OpenAI Fine-Tuning
With Weights & Biases you can log your OpenAI GPT-3.5 or GPT-4 model's fine-tuning metrics and configuration to Weights & Biases to analyse and understand the performance of your newly fine-tuned models and share the results with your colleagues. You can check out the models that can be fine-tuned here.
The Weights and Biases fine-tuning integration works with openai >= 1.0. Please install the latest version of openai by doing pip install -U openai.
Sync your OpenAI Fine-Tuning Results in 2 Lines
If you use OpenAI's API to fine-tune OpenAI models, you can now use the W&B integration to track experiments, models, and datasets in your central dashboard.
from wandb.integration.openai.fine_tuning import WandbLogger
# Finetuning logic
WandbLogger.sync(fine_tune_job_id=FINETUNE_JOB_ID)
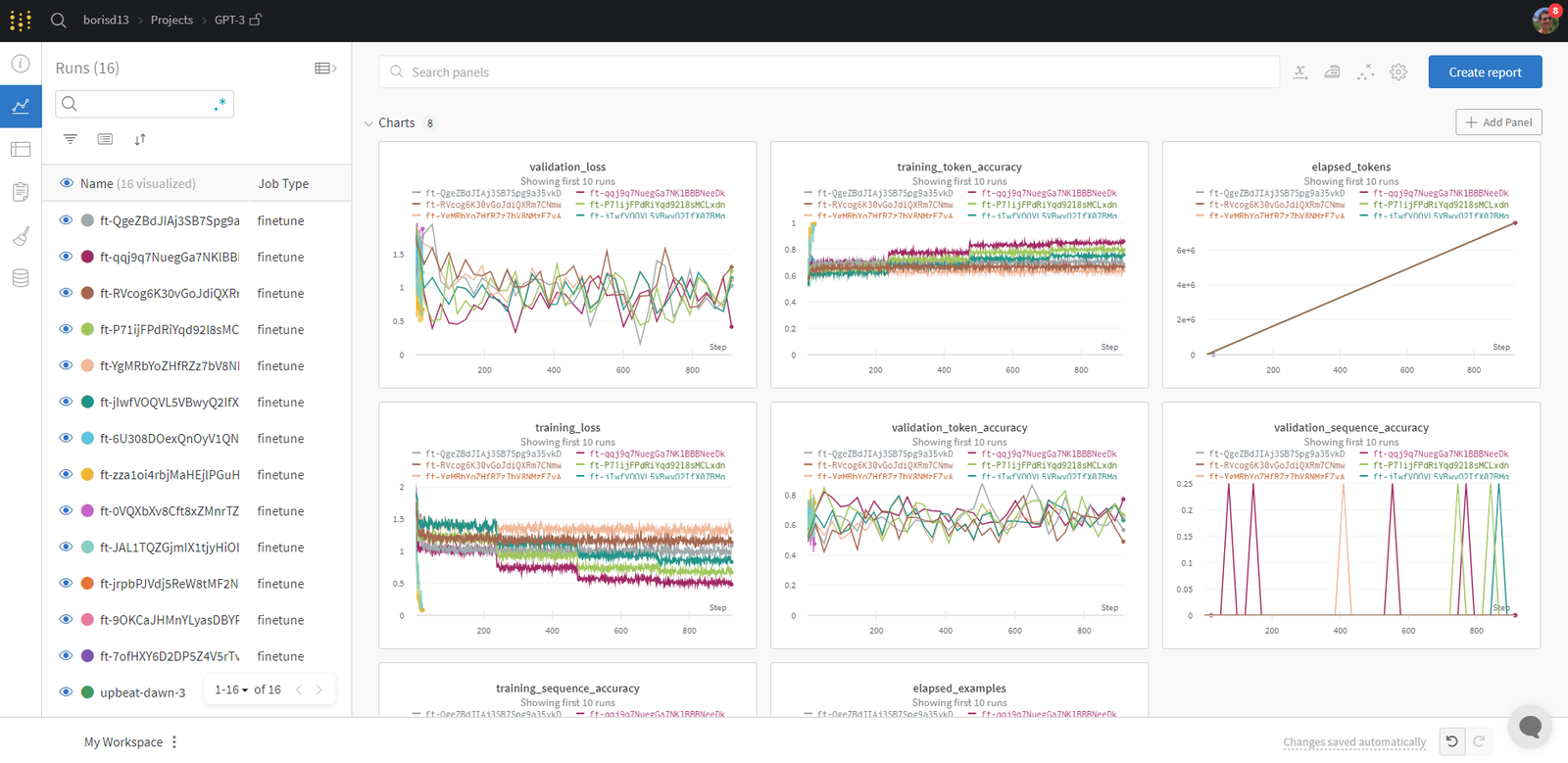
Check out interactive examples
Sync your fine-tunes with few lines of code
Make sure you are using latest version of openai and wandb.
