Install prerequisites
Before you can train a model and log results to W&B, install the AutoTrain CLI and the W&B client library. Installautotrain-advanced and wandb.
- Command Line
- Notebook
pass@1 on the GSM8k Benchmarks.
Prepare the dataset
Before training, prepare your dataset so it matches the format AutoTrain expects. Hugging Face AutoTrain expects your CSV custom dataset to have a specific format to work properly. Your training file must contain atext column, which the training uses. The data in the text column must conform to the ### Human: Question?### Assistant: Answer. format. Review an example in timdettmers/openassistant-guanaco.
However, the MetaMathQA dataset includes the columns query, response, and type. First, pre-process this dataset. Remove the type column and combine the contents of the query and response columns into a new text column in the ### Human: Query?### Assistant: Response. format. Training uses the resulting dataset, rishiraj/guanaco-style-metamath.
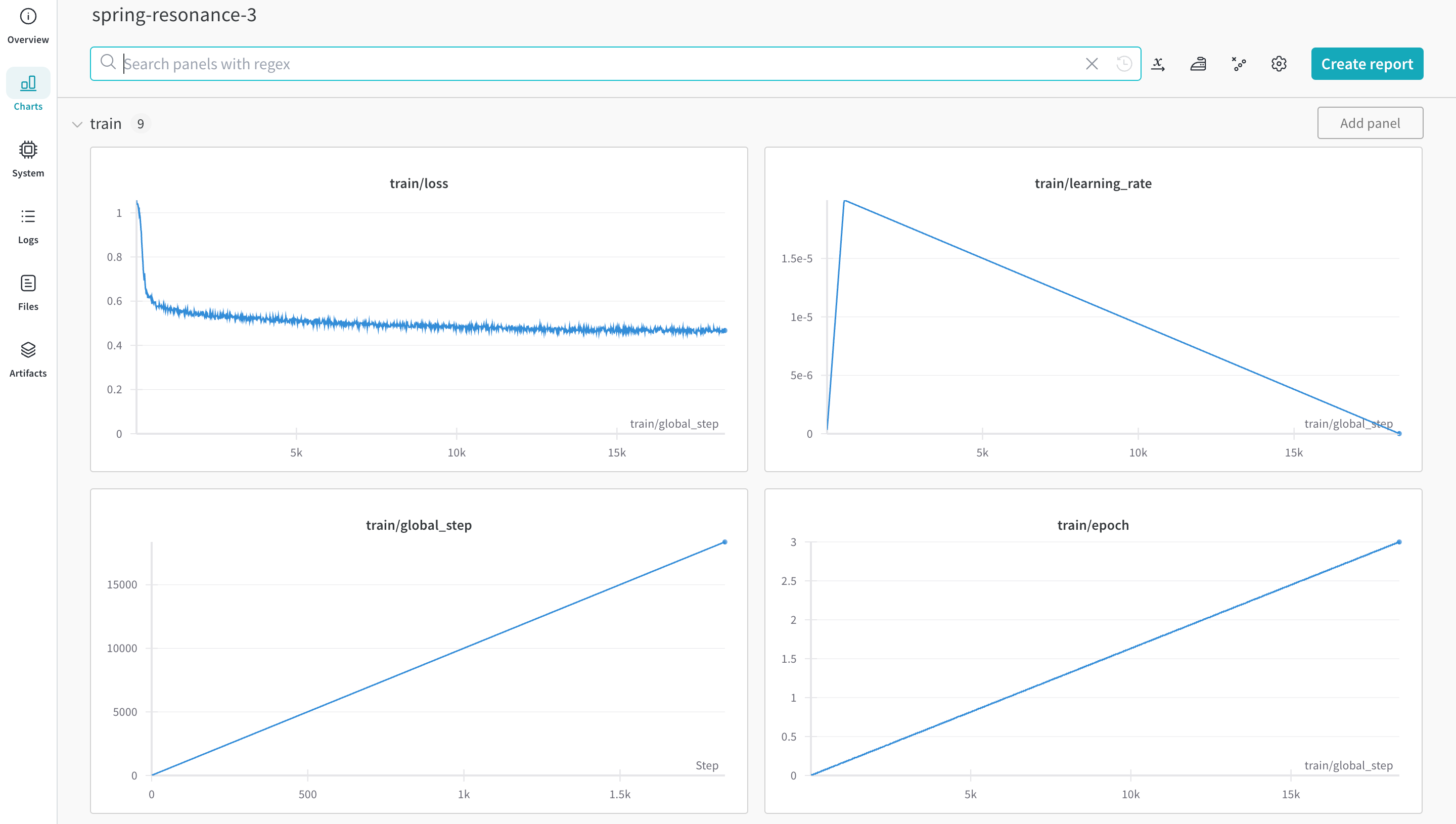
Train using autotrain
With your environment and dataset ready, you can now start training. Start training with the autotrain advanced from the command line or a notebook. Use the --log argument, or use --log wandb to log your results to a run. The --log wandb argument enables the W&B integration for this run.
Replace <huggingface-token> with your Hugging Face access token and <huggingface-repository-address> with the target repository address (for example, your-username/your-repo).
- Command Line
- Notebook