WandbLogger.
This page shows you how to use WandbLogger to track metrics, log hyperparameters, save model checkpoints as artifacts, log media, and run multi-GPU training with PyTorch Lightning and W&B.
Integrate with Lightning
The following sections show how to authenticate with W&B, install thewandb library, and attach a WandbLogger to your Lightning Trainer or Fabric instance.
- PyTorch Logger
- Fabric Logger
Using
wandb.log(): The WandbLogger logs to W&B using the Trainer’s global_step. If you make additional calls to wandb.log() directly in your code, don’t use the step argument in wandb.log().Instead, log the Trainer’s global_step like your other metrics: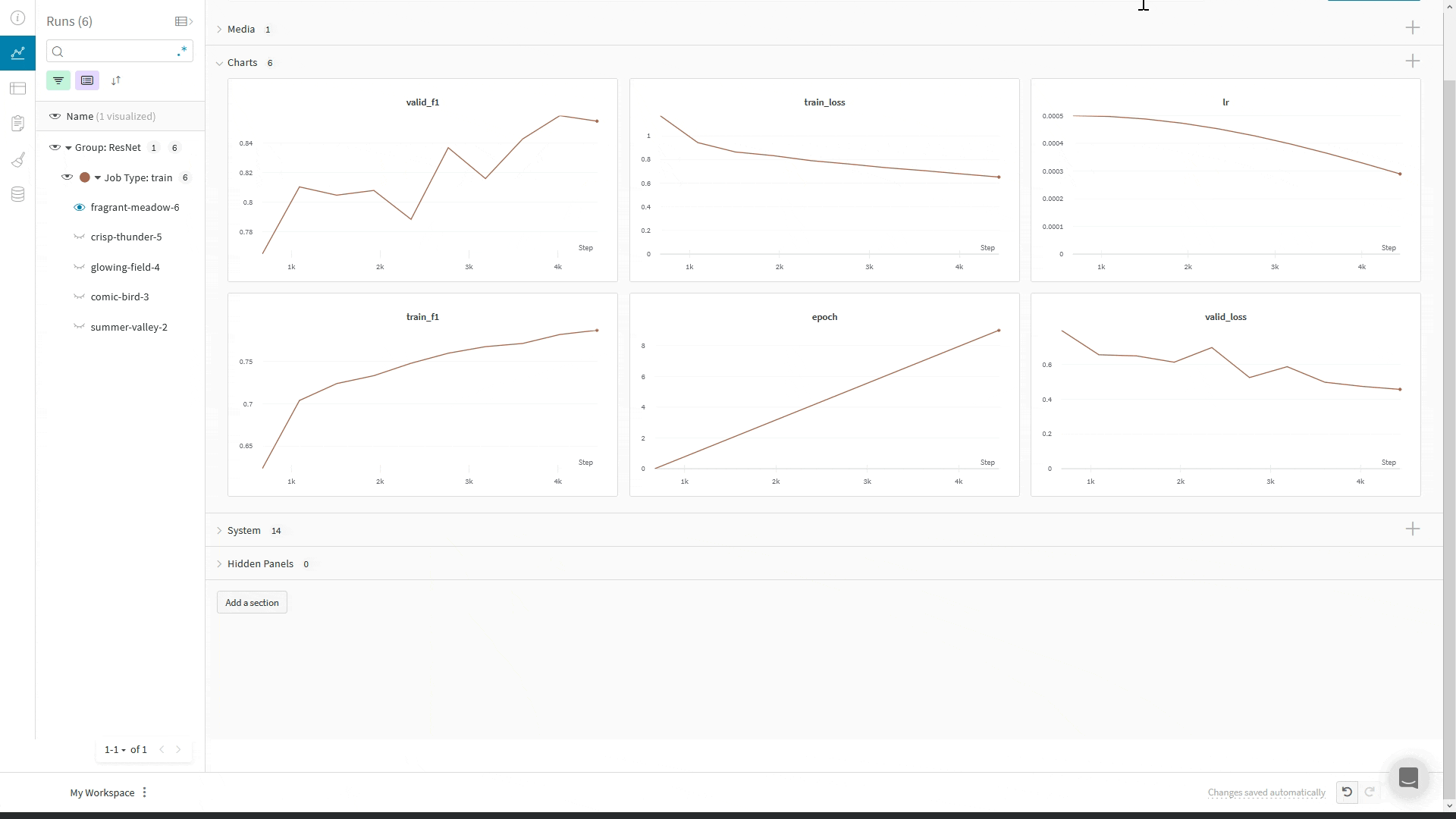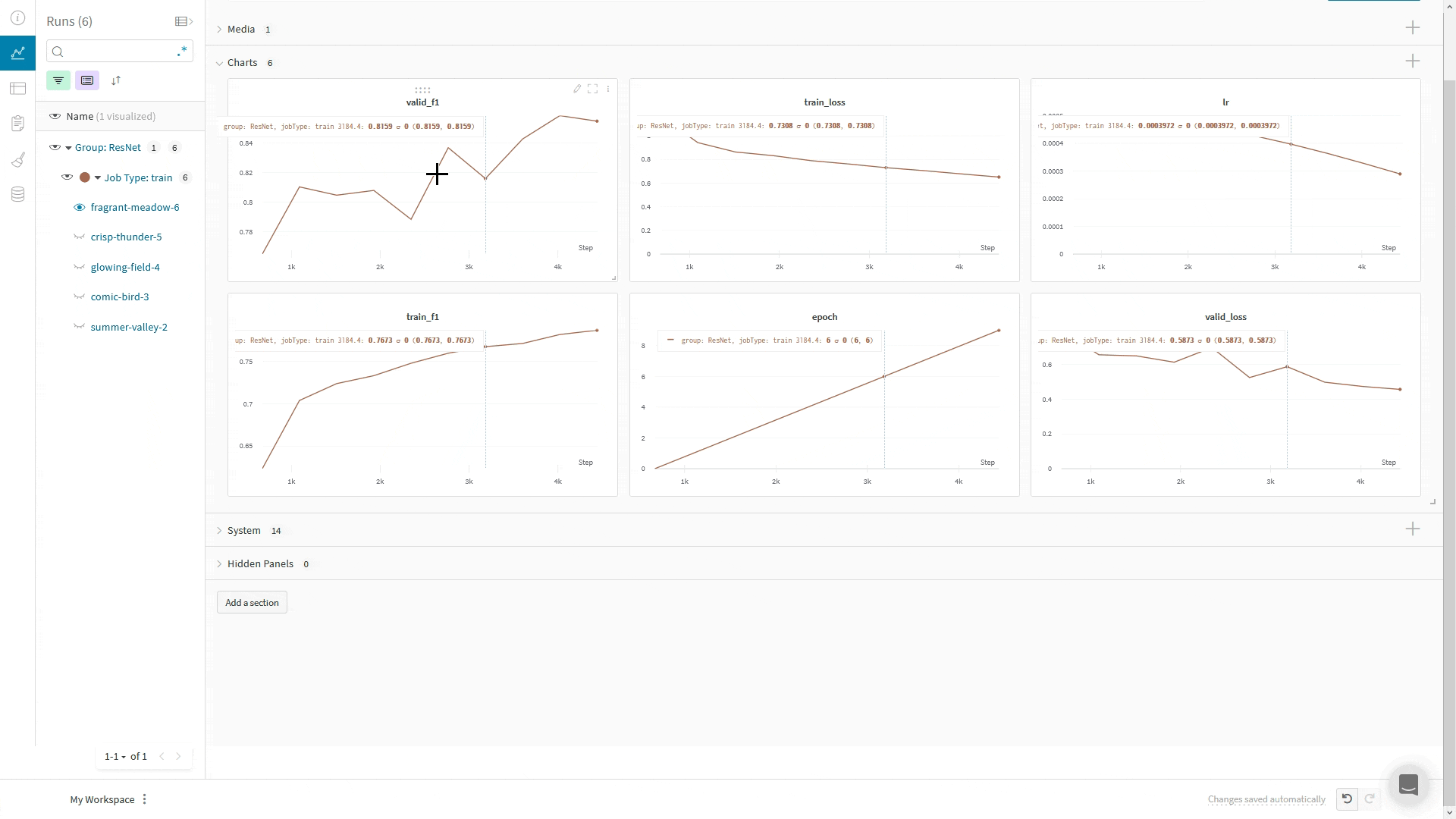