pip install --upgrade openai wandb
Then sync your results from your script
from wandb.integration.openai.fine_tuning import WandbLogger
# one line command
WandbLogger.sync()
# passing optional parameters
WandbLogger.sync(
fine_tune_job_id=None,
num_fine_tunes=None,
project="OpenAI-Fine-Tune",
entity=None,
overwrite=False,
model_artifact_name="model-metadata",
model_artifact_type="model",
**kwargs_wandb_init
)
Reference
| Argument | Description |
|---|---|
| fine_tune_job_id | This is the OpenAI Fine-Tune ID which you get when you create your fine-tune job using client.fine_tuning.jobs.create. If this argument is None (default), all the OpenAI fine-tune jobs that haven't already been synced will be synced to W&B. |
| openai_client | Pass an initialized OpenAI client to sync. If no client is provided, one is initialized by the logger itself. By default it is None. |
| num_fine_tunes | If no ID is provided, then all the unsynced fine-tunes will be logged to W&B. This argument allows you to select the number of recent fine-tunes to sync. If num_fine_tunes is 5, it selects the 5 most recent fine-tunes. |
| project | Weights and Biases project name where your fine-tune metrics, models, data, etc. will be logged. By default, the project name is "OpenAI-Fine-Tune." |
| entity | Weights & Biases Username or team name where you're sending runs. By default, your default entity is used, which is usually your username. |
| overwrite | Forces logging and overwrite existing wandb run of the same fine-tune job. By default this is False. |
| wait_for_job_success | Once an OpenAI fine-tuning job is started it usually takes a bit of time. To ensure that your metrics are logged to W&B as soon as the fine-tune job is finished, this setting will check every 60 seconds for the status of the fine-tune job to change to "succeeded". Once the fine-tune job is detected as being successful, the metrics will be synced automatically to W&B. Set to True by default. |
| model_artifact_name | The name of the model artifact that is logged. Defaults to "model-metadata". |
| model_artifact_type | The type of the model artifact that is logged. Defaults to "model". |
| **kwargs_wandb_init | Aany additional argument passed directly to wandb.init() |
Dataset Versioning and Visualization
Versioning
The training and validation data that you upload to OpenAI for fine-tuning are automatically logged as W&B Artifacts for easier version control. Below is an view of the training file in Artifacts. Here you can see the W&B run that logged this file, when it was logged, what version of the dataset this is, the metadata, and DAG lineage from the training data to the trained model.
