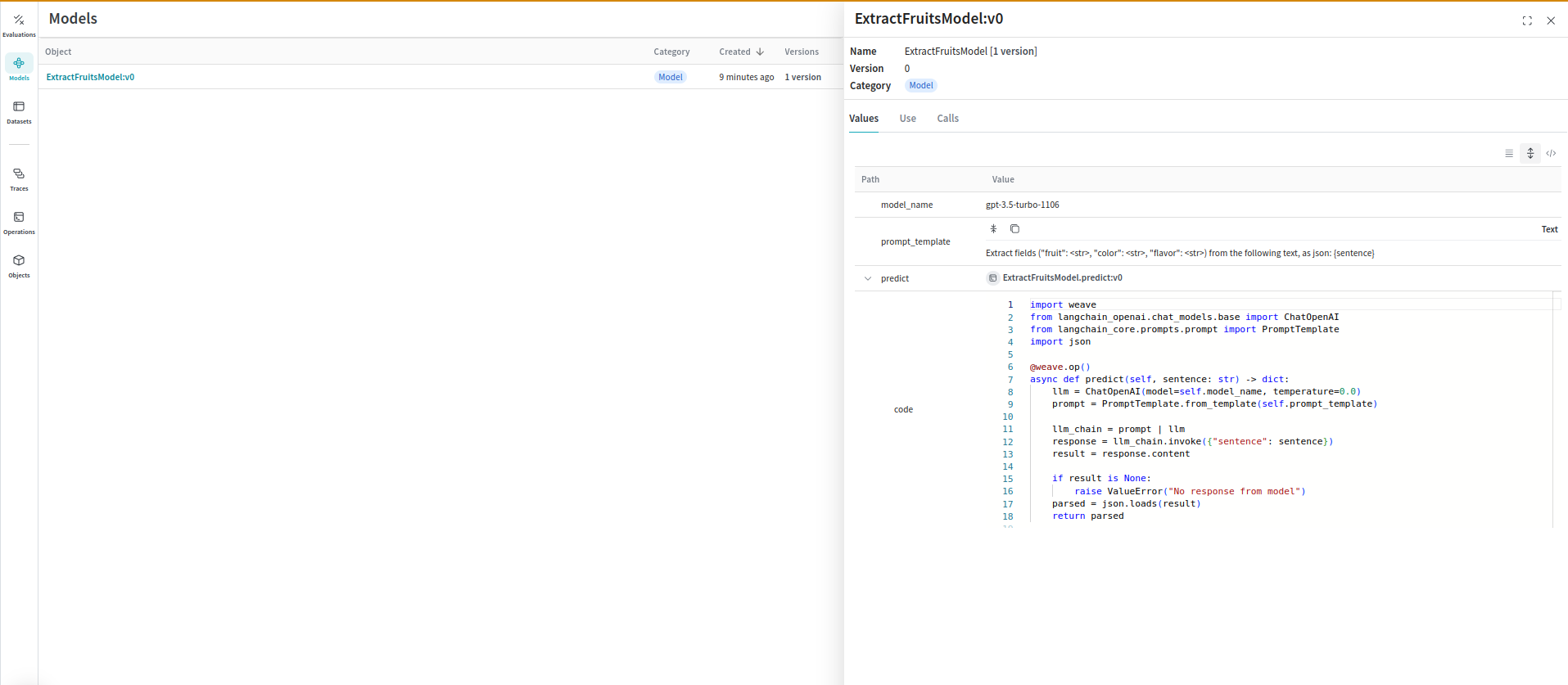 또한 Weave Models를
또한 Weave Models를