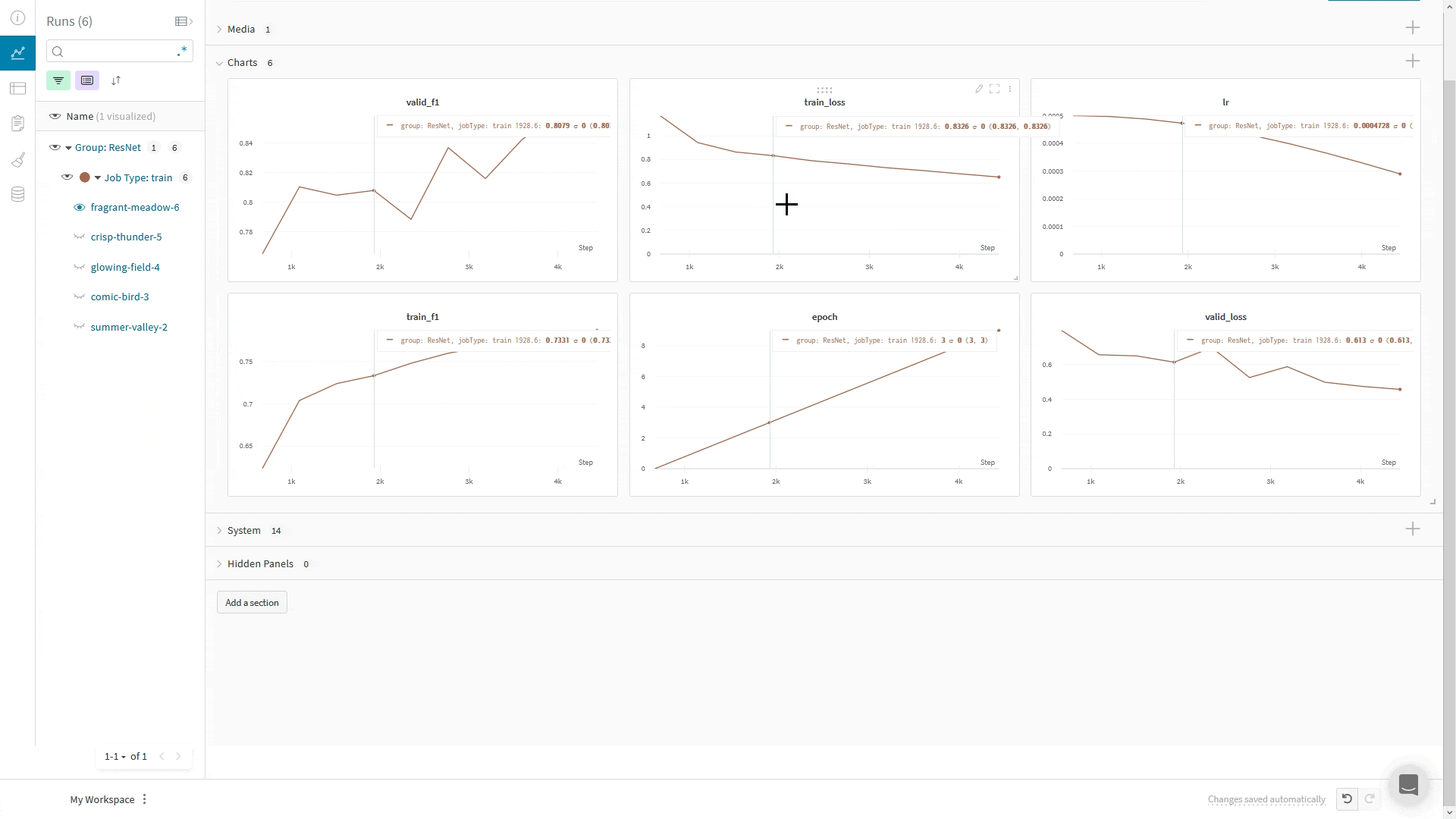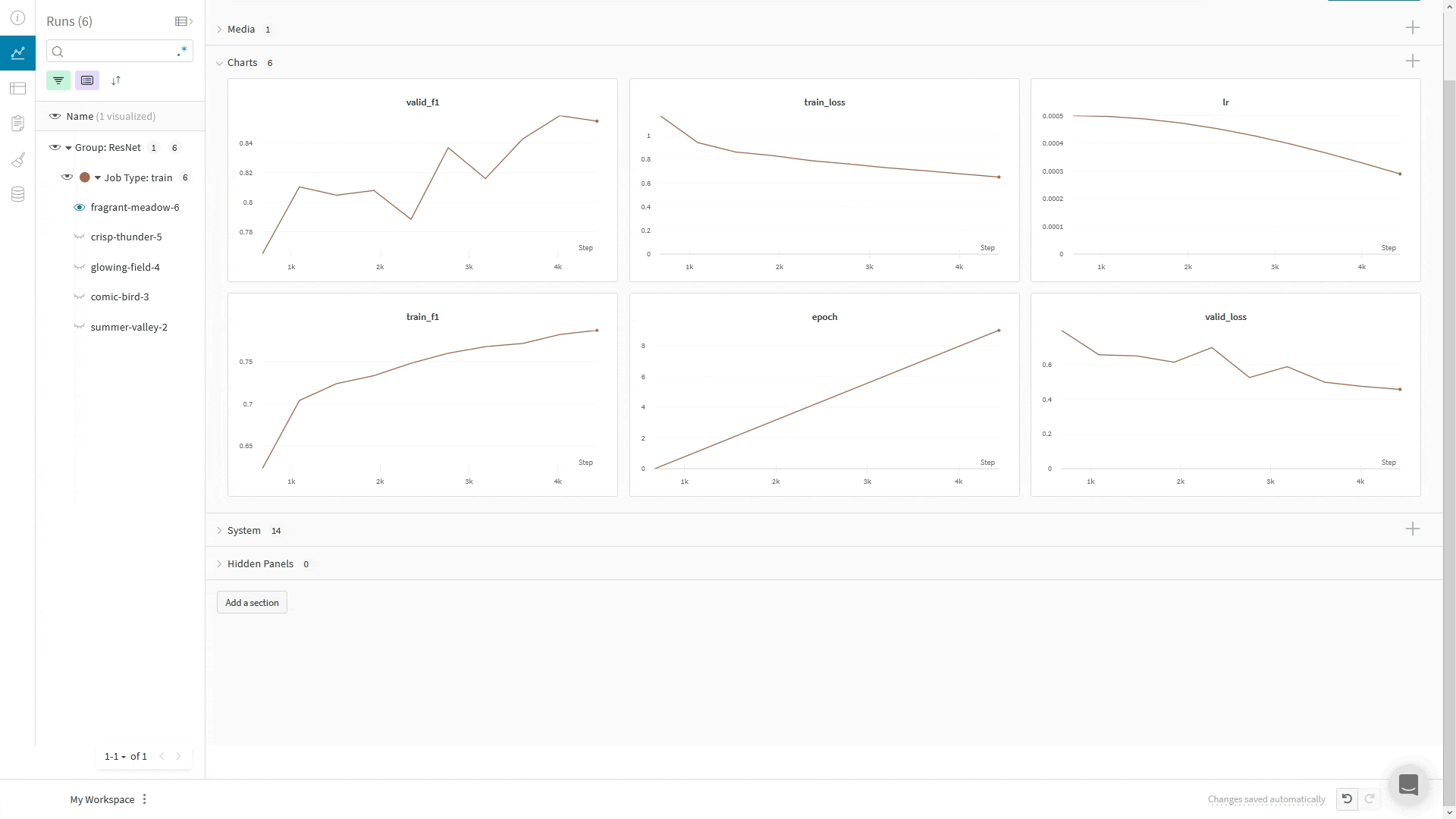
Sign up and create an API key
An API key authenticates your machine to W&B. You can generate an API key from your user profile.For a more streamlined approach, go to User Settings and create an API key. Copy the API key immediately and save it in a secure location such as a password manager.
- Click your user profile icon in the upper right corner.
- Select User Settings, then scroll to the API Keys section.
Install the wandb library and log in
To install the wandb library locally and log in:
- Command Line
- Python
- Python notebook
-
Set the
WANDB_API_KEYenvironment variable to your API key. Replace values enclosed in<>with your own: -
Install the
wandblibrary and log in.