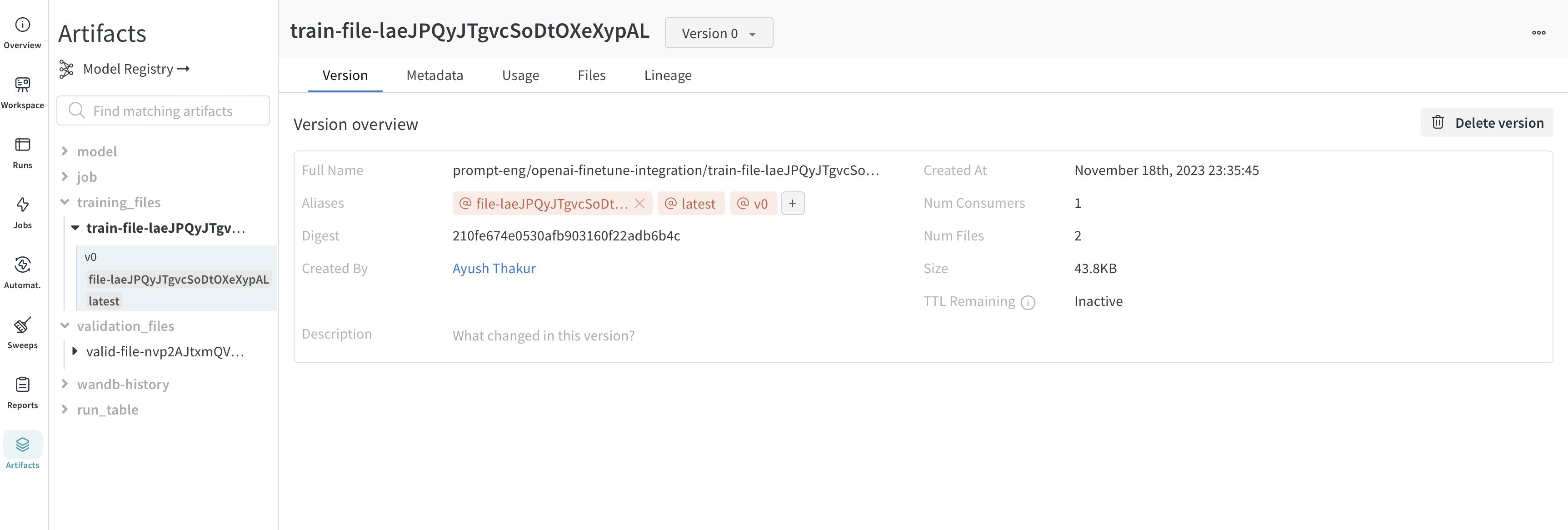
Visualization
The datasets are also visualized as W&B Tables which allows you to explore, search and interact with the dataset. Check out the training samples visualized using W&B Tables below.

The fine-tuned model and model versioning
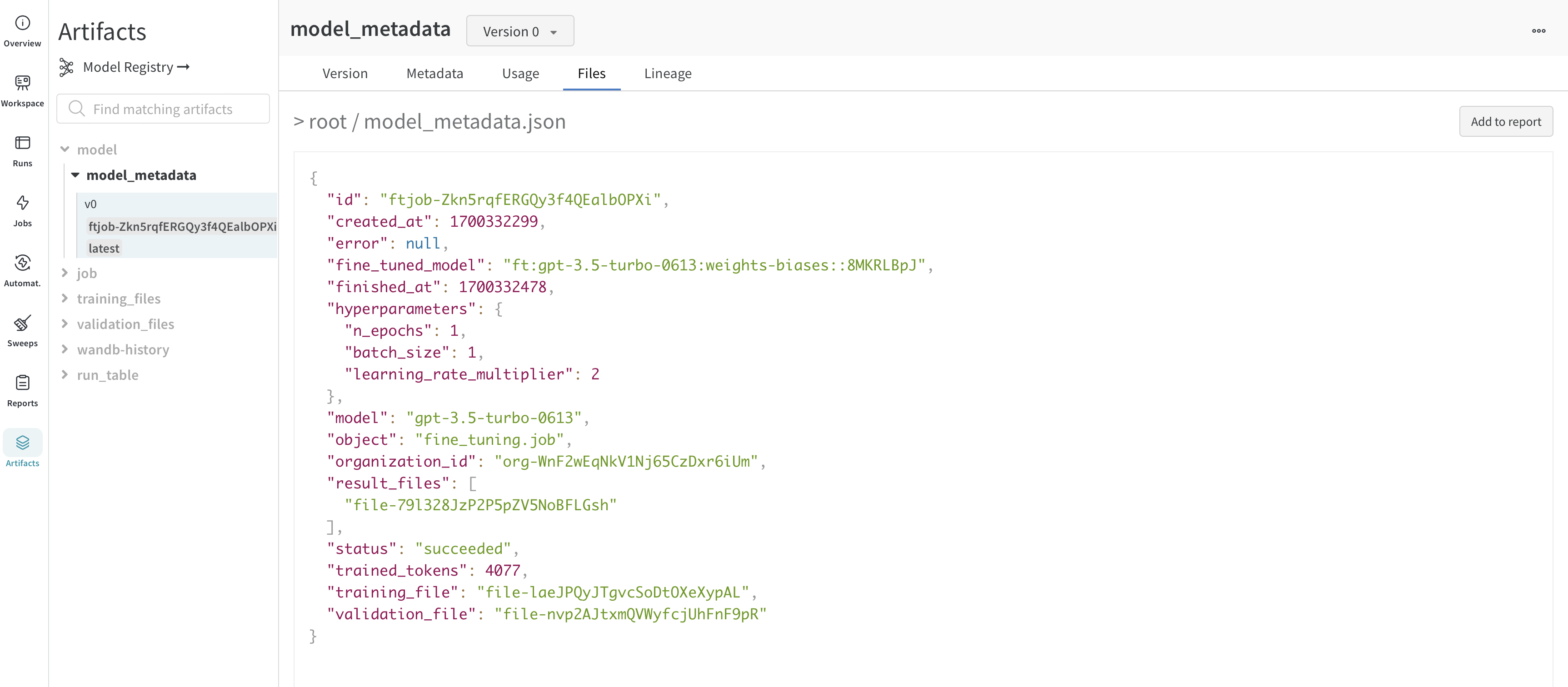
OpenAI gives you an id of the fine-tuned model. Since we don't have access to the model weights, the WandbLogger creates a model_metadata.json file with all the details (hyperparameters, data file ids, etc.) of the model along with the `fine_tuned_model`` id and is logged as a W&B Artifact.
This model (metadata) artifact can further be linked to a model in the W&B Model Registry and even paired with W&B Launch.
Frequently Asked Questions
How do I share my fine-tune results with my team in W&B?
Log your fine-tune jobs to your team account with:
WandbLogger.sync(entity="YOUR_TEAM_NAME")
How can I organize my runs?
Your W&B runs are automatically organized and can be filtered/sorted based on any configuration parameter such as job type, base model, learning rate, training filename and any other hyper-parameter.
In addition, you can rename your runs, add notes or create tags to group them.
Once you’re satisfied, you can save your workspace and use it to create report, importing data from your runs and saved artifacts (training/validation files).
How can I access my fine-tuned model?
Fine-tuned model ID is logged to W&B as artifacts (model_metadata.json) as well config.
import wandb
ft_artifact = wandb.run.use_artifact("ENTITY/PROJECT/model_metadata:VERSION")
artifact_dir = artifact.download()
where VERSION is either:
- a version number such as
v2 - the fine-tune id such as
ft-xxxxxxxxx - an alias added automatically such as
latestor manually
You can then access fine_tuned_model id by reading the downloaded model_metadata.json file.
What if a fine-tune was not synced successfully?
If a fine-tune was not logged to W&B successfully, you can use the overwrite=True and pass the fine-tune job id:
WandbLogger.sync(
fine_tune_job_id="FINE_TUNE_JOB_ID",
overwrite=True,
)
Can I track my datasets and models with W&B?
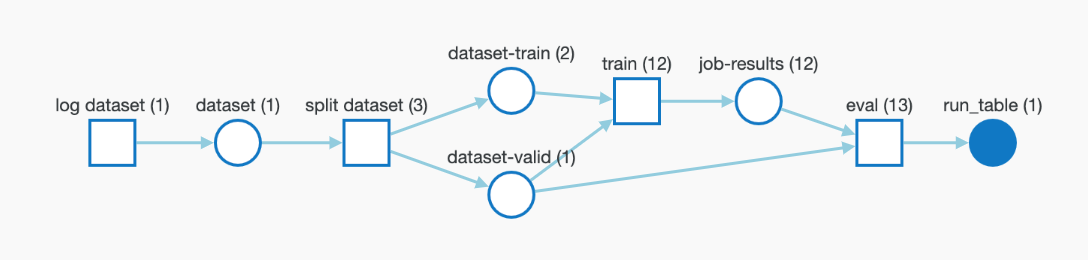
The training and validation data are logged automatically to W&B as artifacts. The metadata including the ID for the fine-tuned model is also logged as artifacts.
You can always control the pipeline using low level wandb APIs like wandb.Artifact, wandb.log, etc. This will allow complete traceability of your data and models.
Resources
- OpenAI Fine-tuning Documentation is very thorough and contains many useful tips
- Demo Colab
- Report - OpenAI Fine-Tuning Exploration & Tips