Use PyTorch Lightning’s WandbLogger
PyTorch Lightning has multiple WandbLogger classes to log metrics, model weights, and media. Choose the class that matches your training setup:
To integrate with Lightning, instantiate the WandbLogger and pass it to Lightning’s Trainer or Fabric.
- PyTorch Logger
- Fabric Logger
Common logger arguments
The following table lists common parameters forWandbLogger. Review the PyTorch Lightning documentation for details about all logger arguments.
Log your hyperparameters
Logging hyperparameters with W&B lets you compare runs and reproduce results. Use the method that matches your logger:- PyTorch Logger
- Fabric Logger
Log additional config parameters
To capture extra configuration values alongside your hyperparameters, update the run config directly:Log gradients, parameter histogram and model topology
Pass your model object towandb_logger.watch() to monitor your model’s gradients and parameters as you train. See the PyTorch Lightning WandbLogger documentation.
Log metrics
- PyTorch Logger
- Fabric Logger
To log your metrics to W&B when using the
WandbLogger, call self.log('my_metric_name', metric_value) within your LightningModule, such as in your training_step or validation_step methods.The following code snippet shows how to define your LightningModule to log your metrics and your LightningModule hyperparameters. This example uses the torchmetrics library to calculate your metrics.Log the min/max of a metric
Using W&B’sdefine_metric function, you can define whether your W&B summary metric displays the min, max, mean, or best value for that metric. If define_metric isn’t used, the last value logged appears in your summary metrics. For more information, see the customize logging axes guide.
To track the max validation accuracy in the W&B summary metric, call wandb.define_metric() only once, at the beginning of training:
- PyTorch Logger
- Fabric Logger
Checkpoint a model
Saving checkpoints as W&B artifacts gives you versioned model files you can retrieve later by run, alias, or version. To save model checkpoints as W&B Artifacts, use the LightningModelCheckpoint callback and set the log_model argument in the WandbLogger.
- PyTorch Logger
- Fabric Logger
latest and best aliases are set automatically to make it easier to retrieve a model checkpoint from a W&B Artifact:
- Through Logger
- Through wandb
- PyTorch Logger
- Fabric Logger
Log images, text, and more
TheWandbLogger has log_image, log_text, and log_table methods for logging media.
You can also call wandb.log() or trainer.logger.experiment.log() directly to log other media types such as Audio, Molecules, Point Clouds, and 3D Objects.
- Log Images
- Log Text
- Log Tables
WandbLogger. The following example logs a sample of validation images and predictions:
Use multiple GPUs with Lightning and W&B
When you run distributed training, the way you referencewandb.run across ranks can affect whether training proceeds or deadlocks. This section explains the requirements and shows a recommended pattern.
PyTorch Lightning supports multi-GPU through its DDP Interface. However, PyTorch Lightning’s design requires you to be careful about how you instantiate your GPUs.
Lightning requires each GPU (or rank) in your training loop to be instantiated in exactly the same way, with the same initial conditions. However, only the rank 0 process gets access to the wandb.run object. For non-zero rank processes, wandb.run = None. This can cause your non-zero processes to fail. Such a situation can put you in a deadlock because the rank 0 process waits for the non-zero rank processes to join, which have already crashed.
For this reason, be careful about how you set up your training code. The recommended approach is to make your code independent of the wandb.run object.
Examples
For an end-to-end walkthrough, you can follow along in a video tutorial with a Colab notebook.Frequently asked questions
How does W&B integrate with Lightning?
The core integration is based on the Lightningloggers API, which lets you write much of your logging code in a framework-independent way. Logger instances are passed to the Lightning Trainer and are triggered based on that API’s rich hook-and-callback system. This keeps your research code well separated from engineering and logging code.
What does the integration log without any additional code?
W&B saves your model checkpoints, where you can view them or download them for use in future runs. W&B also captures system metrics, like GPU usage and network I/O. It captures environment information, like hardware and OS information. It captures code state, including Git commit and diff patch, notebook contents, and session history. It also captures anything printed to standard out.What if I need to use wandb.run in my training setup?
You need to expand the scope of the variable you need to access yourself. In other words, make sure that the initial conditions are the same on all processes.
os.environ["WANDB_DIR"] to set up the model checkpoints directory. This way, any non-zero rank process can access wandb.run.dir.